







这是我第一次记录我学习数据科学的心路历程。让我们从最入基础的kaggle比赛说起吧。
在这个比赛里,我们的目标是利用已知船上乘客的信息(比性格,年龄,舱位等级),预测他们的生还。
 Translated letter reveals first hand account of the “unforgettable scenes where horror mixed with sublime heroism” as the Titanic sank Photo: Getty Images
Translated letter reveals first hand account of the “unforgettable scenes where horror mixed with sublime heroism” as the Titanic sank Photo: Getty Images
泰坦尼克的惨剧有多大的损失?
让我们用探索性分析看看这次惨剧有多严重吧。
如下面的柱状图所示,大约仅有38%的人从事件生还,并且男性乘客的丧生率远远大于女性。头等舱,二等舱和三等舱的比例大约为25%,25% 和 50%。 三等舱的乘客相比来说,更加容易丧生。泰坦尼克还有不同的甲板,从顶层(T) 到 底层(G),不过不同甲板的乘客生还率并没有明显的不同。

一些别的发现
大部分船上的乘客为年纪在20至40的成年人。在年龄生还的分布图上,15岁以下的孩子的生存率明显提高,而20至30岁的成年人的死亡率明显提高。由些我们可以推断当时的孩子是有优先获得生存的机会。
船票价格主要分布在50磅以下。分布图明显的显示持有便宜票价登船的人死亡率更高。
决策树模型
统计中的决策树模型是从决策树方法演变而来的。决策树模型是一种递归的方法, 通过不断地分割预测分量,目的是为了让误差率不断减小,达到某个水平。 在这里,我们把这个不平(误差的阀值)定义为 complexity parameter (cp)。
决策树模型可以大致地分为两类:1) 分类树模型: 用作统计、机器学习中的分类问题,它的预测值是一个离散变量(不连续的) 2) 回归树模型: 用作回归问题, 它的预测值是一个连续变量。在本组数据里,我们的预测值是乘客的两个状态:生存、死亡,所以二元分类树更合适于这个问题。决策树模型的最大优点在于它的可解释性。
观察下面的决策树图,称呼非’Dr’,’Mr’,’Rev’,’Sir’ 并且头等,二等舱(Pclass=1,2)乘客有最大的可能性生还(21%的乘客符合这个条件);然而三等舱(Pclass=3 )并且家庭成呗多过4个的乘客生还的可能性最小(9%的可能性)。
决策树模型有一种缺点就是容易过度拟合。 如果我们为了提高模型的准确率,不断地减小cp值,那么我们很可能就已经过度拟合了。比较相对简单的模型 (cp=0.01) 和复杂模型(cp=0.005),简单模型的分叉比较少,因此从可读性的角度比较容易理解,但是有1% (cp)的误差。然而复杂模型有更多的分叉,但是误差减小到了0.5%。
 Decision Tree (cp=0.01)
Decision Tree (cp=0.01)
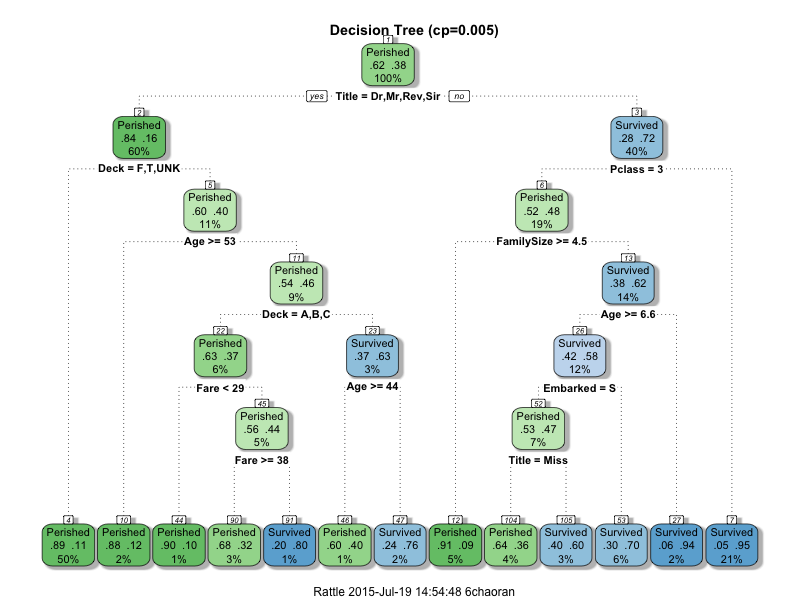 Decision Tree (cp=0.005)
Decision Tree (cp=0.005)
决策树的优化
过度拟合(over-fitting)与不充分拟合(under-fitting)是两个建模中两个不理想的极端情况。
不充分拟合: 假如我们用线性模型去做非线性问题的拟合,我们就可能不充分拟合,因为线性预测变量无法在一个较大泛围内解释非线性的变化。在这种情况下,即使我们收集更多的数据,也无法提高模型的准确率。我们会发现训练(training set),测试数据 (testing set)的准确率都很低。
过度拟合: 然而是另一个极端。通常来说,为了避免过度拟合,我们可以加入正则化参数,让简单(系数小)的模型更加优先,或者只利用部分数据进行训练。通常我们可以把数据分为三个部分,训练集(60%),验证集(20%),测试集(20%)。训练集的预测准确率通常要高过测试集,意味着我们在训练过程中失去了模型的通用性。在这里,我会用10-fold交叉验证来优化决策树模型。

