




code:GitHub - TRAILab/CaDDN: Categorical Depth Distribution Network for Monocular 3D Object Detection (CVPR 2021 Oral) https://github.com/TRAILab/CaDDN精度对比:KITTI Cars Moderate Benchmark (Monocular 3D Object Detection) | Papers With Code
https://github.com/TRAILab/CaDDN精度对比:KITTI Cars Moderate Benchmark (Monocular 3D Object Detection) | Papers With Code
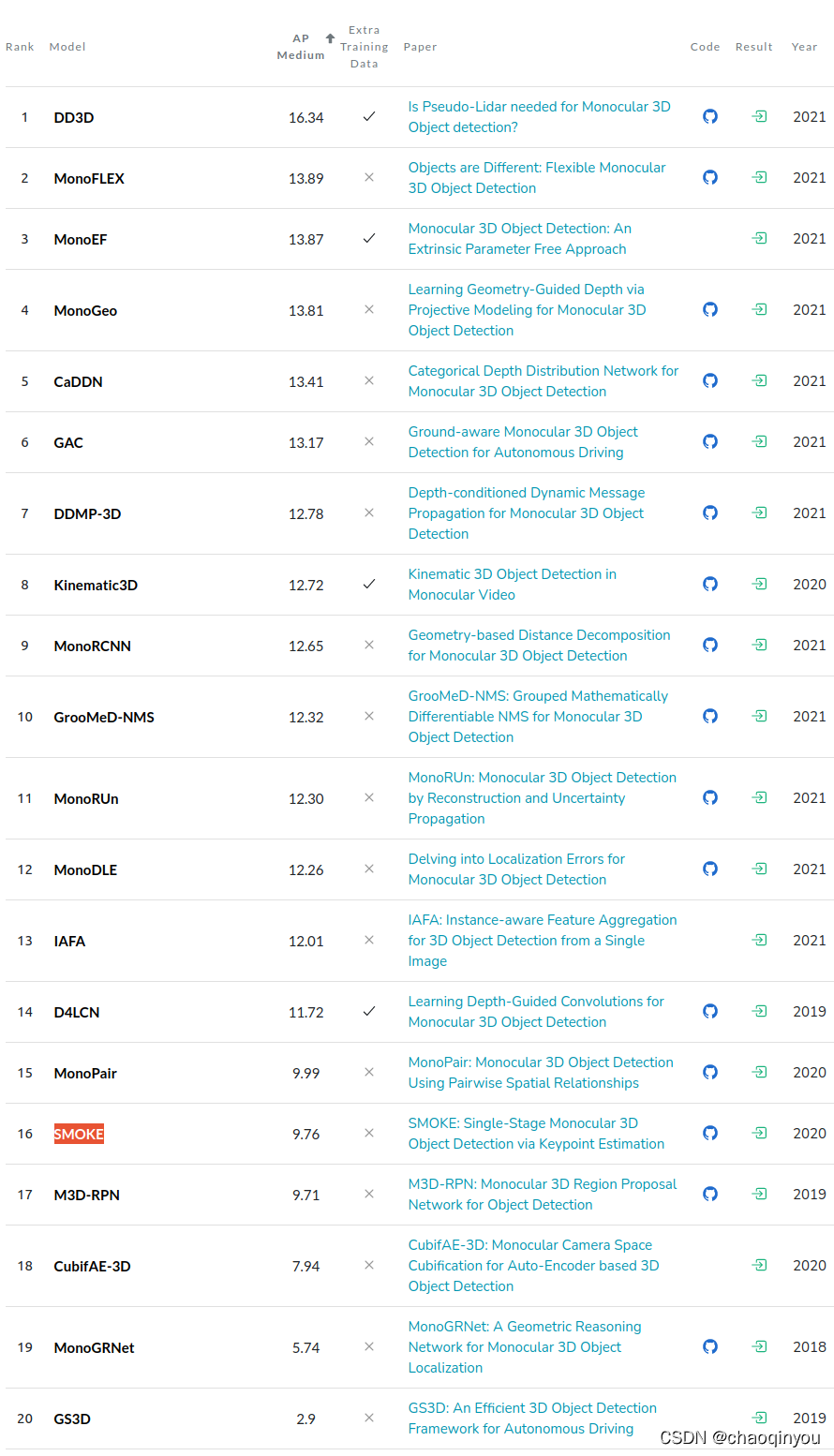
主要观点/贡献:
