






Early Convolutions使得Transformers表现更好
Tete Xiao 1 , 2 Mannat Singh 1 Eric Mintun 1 Trevor Darrell 2 Piotr Dollár 1 ∗ Ross Girshick 1 ∗ 1 Facebook AI Research (FAIR) 2 UC Berkeley
摘要
Vision transformer(ViT)模型表现出不合标准的优化能力。特别是,他们对优化器(AdamW vs.SGD)、优化器超参数和训练计划长度的选择非常敏感。相比之下,现代卷积神经网络更容易优化。为什么会这样?在这项工作中,我们推测问题在于ViT模型的修补干,它是通过对输入图像应用跨步p×p卷积(默认情况下p=16)来实现的。这种大内核加上大跨距卷积与神经网络中卷积层的典型设计选择背道而驰。为了测试这种非典型的设计选择是否会导致问题,我们分析了ViT模型的优化行为,并将其与原来的patchify干进行了比较,而与简单的对应模型进行了比较,我们将ViT干替换为少量的堆叠跨步2个3×3卷积。虽然两种ViT设计中的绝大多数计算是相同的,但我们发现,早期视觉处理中的这一微小变化导致训练行为在对优化设置的敏感性以及最终模型精度方面明显不同。
在ViT中使用卷积干显著提高了优化稳定性,也提高了峰值表现(通过∼ ImageNet-1k上1-2%的顶级精度),同时保持触发器和运行时。在模型复杂性(从1G到36G触发器)和数据集规模(从ImageNet-1k到ImageNet-21k)的广泛范围内都可以观察到改进。这些发现导致我们建议在这种情况下,使用标准的、轻型的卷积茎作为ViT模型的一种结构选择,与原来的ViT模型设计相比,这是一种更稳健的结构选择。
1引言
视觉transformer(ViT)模型【13】提供了卷积神经网络(CNN)的另一种设计范式【24】。ViTs将进化中固有的对局部处理的诱导性bias替换为多头自我注意的全局处理[43]。希望这种设计有可能改善视觉任务的表现,类似于自然语言处理中观察到的趋势【11】。在研究这一推测时,研究人员面临着ViT和CNN之间的另一个意想不到的差异:ViT模型表现出不合标准的优化能力。
VIT对优化器的选择【41】(AdamW【27】vs.SGD)、数据集特定学习超参数的选择【13,41】、训练计划长度、网络深度【42】等非常敏感。
这些问题使得以前的训练方法和直觉无效,阻碍了研究。
相比之下,卷积神经网络非常容易优化,而且非常健壮。多年来,基于SGD、基础数据扩充和标准超参数值的简单训练配方已被广泛使用【19】。为什么ViT和CNN模型之间存在这种差异?在本文中,我们假设问题主要在于ViT执行的早期视觉处理。ViT将输入图像“拼接”为p×p非重叠拼接,以形成transformer编码器的输入集。此修补茎实现为跨步-p p×p卷积,默认值为p=16。这种大内核加上大跨距卷积与CNN中使用的典型设计选择背道而驰,在CNN中,最佳实践已经收敛到一个小跨距堆栈,两个3×3内核作为网络的主干(例如,[30,36,39])。
为了验证这一假设,我们将ViT的补丁茎替换为标准的卷曲茎,使ViT的早期视觉处理发生最小的改变∼ 5个卷积,见图1。
为了补偿触发器中的少量添加,我们删除了一个transformer块以保持触发器和运行时中的奇偶校验。我们观察到,尽管两种ViT设计中的绝大多数计算是相同的,但早期视觉处理中的这一微小变化导致训练行为在对优化设置的敏感性以及最终的模型精度方面明显不同。
在广泛的实验中,我们表明,用更标准的卷积干取代ViT修补干(i)可以使ViT更快地收敛(§5.1),(ii)首次允许使用AdamW或SGD,而不会显著降低准确性(§5.2),(iii)使ViT的稳定性w.r.t.学习率和重量衰减更接近现代CNN(§5.3),和(iv)改进了ImageNet[10]的top-1错误∼ 1-2个百分点(§6)。我们在广泛的模型复杂性(从1G触发器到36G触发器)和数据集规模(ImageNet-1k到ImageNet-21k)中不断观察到这些改进。
这些结果表明,在通常研究的情况下,向ViTs中注入一些卷积电感bias是有益的。我们没有观察到证据表明,早期层中的硬位置约束会阻碍网络的代表能力,这可能令人担忧[9]。事实上,我们观察到了相反的情况,因为使用卷积干时,即使使用更大比例的模型和更大比例的数据,ImageNet结果也会得到改善。此外,在仔细控制的比较下,我们发现VIT只有在配备卷曲茎时才能超过最先进的CNN(§6)。
我们推测,将ViT中的卷积限制在早期视觉处理中可能是一个至关重要的设计选择,它可以在(硬)感应偏差和transformer块的表示学习能力之间取得平衡。与文献[13]中提出的“混合ViT”相比,有证据表明,混合ViT使用了40个卷积层(大部分是ResNet-50),与默认ViT相比没有任何改进。
这一观点与[9]的研究结果产生了共鸣,他们观察到早期的transformer区块比后期区块更喜欢学习更多的局部注意力模式。最后,我们注意到,探索CNN/ViT混合模型的设计并不是这项工作的目标;相反,我们证明了简单地将最小卷积干与ViT结合使用就足以显著改变其优化行为。
综上所述,本文中的研究结果导致我们建议在分析的数据集规模和模型复杂度谱中使用标准、轻量级的卷积干,作为与原始ViT模型设计相比更稳健、性能更高的架构选择。
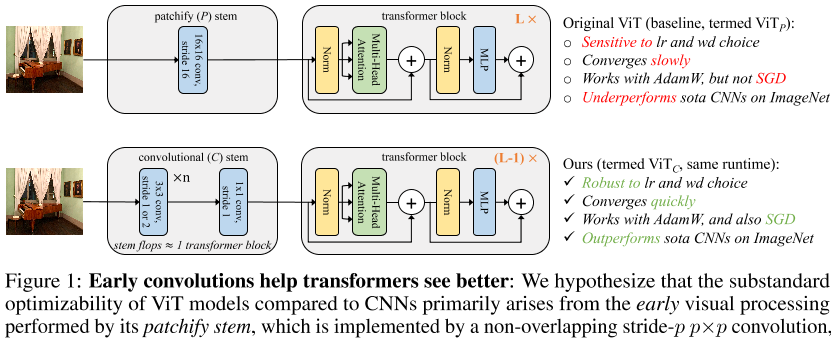
图1:早期卷积有助于transformers更好地观察:我们假设,与CNN相比,ViT模型的非标准优化能力主要源于其补丁干执行的早期视觉处理,其由非重叠的步幅p p×p卷积实现,默认情况下p=16。我们将ViT中的补片茎替换为标准卷曲茎∼ 5个卷积,其复杂性与单个transformer块大致相同。我们将transformer块的数量减少了一个(即,L− 1对。L)保持触发器、参数和运行时的奇偶校验。我们将生成的模型称为ViT C,将原始ViT称为ViT P。这两个模型执行的绝大多数计算是相同的,但令人惊讶的是,我们观察到ViT C(i)收敛速度更快,(ii)首次允许使用AdamW或SGD,而不存在显著的精度下降,(iii)显示出学习速度和权重衰减选择的更大稳定性,(iv)改进了ImageNet top-1错误,使ViT C优于最先进的CNN,而ViT P则不然。
