







概述
CheckPoint主要的作用是将缓冲池中的脏页刷新到磁盘,同时解决了以下三个问题:
- 缩短数据库的恢复时间;
当数据库发生宕机时,不需要重做所有的日志,只需要对CheckPoint之后的重做日志进行恢复,从而大大缩短恢复的时间。
- 缓冲池不够用时,将脏页刷新到磁盘;
当缓冲池不够用时,根据LRU算法删除最近最少使用的页,如果该页为脏页,那么会强制执行CheckPoint,将脏页刷新到磁盘。
- 重做日志不够用时,刷新脏页;
重做日志空间是循环使用的,并不能无限增大。当重做日志中的脏页都被刷新到磁盘时,数据库宕机时恢复数据则不需要这部分重做日志。当这部分重做日志没有被刷新到磁盘,则需要强制执行CheckPoint,将重做日志对应的脏页刷新到磁盘。
CheckPoint工作详解
在InnoDB存储引擎内部有两种CheckPoint方式,分别是Sharp CheckPoint、Fuzzy CheckPoint,他们的区别在于每次刷新磁盘页数、每次取脏页的位置有,以及触发CheckPoint时间不同。具体细节往下看。
Sharp CheckPoint
当数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,参数配置:innodb_fast-shutdown=1。
Fuzzy CheckPoint
如果在数据库运行时使用sharp checkpoint,那么对数据库的可用性影响会很大,所以在InnoDB内部会使用Fuzzy CheckPoint进行一部分脏页的刷新。
执行Fuzzy CheckPoint存在以下四种场景。
Master Thread CheckPoint
在Master Thread中会执行CheckPoint,以每秒或每十秒的速度将缓存池脏页列表中一定比例的脏页刷新回磁盘。这个过程是异步的,不会堵塞用户查询线程。
FLUSH_LRU_LIST CheckPoint
如果脏页列表没有100个可用空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除,如果这些页中有脏页,那么会执行CheckPoint。
Async/Sync Flush CheckPoint
当重做日志不可用时会强制将一些脏页刷新回磁盘,此时脏页是从脏页列表(Flush List)中选取的。
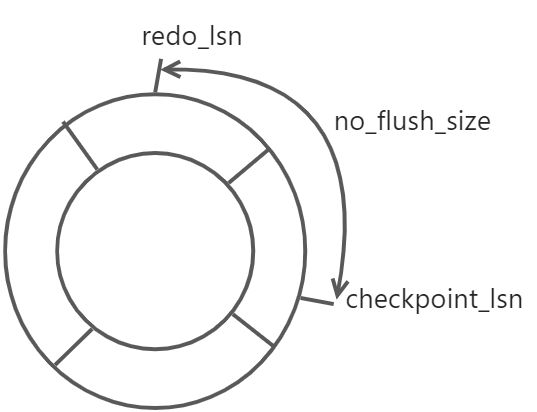
如图最新写入的重做日志位置标记redo_lsn,刷新回磁盘最新页的位置标记checkpoint_lsn。redo_lsn和checkpoint_lsn之间是未刷新到磁盘的重做日志,no_flush_size称为未刷新磁盘重做日志容量。
- 当no_flush_size<整个重做日志容量的75%时,不需要刷新任何脏页到磁盘;
- 当 整个重做日志容量的75%<no_flush_size<整个重做日志容量的90%时触发Async Flush(从脏页列表中刷新足够的脏页回磁盘,满足no_flush_size<整个重做日志容量的75%条件)
- no_flush_size>整个重做日志容量的90%时,会进行Sync Flush操作(从脏页列表中刷新足够的脏页回磁盘,满足no_flush_size<整个重做日志容量的75%条件),这种情况很少出现,出现原因一般为设置的重做日志文件大小太小。
说明:Async Flush与Sync Flush区别在于,Async Flush会堵塞发现问题的用户查询线程,Sync Flush会堵塞所有的用户查询线程。从MySQL5.6版本之后这部分刷新操作放到了单独的Page Cleaner Thread中,所以不会堵塞用户查询线程。
Dirty Page too much CheckPoint
如果脏页数量太多,会触发执行CheckPoint,目的时保证缓冲池中有足够的可用页。
可以通过innodb_max_dirty_pages_pct参数配置,值为75的含义是,当缓冲池中脏页的数量占据75%时,强制执行CheckPoint,刷新一部分脏页到磁盘。















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