1. pseudo lidar lidar系列的方法, 直接用预测出来的伪点云, 可能会有over confident的问题,尤其对远距离的情形特别明显;
2. 直接把feature投影到3D空间,在预测深度和3D框的方法,存在特征混淆(feature smearing)的问题,检测结果也不好;
3. 因此, 提出了CaDDN: 先预测置信度分布,再把feature投影到3D,再做检测,提高了检测的准确性;
实现:
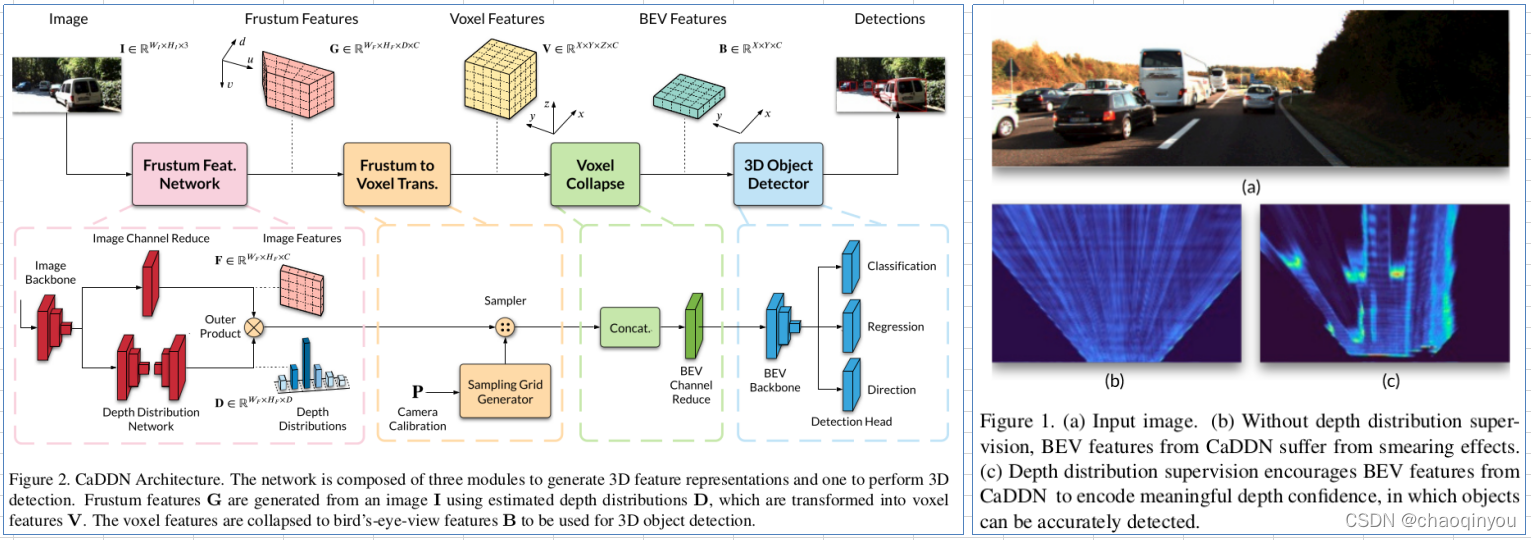
1. 产生voxel feature: a) 用depth distribution把front view的features投影成为frustum features(左下图) -》 b) 用空间线性插值(trilinear interpolation)把frustum features 差值为voxel features(右下图);
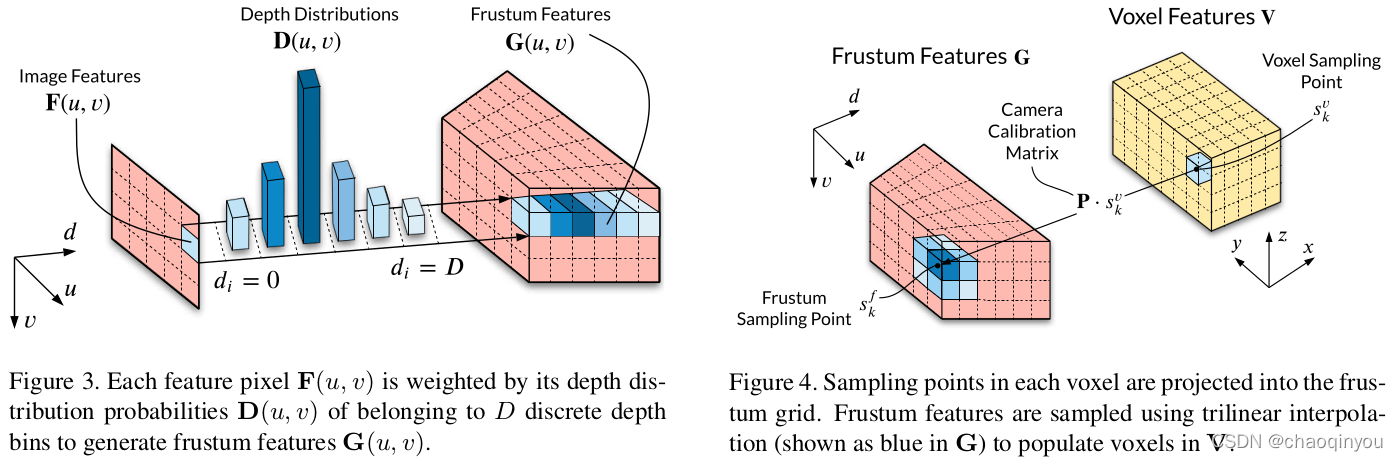