2相关工作
卷积神经网络(CNNs)。AlexNet【23】CNN【15,24】在ImageNet分类【10】方面的突破性表现改变了识别领域,导致了更高性能架构的发展,例如。,[19、36、37、48]和可扩展的训练方法[16、21]。这些体系结构现在是对象检测(例如,[34])、实例分割(例如,[18])和语义分割(例如,[26])中的核心组件。CNN通常使用随机梯度下降(SGD)进行训练的,并且被广泛认为易于优化。
视觉模型中的自我注意。Transformers(Transformers)[43]通过支持可扩展的训练,正在彻底改变自然语言处理。Transformers使用多头自我注意,它执行全局信息处理,严格来说比卷积更通用[6]。Wang等人。【46】表明(单头)自我关注是一种非局部手段,将其整合到ResNet中可以改善多项任务。Ramachandran等人。[32]通过独立的视觉自我关注网络进一步探索这一方向。他们报告了设计基于注意力的网络stem的困难,并提出了一种避免卷积的定制解决方案。相反,我们展示了卷积干的好处。Zhao等人。[53]探索一组更广泛的具有硬编码位置约束的自我注意操作,更类似于标准CNN。
Vision transformer(ViT)。Dosovitskiy等人。[13]将transformer编码器应用于图像分类,只需进行最小程度的视觉特定修改。作为输入token嵌入的对应项,它们将输入图像划分为,例如。,16×16像素,非重叠面片,并将其线性投影到编码器的输入尺寸。他们报告称,在ImageNet-1k上进行训练时,效果不佳,但在使用大规模预训练数据时,他们展示了最先进的迁移学习。VIT对训练配方的许多细节都很敏感,例如。,与SGD相比,AdamW【27】使它们受益匪浅,需要仔细的学习速度和权重衰减选择。通常认为,与CNN相比,VIT难以优化(例如,见[13、41、42])。Chen等人提出了进一步的挑战证据。[4]他们报告了自监督学习中ViT优化的不稳定性(与CNN不同),并发现在随机初始化时冻结补丁茎可以提高稳定性。
ViT改进。VIT正迅速引起人们的兴趣,部分原因是它们可能提供一个远离CNN的新方向。Touvron等人。[41]表明,随着更多的正则化和更强的数据处理,ViT模型仅在ImageNet-1k上就达到了具有竞争力的精度(参见[13])。随后,与我们自己的工作同时,我们还探索了许多其他ViT改进。主导主题包括多尺度网络【14、17、25、45、50】、深度增加【42】和位置优先【5、9、17、47、49】。
在[9]中,d’Ascoli等人。在初始化时使用卷积bias修改多头自我注意,并表明此先验改进了采样效率和ImageNet精度。与我们的工作产生共鸣,[5、17、47、49]提出了带有卷积茎的模型,但没有分析可优化性(我们的重点)。
讨论与ViT中局部先验的并行工作不同,我们的重点是研究在最小ViT修改下的可优化性,以便得出清晰的结论。我们的观点带来了几个新颖的观察结果:只添加∼ 5到stem的卷积,ViT可以用AdamW或SGD很好地优化(参见。所有以前的工作都使用AdamW以避免精度大幅下降[41]),它对学习率和权重衰减的特定选择变得不那么敏感,训练收敛更快。我们还观察到,ImageNet top-1精度在模型复杂度(1G到36G的浮点运算)和数据集规模(ImageNet-1k到ImageNet-21k)的广泛范围内持续提高。
这些结果表明,网络早期的(硬)卷积bias不会损害表征能力,如[9]中所推测的,并且在本研究范围内是有益的。
3 Vision Transformer架构
接下来,我们回顾《视觉transformers》,并描述我们工作中使用的卷积茎。
愿景transformer(ViT)。ViT首先将输入图像分割为不重叠的p×p面片,并使用学习的权重矩阵将每个面片线性投影到d维特征向量。典型的斑块大小为p=16,图像大小为224×224。产生的补丁嵌入(加上位置嵌入和学习的分类token嵌入)由标准transformer编码器(43,44)和分类头处理。使用通用网络命名法,我们将transformer阻塞之前的ViT部分称为网络的主干。ViT的茎是卷积的一种特殊情况(步长-p,p×p内核),但我们将其称为修补茎,并保留卷积茎的术语,用于具有多层重叠卷积(即步长小于内核大小)的更传统CNN设计的茎。
ViT P型号。之前的工作提出了各种尺寸的ViT模型,如ViT Tiny、ViT Small、ViT Base等。[ 13 , 41 ]. 为了便于与CNN进行比较,CNN通常标准化为1GF(GF)、2GF、4GF、8GF等。,我们修改了原始ViT模型,以获得这些复杂度的模型。详情见表1(左)。为了更容易与类似触发器的CNN进行比较,并避免主观的大小名称,我们根据它们的触发器引用模型,例如。,ViT P-4GF代替ViT Small。我们使用P下标表示这些模型使用了原始的补丁茎。
卷曲杆设计。我们采用了一种典型的极简卷积干设计,将3×3卷积叠加在一起【36】,然后在末端进行一次1×1卷积,以匹配transformer编码器的d维输入。这些茎使用重叠的跨步卷积将224×224的输入图像快速降采样为14×14,与标准patchify茎创建的输入数量相匹配。我们遵循一个简单的设计模式:所有3×3卷积要么有步长2,输出通道数加倍,要么有步长1,输出通道数保持不变。
我们强调,stem大约占相应模型的一个transformer块的计算量,因此,当使用卷积stem而不是修补stem时,我们可以通过移除一个transformer块来轻松控制触发器。我们的stem设计是特意选择的简单设计,我们强调它的设计不是为了最大限度地提高模型的准确性。
ViT C型号。为了形成具有卷积干的ViT模型,我们只需将修补干替换为对应的卷积干,并移除一个transformer块,以补偿卷积干的额外失败(见图1)。我们将具有卷曲茎的改良ViT称为ViT C。表1(右)给出了ViT cat各种复杂度的配置;相应的ViT P和ViT C模型在所有复杂度指标上都非常匹配,包括触发器和运行时。