cp Accuracy Kappa Accuracy SD Kappa SD 0.001 0.8141385 0.5975972 0.04255667 0.09447856 0.005 0.8095355 0.5861936 0.04231905 0.09474427 0.010 0.8145705 0.5976262 0.03892250 0.08801098 0.050 0.8050549 0.5832111 0.04278970 0.09398511
Accuracy was used to select the optimal model using the largest value. The final value used for the model was cp = 0.01.
从决策树到随机森林
基于决策树模型的进化从树模型到bagged trees到随机森林。
Bagged Tree:提取多个随机子集数据,用来拟合多个决策树模型,以提高模型性能。每个决策树因为子集数据而有所不同,最终的预测结果会根据所有树的预测结果决定。通过这种方法,预测的通用性会有所提高。
随机森林:是基于bagged tree另一个改进。不同于bagged tree,随机森林在训练每个树模型的时候只会利用部分预测变量,而非全部预测变量。这种方法又称为 “feature bagging”。bagged tree是在数据行方向的bagging, 而随机森林是在数据行列两个维度的bagging。因此,随机森林可以很好的克服过度拟合的问题。

Type of random forest: classification Number of trees: 1000 No. of variables tried at each split: 10
OOB estimate of error rate: 18.86% Confusion matrix: Perished Survived class.error Perished 478 71 0.1293260 Survived 97 245 0.2836257
如上图所示,随着树的数量增加,分类误差率最终减小到一个稳定值。
变量重要性(variable importance) 是一个有用的用来评估预测变量的指标。它被定义为,如果此预测变量被去除时,误差的增加量。在这个模型中,预测Title/Fare/Age是三个最重要的变量。
随机森林的优化
在R的randomForest包里,mtry是唯一用来优化随机森林的参数。mtry定义为在每次迭代里,特征的最小子集。那么,让我们来看看如何通过mtry来调整随机森林。
 Forest Tuning
Forest Tuning
mtry Accuracy Kappa Accuracy SD Kappa SD 2 0.8168234 0.6023054 0.03620667 0.07966124 5 0.8255575 0.6226448 0.03791115 0.08305082 10 0.8301592 0.6327758 0.03915158 0.08528492 15 0.8265825 0.6269271 0.03743233 0.08119438 20 0.8220955 0.6185287 0.03738573 0.08027263
Accuracy was used to select the optimal model using the largest value. The final value used for the model was mtry = 10.
小mtry价往往导致一个不充分拟合模型,而在另一方面,大mtry趋于具有一个过拟合模型,这两者会伤害模型的预测的准确性。平衡模型精度和复杂性,最佳的mtry位于10 。在决策树模型里,最好的准确率为 0.814,而随机森林可以达到0.830。这样的改进可能看起来很微不足道,但是这可能会让你在leaderboard上提高几百名的成绩。















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