2. 按照类似point pillars的方式进行3D目标检测
消融实验:
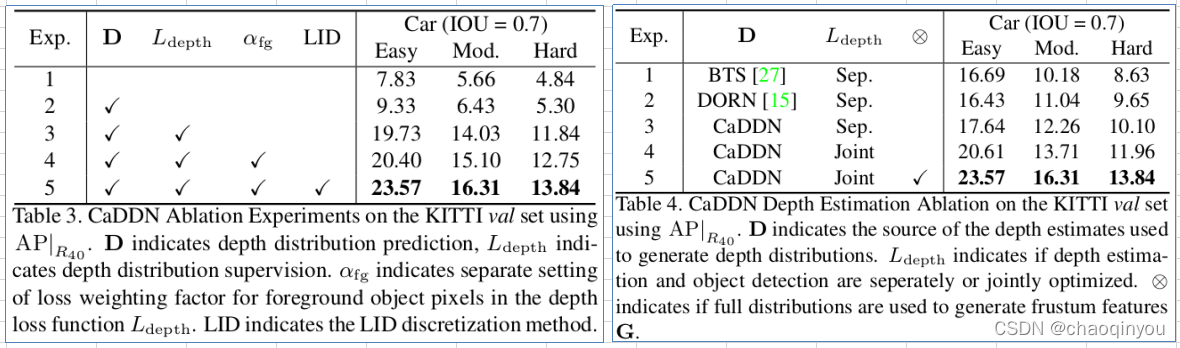
对精度有较大提高的地方:
joint depth supervision with 3d-object detection;
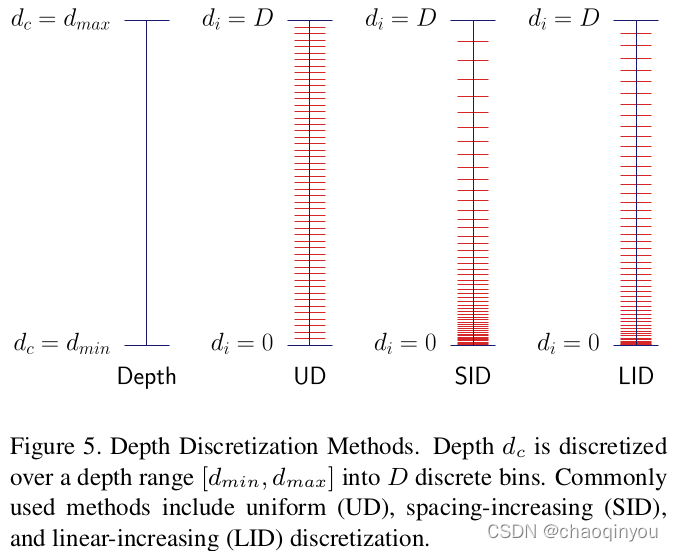
LID;
use full distribution to generate frustum features;
重要参考文献:
1. Center3d: Center-based monocular 3d object detection with joint depth understanding

















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