卷曲茎细节。我们的卷积干设计分别对1GF、4GF和18GF模型使用四个、四个和六个3×3卷积。输出通道分别为[24、48、96、192]、[48、96、192、384]和[64、128、128、256、256、512]。所有3×3卷积之后是批次范数(BN)[21],然后是ReLU[29],而最终的1×1卷积则不是,以与最初的补丁茎一致。最终,匹配杆触发器和transformer块触发器会导致杆过大,因此ViT C-36GF使用与ViT C-18GF相同的杆。
ViT中的卷积。Dosovitskiy等人。[13]还介绍了一种“混合ViT”架构,该体系结构将修改后的ResNet[19](位ResNet[22])与transformer编码器混合。在他们的混合模型中,patchify干被部分BiT-ResNet-50替代,该BiT-ResNet-50终止于conv4级或扩展conv3级的输出。这些图像嵌入件取代了标准的patchify阀杆嵌入件。这部分BiT-ResNet-50杆很深,有40个卷积层。在这项工作中,我们探索了总共只有5到7个卷积的轻质卷积茎,而不是混合ViT使用的40个卷积茎。此外,我们强调,我们工作的目标不是探索混合ViT设计空间,而是研究简单地用符合标准CNN设计实践的最小卷积茎替换修补茎的优化效果。

表1:模型定义:左:我们的ViT P模型具有不同的复杂性,它使用原始的补丁茎,与原始ViT模型非常相似[13]。为了便于与CNN进行比较,我们修改了原始ViT Tiny、Small、Base、Large模型,分别获得1GF、4GF、18GF和36GF的模型。修改以蓝色表示,包括将1GF和4GF型号的MLP乘数从4×减少到3×以及将36GF模型的transformer块数量从24个减少到14个。右图:我们的ViT C模型在各种复杂度下使用卷积干。相对于相应的ViT P模型,唯一的额外修改是移除1个transformer块,以补偿卷积干的增加的触发器。我们展示了所有模型的复杂性度量(触发器、参数、激活和ImageNet-1k上的 epochs训练时间);相应的ViT P和ViT C模型在所有指标上都非常匹配。
4测量优化能力
文献中指出,ViT模型具有优化的挑战性,例如。,当在中型数据集(ImageNet-1k)[13]上进行训练的时,它们可能只能获得适度的表现,对数据扩充[41]和优化器选择[41]很敏感,并且在深入时可能表现不佳[42]。在实验过程中,我们根据经验观察到这些困难的普遍存在,并非正式地将这些优化特性统称为可优化性。
当超参数变化时,可优化性差的模型可能会产生非常不同的结果,这可能导致看似奇怪的观察结果,例如。,删除擦除数据增强[54]会导致[41]中ImageNet精度的灾难性下降。需要量化指标来衡量优化能力,以便进行更稳健的比较。在本节中,我们为此类比较奠定了基础;我们使用§5中的这些优化措施广泛测试了各种模型。
训练长度稳定性。长期计划的前期工程训练ViT模型,例如。,ImageNet上的300到400个 epochs是典型的(在极端情况下,[17]对1000个 epochs的模型进行训练),因为以前常见的100个 epochs时间表的结果要差得多(top-1精度降低2-4%,见§5.1)。
在ImageNet的上下文中,我们将400个时代的top-1精度定义为近似渐近结果,即。,更长时间的训练并不会有意义地提高top-1的准确性,我们将其与仅在50、100或200个时期内训练的的模型的准确性进行比较。我们将训练长度稳定性定义为与渐近精度的差距。直觉上,这是收敛速度的一个衡量标准。更快收敛的模型提供了明显的实际好处,尤其是在训练许多模型变体时。
优化器稳定性。之前的工作使用AdamW【27】从随机初始化优化ViT模型。
SGD的结果并不典型,我们只知道Touvron等人。[41]'∼ ImageNet top-1精度下降7%。相比之下,广泛使用的CNN(如RESNET)可以通过SGD或AdamW(见§5.2)进行同样好的优化,SGD(始终与动量一起)通常在实践中使用。SGD的实际好处是具有更少的超参数(例如,调整AdamW的β2可能很重要[3]),并且需要的优化器状态内存减少50%,这可以简化缩放。我们将优化器稳定性定义为AdamW和SGD之间的精度差距。与训练长度稳定性一样,我们使用优化器稳定性作为模型易于优化的代理。
超参数(lr、wd)稳定性。学习率(lr)和权重衰减(wd)是控制SGD和AdamW优化的最重要超参数之一。新模型和数据集通常需要搜索其最佳值,因为选择可能会显著影响结果。我们希望有一个模型和优化器,能够在广泛的学习率和权重衰减值范围内产生良好的结果。我们将通过比较不同lr和wd选择的训练的模型的误差分布函数(EDF)[30]来探索这种超参数稳定性。在此设置中,为了为模型创建EDF,我们随机采样lr和wd的值,并相应地对模型进行训练。与EDFs提供的估计一样,分布估计可以更完整地反映点估计无法揭示的模型特征[30,31]。我们将审查§5.3中的EDF。
表现峰值。每个模型的最大可能表现是以前文献中最常用的指标,通常在没有仔细控制训练细节的情况下提供,如数据扩充、正则化方法、 epochs数以及lr、wd调整。为了进行更稳健的比较,我们将表现峰值定义为使用性能最佳的优化器和经过节俭调整的lr和wd值(详见§6)在400个时代的模型的结果,同时为对训练有已知影响的所有其他变量确定合理的良好值。在这些精心控制的训练设置下,VIT和CNN的表现峰值结果见§6。
5稳定性试验
在本节中,我们测试了ViT模型与原始patchify(P)stem的稳定性。§3中定义的卷积(C)杆。作为参考,我们还对RegNetY(训练RegNetY[12,31])进行了培训,这是一种最先进的CNN,易于优化,可作为良好稳定性的参考点。
我们使用ImageNet-1k[10]的标准训练和验证集进行实验,并报告top-1错误。在【12】之后,对于所有结果,我们仔细控制训练设置,并使用一组最小的数据扩充,以产生强大的结果,详情见§5.4。在本节中,除非另有说明,否则对于每个模型,我们使用50个 epochs计划下的最优lr和wd(见附录)。
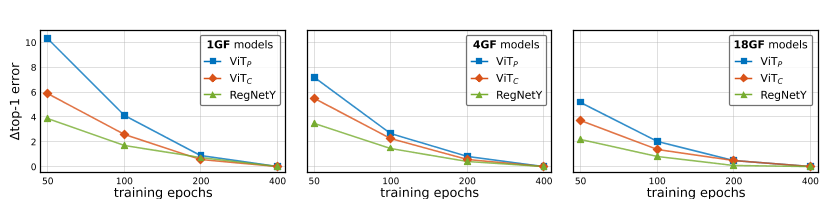
图2:训练长度稳定性:我们在ImageNet-1k上对9个模型进行了50到400个时代的训练,并绘制了∆ 每个的400 epochs结果的top-1错误。ViT C在整个模型复杂性谱中的收敛速度比ViT P快,有助于缩小与CNN(由RegNetY表示)的差距。
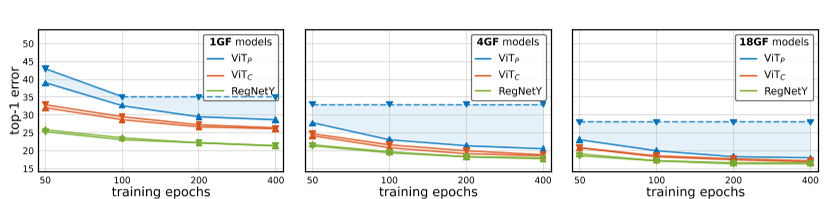
图3:优化器稳定性:我们使用AdamW(向上三角形N)和SGD(向下三角形H)对每个模型进行50到400个周期的训练。对于基线维生素P,SGD产生的结果明显比AdamW差。相比之下,ViT C和RegNetY模型在所有设置中的SGD和AdamW之间的差距要小得多。请注意,对于长计划,ViT P通常无法与SGD收敛(即,损失归NaN),在这种情况下,我们从同一模型的较短计划中复制最佳结果(并通过虚线显示结果)。
5.1训练长度稳定性
我们首先探讨网络在ImageNet-1k上收敛到其渐近误差的速度,即。,训练在许多时代都能达到最高的精确度。我们将渐近误差近似为模型误差,使用400个 epochs的时间表,基于观察从200到400的收益递减。我们考虑了24个ViT:{P,C}茎×{1,4,18}GF模型大小×{50,100,200,400}年代的实验网格。作为参考,我们也在{1,4,16}GF处对RegNetY进行训练。我们为每个模型使用最佳优化器选择(AdamW用于ViT模型,SGD用于RegNetY模型)。
后果图2显示了绝对误差增量(∆ top-1)介于50、100和200个 epochs计划和渐近表现之间(400个 epochs)。在模型复杂度谱中,ViT C的收敛速度比ViT P快,并且缩小了与CNN收敛速度的差距。
在最短的训练计划(50个 epochs)中,改进最为显著,例如:。,ViT P-1GF有10%的误差增量,而ViT C-1GF则将误差降低到6%左右。这为执行大量短期计划实验的应用程序打开了大门,例如神经架构搜索。
5.2优化器稳定性
接下来,我们将探讨AdamW和SGD如何优化具有两种杆类型的ViT模型。我们考虑以下48个ViT实验的网格:{P,C}茎×{1,4,18}GF大小×{50,100,200,400}时代×{AdamW,SGD}优化器。作为参考,我们还训练了24条RegNetY基线,每个复杂度区域、 epochs长度和优化器对应一条基线。
后果图3显示了结果。作为基线,当使用SGD或AdamW进行训练的时,RegNetY模型几乎没有显示差距(差异∼ 0.1-0.2%在噪声范围内)。另一方面,当在所有环境下使用SGD进行训练的时,ViT P车型都会大幅下降(对于较大车型和较长的训练计划,下降幅度高达10%)。通过卷积干,ViT C模型在所有训练时间表和模型复杂性中,SGD和AdamW之间的误差差距都小得多,包括在较大的模型和较长的时间表中,差距减小到0.2%以下。换句话说,RegNetY和ViT C都可以通过SGD或AdamW轻松地进行训练的,但ViT P不能。
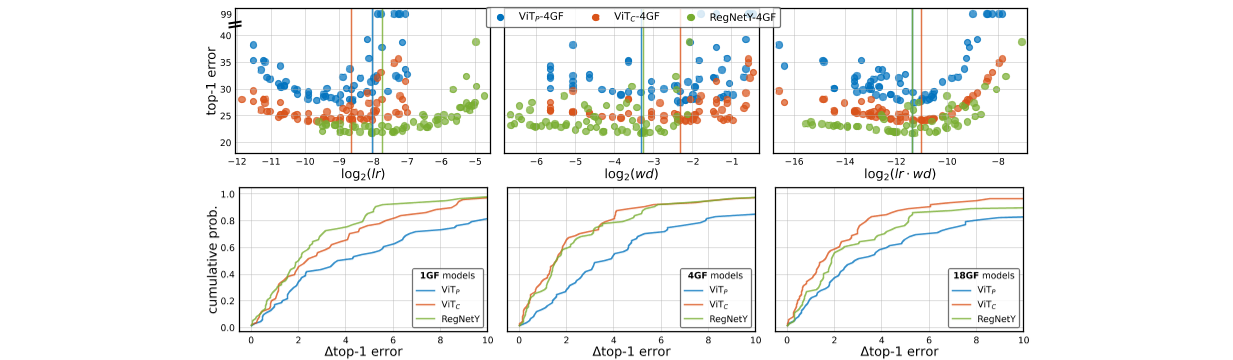
图4:AdamW(lr和wd)的超参数稳定性:对于每个模型,我们用随机lr和wd(在每个模型的最佳值周围的固定宽度间隔内)对模型的64个实例进行50个时期的训练。上图:三种4GF机型的lr、wd和lr·wd散点图。竖线表示每个模型的最佳lr、wd和lr·wd值。底部:对于每个模型,我们通过绘制误差的累积分布来生成误差的EDF∆ 前1个错误(∆ 每个模型的最佳误差)。EDF越陡,表明lr和wd变化的稳定性越好。在整个模型复杂度谱中,ViT C显著提高了基线ViT P的稳定性,与CNN模型(RegNetY)的稳定性相匹配,甚至优于后者。
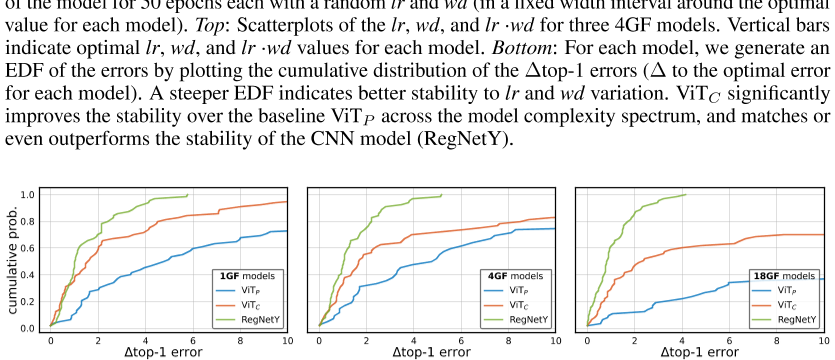
图5:SGD(lr和wd)的超参数稳定性:我们使用SGD而不是AdamW重复图4中的设置。ViT的稳定性改善覆盖了基线ViT P,甚至比AdamW更大。例如。,∼ 60%的维生素C-18GF型号在4%以内∆ 最佳结果的误差最大,而ViT P-18GF模型的误差不到20%(事实上,大多数ViT P-18GF运行不收敛)。
5.3学习率和权重衰减稳定性
接下来,我们描述了在AdamW和SGD优化器下,不同的模型族对学习率(lr)和权重衰减(wd)变化的敏感性。为了量化这一点,我们利用误差分布函数(EDF)[30]。EDF的计算方法是将一组结果从低误差到高误差进行排序,并绘制结果随误差增加的累积比例,详情请参见【30】。特别是,我们根据lr和wd生成模型的EDF。直觉是,如果模型对这些超参数选择具有稳健性,EDF将是陡峭的(所有模型的性能都类似),而如果模型是敏感的,EDF将是浅薄的(表现将分散)。
我们测试了6个ViT模型({P,C}×{1,4,18}GF)和3个RegNetY模型({1,4,16}GF)。对于每个模型和每个优化器,我们通过随机抽样64(lr,wd)对计算EDF,并在固定宽度间隔内围绕该模型和优化器的最佳值对学习率和权重衰减进行抽样(抽样细节见附录)。我们不绘制EDF中的绝对误差,而是绘制∆ top-1最佳结果(使用最佳lr和wd获得)与观测结果之间的误差。由于型号众多,我们每辆训练只开50个时代。
后果图4显示了由AdamW训练的的模型的散点图和EDF。图5显示了SGD结果。在所有情况下,我们都可以看到,对于这两种优化器,ViT C都比ViT P显著提高了lr和wd稳定性。这表明维生素C比维生素P更容易优化lr和wd。
5.4实验细节
在所有实验中,我们采用一个半周期的余弦学习率衰减时间表进行训练,并采用5个 epochs的线性学习率预热[16]。我们使用2048的小批量。关键的是,权重衰减不适用于归一化层中的增益因子,也不适用于模型中任何地方的bias参数;我们发现,对于小型模型和短期计划,衰减这些参数可以显著降低top-1精度。为了进行推断,我们使用模型权重的指数移动平均值(EMA)(例如,[8])。附录中报告了本节中使用的lr和wd。其他超参数使用默认值:SGD动量为0。9和AdamW的β1=0。9和β2=0。999 .
正则化和数据扩充。我们使用了一个简化的训练配方,与最近的工作(如DeiT[41])相比,我们发现它在模型复杂性和数据集规模的广泛范围内同样有效。我们使用AutoAugment[7]、mixup[52](α=0.8)、CutMix[51](α=1.0)和标签平滑[38](=0.1)。我们更喜欢这种设置,因为它类似于CNN的常见设置(例如,[12]),除了更强烈的混合和添加CutMix(VIT从两者中受益,而CNN不会受到损害)。我们将此配方与附录中用于DeiT模型的配方进行了比较,并观察到我们的设置提供了更快的训练收敛速度,这可能是因为我们删除了重复扩增[1,20],这是众所周知的减慢训练的方法[1]。
6峰值表现
模型的峰值表现是网络设计中最常用的指标。它代表了迄今为止最为人所知的设置的可能性,并随着时间的推移而自然演变。在不同的模型之间进行公平的比较是可取的,但困难重重。仅仅引用先前工作的结果可能会对该工作产生负面的biased,因为它无法包含更新的、但适用的改进。在这里,我们力求对最先进的CNN、ViT P和ViT C进行更公平的比较。我们确定了一组因素,然后在每个模型的哪些子集要优化与哪些子集要优化之间达成务实的平衡。哪个子集在所有模型中共享一个常量值。
在我们的比较中,所有模型共享相同的时代(400),使用模型权重EMA,以及一组正则化和增强方法(如§5.4所述)。所有CNN均接受SGD的训练的,lr为2。54和wd/2。4e− 5.我们发现这种单一选择在所有模型中都很有效,正如在[12]中所观察到的一样。对于所有ViT型号,我们发现AdamW的lr/wd为1。0e− 3 / 0 . 除36GF型号外,其他24种型号均有效。对于这些较大的型号,我们测试了一些设置,发现lr/wd为6。0e− 4 / 0 . 28对ViT P-36GF和ViT C-36GF型号更有效。对于训练和推理,VIT使用224×224分辨率(我们不会在更高分辨率下进行微调),而CNN使用(通常更大)优化分辨率,如【12,39】所述。根据该协议,我们比较了模型复杂性(1GF到36GF)和数据集规模(直接在ImageNet-1k上进行训练与在ImageNet-21k上进行预训练,然后在ImageNet-1k上进行微调)的ViT P、ViT C和CNN。
后果图6显示了一系列结果。每个图显示ImageNet-1k val top-1错误vs。
ImageNet-1k epoch训练时间。1左图比较了几种最先进的CNN。RegNetY和RegNetZ【12】在训练速度谱中取得了类似的结果,并优于Effi-cientNets【39】。令人惊讶的是,resnet[19]在快速运行时方面具有很强的竞争力,这表明在更公平的比较下,这些年前的模型的性能大大优于经常报道的(参见[39])。
中间的图将两个具有代表性的CNN(ResNet和RegNetY)与ViTs进行比较,仍然只使用ImageNet-1k训练。在整个模型复杂度范围内,基准ViT P表现不佳。令我们惊讶的是,在这种体制下,ViT P的表现也不如Resnet。ViT C更具竞争力,在中等复杂度范围内优于CNN。
右图比较了相同的模型,但与ImageNet-21k预训练(详情见附录)。
在此设置中,ViT模型展示了从更大规模数据中获益的更大能力:现在ViT C的性能严格优于ViT P和RegNetY。有趣的是,即使在这个大得多的数据集上进行了训练的,原始的ViT P也没有超过最先进的CNN。数值结果见表2,以供参考精确值。此表还强调了触发器计数与运行时没有显著相关性,但激活与之相关(更多详细信息请参见附录),正如【12】所观察到的。例如。,效率网(EfficientNets)相对于它们的浮点运算速度慢,而vit则快。
这些结果验证了ViT C的卷积干不仅提高了优化稳定性(如前一节所示),而且还提高了峰值表现。此外,这一优势可以在模型复杂性和数据集规模范围内看到。也许令人惊讶的是,鉴于最近对ViT的兴奋,我们发现ViT P难以与最先进的CNN竞争。我们仅在使用大规模预训练数据和提出的卷积干时观察到CNN的改善。
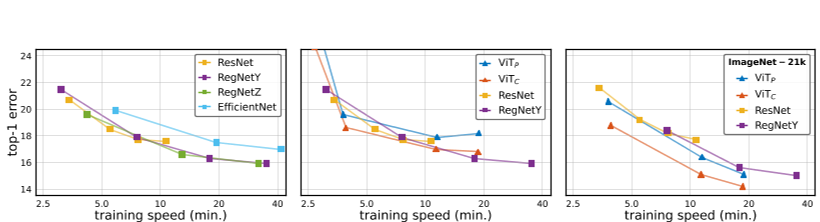
图6:峰值表现(epoch训练time vs.ImageNet-1k val top-1 error):对维生素P、维生素C和CNN进行公平、对照比较的结果。每条曲线对应于模型复杂度扫描,产生训练速度谱(每ImageNet-1k epochs分钟数)。左图:最先进的CNN。配备了现代训练配方的RESNET在速度更快的情况下具有很强的竞争力,而RegNetY和Z的表现类似,并且优于EfficientNets。中间:选择CNN与VIT进行比较。由于只能访问ImageNet-1k训练数据,RegNetY和ResNet在所有方面都优于ViT P。ViT C与CNN相比更具竞争力。右图:ImageNet-21k上的预训练对ViT模型的改进超过了CNN,使ViT P具有竞争力。在整个训练速度谱中,建议的ViT C优于所有其他模型。
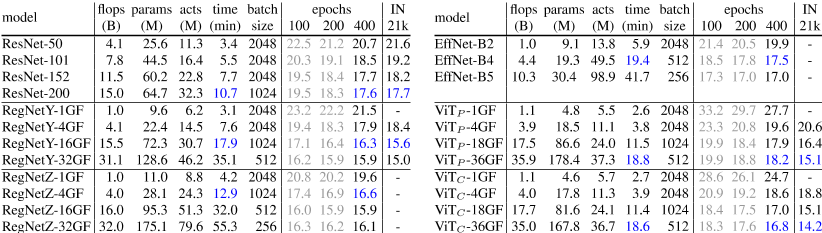
表2:峰值表现(按模型系列分组):ImageNet-1k上100、200和400个 epochs计划的模型复杂性和验证top-1错误,以及ImageNet-21k(21k)上预训练和ImageNet-1k上微调后的top-1错误。此表用作图6所示结果的参考。蓝色数字:每个ImageNet-1k epochs20分钟内可训练的最佳模型。据报告,批量大小和训练时间标准化为8个32GB Volta GPU(见附录)。附录中给出了ImageNet-V2【33】测试集的其他结果。
7结论
在这项工作中,我们证明了ViT模型的优化挑战与ViT的补丁茎中的大跨步、大核卷积有关。用一个简单的卷积干替换这个补丁干的看似微不足道的变化导致了优化行为的显著变化。
通过卷积干,ViT(称为ViT C)比原始ViT(称为ViT P)收敛速度更快(§5.1),使用AdamW或SGD进行良好训练(§5.2),提高学习速度和权重衰减稳定性(§5.3),并通过∼ 1-2% (§ 6 ). 这些结果在广泛的模型复杂性(1GF到36GF)和数据集规模(ImageNet-1k到ImageNet-21k)中是一致的。我们的结果表明,在ViTs的早期阶段注入小剂量的卷积诱导bias是非常有益的。展望未来,我们对这样一个理论基础很感兴趣,为什么这样一个最小的架构修改可以对优化性产生如此大的(正)影响。我们还对研究更大的模型感兴趣。我们对72GF模型的初步探索表明,卷积干仍能改善top-1误差,但我们还发现,出现了一种新形式的不稳定性,导致训练误差随机尖峰,尤其是ViT C。
致谢。我们感谢HervéJegou、Hugo Touvron和Kaiming He的宝贵反馈。
.

表3:茎设计:我们将ViT的标准修补茎(P)和卷曲茎(C)与四种备选方案(s 1-s 4)进行比较,每种备选方案都包括修补层,即。,内核大小(>1)等于步幅(以蓝色突出显示)的卷积。结果使用50个epoch训练、4GF模型大小以及所有模型的最佳lr和wd值。我们观察到,增加修补层(S 1-S 4)的像素大小会系统地降低top-1错误和优化器稳定性(∆ ) 相对于C
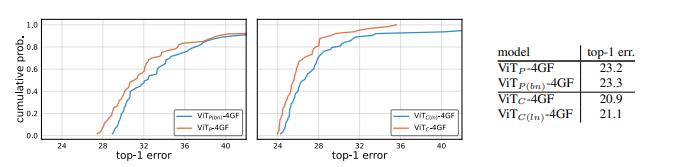
图7:茎归一化和非线性:我们在补片茎和训练ViT P-4GF(左图)后应用BN和ReLU,或在ViT C-4GF(中图)的卷积茎中用层范数(LN)替换BN。EDF是通过采样lr和wd值以及50个时期的训练来计算的。表(右)显示了100个 epochs结果,使用50个 epochs的最佳lr和wd值。EDF和100个时代的误差差距很小,表明这些选择相当微不足道。
附录A:阀杆设计消融实验
ViT的修补干与提出的卷积干的不同之处在于所使用的卷积类型以及归一化和非线性激活函数的使用。接下来我们将研究这些因素。
阀杆设计。本文的重点是研究将ViT的默认修补干改为由两个3×3卷积叠加而成的简单标准卷积干的巨大正影响。探索阀杆设计空间,以及更广泛的“混合ViT”模型【13】,以最大化表现是一个明确的反目标,因为我们想研究最小修改下的影响。然而,我们可以通过考虑介于修补茎(P)和标准卷曲茎(C)之间的替代茎设计来获得更多的见解。表3给出了四种备选设计(S 1-S 4)。阀杆的设计使整个模型flops保持可比性。茎S 1修饰C,使其包含一个小的2×2修补层,这会使结果稍微恶化。茎S 2-S 4系统地将修补层的像素大小p从p=2增加到16,与茎p中使用的大小相匹配。增加p会可靠地降低错误和优化器的稳定性。尽管我们根据现有的CNN最佳实践,事先选择了C设计,但我们事后发现,它优于四种备选设计,每种设计都包含一个补丁层。
阀杆规范化和非线性。我们从两个方向研究了归一化和非线性:(1)在ViT的默认补丁干中添加BN和ReLU,(2)在提出的卷积干中改变归一化。在第一种情况下,我们只需在50和100个时代的补片茎和训练ViT P-4GF(称为ViT P(BN)-4GF)后应用BN和ReLU。对于第二种情况,我们用ViT C-4GF进行了四次实验:{50100}个时代×{BN,层norm(LN)}。
如前所述,我们使用50 epoch时间表为每个实验调整lr和wd,并将这些值用于100 epoch时间表。我们使用AdamW进行所有实验。图7显示了结果。从使用50个 epochs时间表的EDF中,我们可以看到,将BN和ReLU添加到修补茎中会略微恶化最佳top-1错误,但不会影响lr和wd稳定性(左)。在卷积干中将BN替换为LN会略微降低最佳top-1误差和稳定性(中间)。
表(右)显示了使用从50次 epochs运行中选择的最佳lr和wd值的100个 epochs结果。在100个时代,误差差距很小,表明这些因素可能无关紧要。
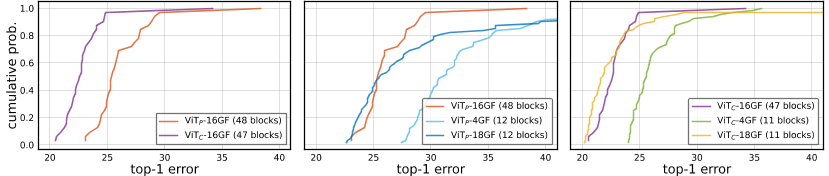
图8:更深层次的模型:我们将ViT P-4GF的深度从12个区块增加到48个区块,称为ViT P-16GF(48个区块),并创建具有卷曲茎的对应物ViT C-16GF(47个区块);所有模特都经过50个时代的训练的。左:尽管只考虑了∼ 总失败次数的2%。中,右:较深的16GF VIT明显优于较浅的4GF模型,并实现与较浅和较宽的18GF模型相似(略差)的误差。较深的ViT P模型也比较浅的ViT P模型具有更好的lr/wd稳定性。
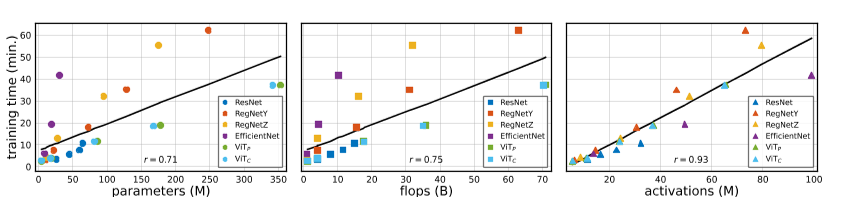
图9:复杂性度量与。运行时:我们绘制模型的GPU运行时与三种常用的复杂性度量:参数、触发器和激活。对于包括ViT在内的所有模型,运行时与激活的相关性最大,而不是与触发器的相关性,正如之前针对CNN所显示的那样【12】。
附录B:深层模型消融实验
Touvron等人。[42]发现更深的ViT模型更不稳定,例如。,将transformer块的数量从12个增加到36个可能会导致∼ 在lr和wd的固定选择下,top-1精度下降10分。他们证明,随机深度和/或他们提出的分层尺度可以弥补这种训练失败。在这里,我们通过观察通过采样lr和wd创建的EDF来探索更深层次的模型。我们将ViT P-4GF模型的深度从12个区块增加到48个区块,称为ViT P-16GF(48个区块)。然后,我们移除一个块,并使用ViT C-4GF的卷积干,得到对应的ViT C-16GF(47块)模型。图8显示了按照§5.3中的设置,两个模型和较浅模型的EDF,以供比较。尽管卷积干仅占1/48(∼ 总失败率为2%),与修补后的同类产品相比,它有了实质性的改进。我们发现,多种lr和wd选择允许对更深层次的ViT模型进行训练的,而无需大幅降低top-1表现,也无需进行额外修改。事实上,在取样范围内,较深的维生素P-16GF(48块)比维生素P-4GF和维生素P-18GF具有更好的lr和wd稳定性(图8,中间)。
附录C:大型模型ImageNet-21k实验
在表2中,我们报告了ImageNet-21k上ViT模型的峰值表现高达36GF。为了研究更大的模型,我们使用22个块、1152个隐藏大小、18个头和4个MLP乘法器构建了一个72GF ViT P。对于ViT C-72GF,我们使用了与ViT C-18GF和ViT C-36GF相同的C-stem设计,但没有移除一个transformer块,因为在这种复杂的情况下,C-stem中的触发器增加是微不足道的。
我们对72GF ViT模型的初步探索直接采用用于36GF ViT模型的超参数。在这种情况下,我们观察到卷积干仍能改善top-1误差,然而,我们还发现出现了一种新的不稳定性形式,导致训练误差随机尖峰。有时,训练可能会在同一时期内恢复,随后最终的准确性不会受到影响;或者,可能需要几个时代才能从错误峰值中恢复,在这种情况下,我们观察到最终精度不理想。第一类错误峰值在ViT P-72GF中更常见,而后一类错误峰值在ViT C-72GF中更常见。
为了缓解这种不稳定性,我们采取了两种措施:(i)对于这两种模型,我们将wd从0降低。28到0。15正如我们发现的那样,它显著降低了错误峰值的可能性。(ii)对于维生素C-72GF,我们从ImageNet-21k预训练的维生素C-36GF初始化其茎,并在整个训练期间保持其冻结。这些修改使训练ViT-72GF模型在ImageNet-21k上可行。当在ImageNet-1k上进行微调时,ViT P-72GF达到14。前1名误差为2%,ViT C-72GF达到13。6%的top-1错误,表明ViT C仍优于其ViT P对应物。将微调分辨率从224提高到384,将ViT C-72GF的表现提高到12。6%的top-1错误,同时将微调模型的复杂性从72GF显著增加到224GF。

表4:§5中使用的学习率和权重衰减:左:§5.1和§5.2中用于实验的每种模型lr和wd值,针对50个时代的ImageNet-1k进行了优化。右图:根据§5.3中用于实验的lr和wd型号范围。请注意,对于§6中的最终实验,我们进一步限制了lr和wd值,对所有CNN模型使用单一设置,对所有ViT模型仅使用两种设置。我们建议在比较模型时使用§6中的简化值集,以进行公平且易于复制的比较。所有lr值均为标准化w.r.t.最小批量为2048【16】。
附录D:模型复杂性和运行时间
在前面的部分中,我们报告了错误vs。训练时间。其他常用的复杂性度量包括参数、触发器和激活。事实上,最典型的是报告精度作为模型触发器或参数的函数。然而,触发器可能无法反映现代内存带宽有限加速器(如GPU、TPU)的瓶颈。同样,参数是模型运行时更不可靠的预测因子。相反,最近的研究表明,激活是GPU上更好的运行时代理(参见[12,31])。接下来,我们将探讨ViT模型是否存在类似的结果。
对于CNN,之前的研究[12,31]将激活定义为卷积层所有输出张量的总大小,而忽略归一化和非线性层(通常与卷积成对,只会通过常数因子改变激活计数)。本着这种精神,对于transformers,我们将激活定义为所有矩阵乘法的输出张量的大小,同样地,忽略元素方面的层和规范化。对于使用这两种类型操作的模型,我们只需测量所有卷积和vision transformer层的输出大小。
图9显示了作为这些模型复杂性度量函数的运行时。皮尔逊相关系数(r)证实,激活与实际运行时间(r=0.93)的线性相关性比触发器(r=0.75)或参数(r=0.71)强得多,证实了[12]对CNN的发现也适用于VIT。虽然触发器在某种程度上可以预测运行时,但具有较大激活与触发器比率的模型(如EfficientNet)的运行时比基于触发器的预期要高得多。
最后,我们注意到ViT P和ViT关心的所有复杂性度量和运行时几乎相同。
计时。在整篇论文中,我们报告了标准化的训练时间,就像模型是在一台8 V100 GPU服务器上进行训练的一样,将实际的训练时间乘以使用的GPU数量,再除以8。(由于不同型号的内存需求不同,我们可能需要扩大GPU的数量以适应目标小批量大小。)我们使用处理一个ImageNet-1k epochs所需的分钟数作为标准度量单位。我们更喜欢训练时间而不是推理时间,因为推理时间在很大程度上取决于用例(例如,流式、面向延迟的设置要求批大小为1,而面向吞吐量的设置允许批大小为1)和硬件平台(例如,智能手机、加速器、服务器CPU)。
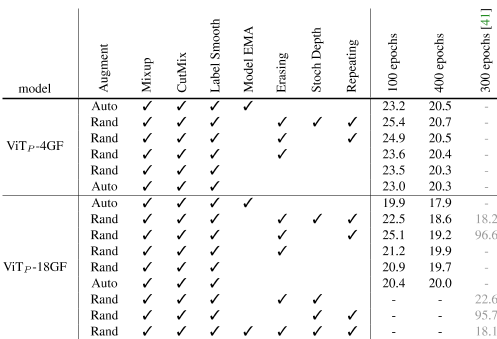
表5:数据增强和正则化的消融:我们使用表4(左图)中的lr和wd,除了ViT P-18GF模型和RandAugment,后者受益于更强的wd(我们将wd增加到0.5)。原始DeiT消融结果【41】以灰色复制以供参考(最后一列);这些使用1e的lr/wd− 3 / 0 . 05(lr标准化为小批量2048),这导致一些训练失败(我们注意到我们的wd为5-10×更高)。我们默认的训练设置(每组的第一行)使用AutoAugment、mixup、CutMix、label smoothing和模型EMA。与DeiT设置(每组第二行)相比,我们不使用擦除、随机深度或重复。虽然我们的设置同样有效,但它更简单,收敛速度也更快(见图10)。
附录E:其他实验细节
稳定性实验。对于§5.1和§5.2中的实验,我们允许每个CNN和ViT模型选择不同的lr和wd。我们发现所有CNN都选择几乎相同的值,因此我们将其规范化为一个选项,如[12]中所述。ViT车型更喜欢多样化的选择。表4(左)列出了所选值。对于§5.3中的实验,我们使用表4(右)中所示的lr和wd间隔。这些范围是通过(i)获得每个模型系列的初始良好lr和wd选择来构建的;然后(ii)将它们乘以1/8和4。0表示左侧和右侧区间端点(我们使用非对称区间,因为模型可以使用较小但不较大的值进行训练)。最后,我们注意到,如果我们要重做实验,§5.1/§5.2中使用的设置可以简化。
ImageNet-1k上的表现峰值。我们注意到,在后来的实验中,我们发现调整每个模型的lr和wd并不是获得竞争结果所必需的。因此,对于§6中的最终实验,我们进一步限制了lr和wd值,对所有CNN模型使用单一设置,对所有ViT模型仅使用两种设置,如§6中所述。我们建议在比较模型时使用此简化值集,以进行公平且易于复制的比较。最后,对于这些实验,当训练受到内存约束时(即,对于EfficientNet-{B4,B5},RegNetZ-{4,16,32}GF),我们从2048年开始减少小批量大小,并根据[16]线性缩放lr。
ImageNet-21k上的表现峰值。对于ImageNet-21k,一个包含1400万幅图像和∼ 21k类,我们为90(ImageNet-21k)个时代预先训练模型,如下所示[13]。我们不会搜索ImageNet-21k的最佳设置,而是使用与ImageNet-1k相同的训练配方(最大小批量)。为了减少训练时间,我们将训练分发到更多GPU上,并使用更大的小批量(4096),并相应地扩展lr缩放。为了简单性和再现性,我们对每幅图像使用一个标签,而之前的一些工作(例如,[35,40])使用WordNet[28]将单个标签扩展为多个标签。预训练后,我们在ImageNet-1k上微调了20个时代,并使用小规模的lr网格搜索,同时将wd保持在0,类似于[13,40]。
附录F:正则化和数据扩充
在本研究开始时,我们为ViT模型开发了一个简化的训练设置。我们的目标是设计一个尽可能简单的训练设置,类似于用于最先进CNN的设置【12】,并保持与DeiT的竞争准确性【41】。在这里,我们通过考虑基线ViT P-4GF和ViT P-18GF模型来记录这一探索。除了简化之外,我们还观察到,我们的训练设置比DeiT设置产生更快的收敛,如下所述。
表5将我们的设置与DeiT的设置进行了比较【41】。根据他们的lr/wd选择,[41]报告在删除擦除和随机深度时未能通过训练,并且在删除重复时准确性显著下降。我们发现,只要使用更高的wd(我们的wd为5-10×更高),就可以安全地禁用它们。我们观察到,我们可以删除ViT P-4GF的模型EMA,但对于更大的ViT P-18GF模型来说,这是必不可少的,尤其是在400个时代。如果没有模型EMA,ViT P-18GF仍然可以有效地进行训练的,但这需要额外的增强和正则化(如DeiT)。
图10显示,我们的训练设置加快了ViT P和ViT C模型的收敛速度,通过比较误差Delta(∆ 上图1)在DeiT基线和我们的基线之间(左图和中图)。我们的训练设置也产生了比我们复制DeiT(右图)更好的top-1错误。我们推测,更快的收敛速度是由于删除了重复增广[1,20],这在[1]中显示为减慢收敛速度。在某些情况下,重复增强可能会提高准确性,但我们在实验中没有观察到这种改进。
附录G:ImageNet-V2评估在主要论文和之前的附录部分中,我们在原始(OG)ImageNet验证集上对所有模型进行了基准测试【10】。在这里,我们在ImageNet-V2上对我们的模型进行基准测试【33】,这是一个按照原始程序收集的新测试集。我们从表2中选取400个epoch或ImageNet-21k模型,这取决于哪个更好,并在ImageNet-V2上对其进行评估,以收集前1个错误。
图11显示,排名大多保持在噪声的一个标准偏差(估计为∼ 0 . 1 - 0 . 2% ). 这两个测试集表现出线性相关,皮尔逊相关系数r=0证实了这一点。99,尽管ImageNet-V2结果显示出更高的绝对误差。拟合线的参数由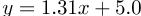 给出。
给出。
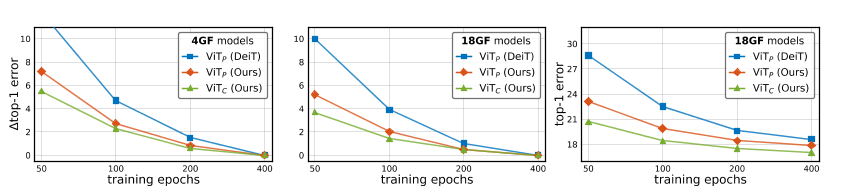
图10:训练配方对收敛的影响:我们使用DeiT配方vs.训练ViT模型。我们的简化版本。左侧和中部:∆ 4GF和18GF模型在50、100和200个 epochs时的前1位误差,以及在400个 epochs时的渐近表现。右:18GF模型的绝对top-1误差。删除增广项并使用模型EMA加速了ViT P和ViT C模型的收敛,同时略微改善了DeiT top-1错误的再现。
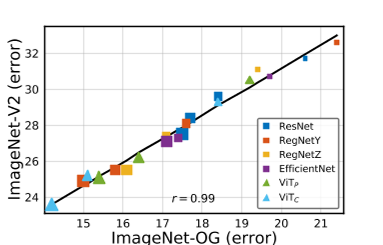
图11:ImageNet-V2表现:我们从表2中获取模型,并在ImageNet-V2测试集上对其进行基准测试。绘制原始(OG)ImageNet验证集(x轴)和ImageNet-V2测试集(y轴)的前1个错误。排名大多保持在噪声的一个标准差以内(估计为∼ 0 . 1 - 0 . 2%),两个测试集表现出线性相关(皮尔逊r=0.99)。标记大小对应于模型flops。
参考文献
[1] Maxim Berman, Hervé Jégou, Andrea Vedaldi, Iasonas Kokkinos, and Matthijs Douze. MultiGrain: a unified image embedding for classes and instances. arXiv:1902.05509 , 2019. 8 , 14
[2] Antoni Buades, Bartomeu Coll, and J-M Morel. A non-local algorithm for image denoising. In CVPR , 2005. 3
[3] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In ICML , 2020. 5
[4] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In ICCV , 2021. 3
[5] Zhengsu Chen, Lingxi Xie, Jianwei Niu, Xuefeng Liu, Longhui Wei, and Qi Tian. Visformer: The vision-friendly transformer. In ICCV , 2021. 3
[6] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers. ICLR , 2020. 3
[7] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. AutoAugment: Learning augmentation policies from data. In CVPR , 2019. 8
[8] Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Bichen Wu, Zijian He, Zhen Wei, Kan Chen, Yuandong Tian, Matthew Yu, Peter Vajda, et al. FBNetV3: Joint architecture-recipe search using neural acquisition function. arXiv:2006.02049 , 2020. 8
[9] Stéphane d’Ascoli, Hugo Touvron, Matthew Leavitt, Ari Morcos, Giulio Biroli, and Levent Sagun. ConViT: Improving vision transformers with soft convolutional inductive biases. In ICML , 2021. 2 , 3
[10] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In CVPR , 2009. 2 , 3 , 5 , 14
[11] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NACCL , 2019. 1
[12] Piotr Dollár, Mannat Singh, and Ross Girshick. Fast and accurate model scaling. In CVPR , 2021. 5 , 8 , 11 , 12 , 13
[13] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR , 2021. 1 , 2 , 3 , 4 , 5 , 10 , 13
[14] Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. In ICCV , 2021. 3
[15] Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological cybernetics , 36(4):193–202, 1980. 3
[16] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training ImageNet in 1 hour. arXiv:1706.02677 , 2017. 3 , 8 , 12 , 13
[17] Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. LeViT: a vision transformer in ConvNet’s clothing for faster inference. In ICCV , 2021. 3 , 5
[18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. In ICCV , 2017. 3
[19] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR , 2016. 1 , 3 , 4 , 8
[20] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: better training with larger batches. arXiv:1901.09335 , 2019. 8 , 14
[21] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML , 2015. 3 , 4
[22] Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big Transfer (BiT): General visual representation learning. In ECCV , 2020. 4
[23] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. ImageNet classification with deep convolutional neural networks. In NeurIPS , 2012. 3
[24] Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne Hubbard, and Lawrence D Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation , 1989. 1 , 3
[25] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV , 2021. 3
[26] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmenta- tion. In CVPR , 2015. 3
[27] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR , 2019. 1 , 3 , 5 [28] George A Miller. Wordnet: a lexical database for english. Communications of the ACM , 1995. 13 [29] Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In ICML , 2010. 4
[30] Ilija Radosavovic, Justin Johnson, Saining Xie, Wan-Yen Lo, and Piotr Dollár. On network design spaces for visual recognition. In ICCV , 2019. 2 , 5 , 7
[31] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollár. Designing network design spaces. In CVPR , 2020. 5 , 12
[32] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. Stand-alone self-attention in vision models. NeurIPS , 2019. 3
[33] Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In ICML , 2019. 9 , 14
[34] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NeurIPS , 2015. 3
[35] Tal Ridnik, Emanuel Ben-Baruch, Asaf Noy, and Lihi Zelnik-Manor. Imagenet-21k pretraining for the masses. In NeurIPS , 2021. 13
[36] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recogni- tion. In ICLR , 2015. 2 , 3 , 4
[37] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In CVPR , 2015. 3
[38] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR , 2016. 8
[39] Mingxing Tan and Quoc V Le. EfficientNet: Rethinking model scaling for convolutional neural networks. ICML , 2019. 2 , 8
[40] Mingxing Tan and Quoc V Le. Efficientnetv2: Smaller models and faster training. In ICML , 2021. 13 [41] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In ICML , 2021. 1 , 3 , 4 , 5 , 8 , 13 , 14
[42] Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. arXiv:2103.17239 , 2021. 1 , 3 , 5 , 11
[43] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS , 2017. 1 , 3
[44] Qiang Wang, Bei Li, Tong Xiao, Jingbo Zhu, Changliang Li, Derek F Wong, and Lidia S Chao. Learning deep transformer models for machine translation. In ACL , 2019. 3
[45] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In ICCV , 2021. 3
[46] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR , 2018. 3
[47] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang. CvT: Introducing convolutions to vision transformers. In ICCV , 2021. 3
[48] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transforma- tions for deep neural networks. In CVPR , 2017. 3
[49] Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou, Fengwei Yu, and Wei Wu. Incorporating convolution designs into visual transformers. In ICCV , 2021. 3
[50] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zihang Jiang, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token ViT: Training vision transformers from scratch on ImageNet. In ICCV , 2021. 3
[51] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. CutMix: Regularization strategy to train strong classifiers with localizable features. In CVPR , 2019. 8 [52] Hongyi Zhang, Moustapha Cissé, Yann N. Dauphin, and David Lopez-Paz. Mixup: Beyond empirical risk minimization. In ICLR , 2018. 8
[53] Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. Exploring self-attention for image recognition. In CVPR , 2020. 3
[54] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. In AAAI , 2020. 5















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









