







1.泰坦尼克号生还预测 准备工作
泰坦尼克号生还预测是一个非常典型的联系项目。数据集是公开数据集。
1.1 环境准备
numpy=1.14.5
pandas=0.22.0
sklearn=0.19.2
seaborn=0.7.1
matplotlib=2.1.2
keras=2.1.6
1.2数据读取
(1)提前准备好titanic_dataset.csv文件,
准备好特征xtrain和标签ytrain数据
import numpy as np
import pandas as pd
feature=pd.read_csv('titanic_dataset.csv')
y_train=feature['Survived']
x_train=feature.drop('Survived',axis=1)
print(x_train.shape)
print(feature.head())(2)通过shape属性可以查看xtrain数据的维度![]()
通过featurn.head()可以查看前五条数据

(3)通过describe()方法可以得到,包括均值,中值,方差,最大最小等统计描述
通过info()方法得到,
print(feature.describe())
print(feature.info())
通过info()方法得到,每列的统计特性,特别是可以看出前四个属性不同于其他都是1309个值,说明这四个属性是有nan缺失值的,下一步对不同类型的缺失值进行处理。

1.3缺失值处理
(1)使用x_train.isnull().sum统计缺失值,结果如下如,说明前面4列均有缺失,但是要具体问题具体分析
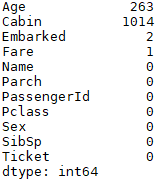
(1)Age字段,操作方法如下:
从sns可视化age数据可以看出来,age是服从正态分布,因此可以使用中值进行替换。
#使用seaborn进行可视化处理
import seaborn as sns
#print(sns.distplot.__doc__)
#Age直接去掉缺失值
sns.distplot(x_train['Age'].dropna(),hist=True,kde=True)
#以中值替换
x_train['Age'].replace(np.nan,np.nanmedian(x_train['Age']),
inplace=True)
(2)Cabin字段:缺失值比较多,直接去掉
x_train.drop("Cabin",axis=1,inplace=True)
(3)Embarked字段:由于Embarked表示乘船的港口,是字符型,缺失值比较少,填补
#可以填最多.
#由countplot函数 可以得到可以得到 最多的是‘s’因此 空缺项填s
#sns.countplot(x='Embarked',data=x_train)
x_train['Embarked'].replace(np.nan,'S',
inplace=True)
(4)Fare字段 只有一个缺失值,查看分布可知,没有什么规律,
'''
1)查询是哪条数据的票价信息欠缺,查看数据
2)查询信息Pclass=3,Embarked=“s”的数据,并返回DataFrame对象
3)讲缺失信息填为查询到信息的中值
'''
(5)sex字段 进行替换 male--1 female--0
x_train.drop("Cabin",axis=1,inplace=True)
#处理Embarked字段:由于Embarked表示乘船的港口,是字符型,缺失值比较少,填补
#可以填最多.
#由countplot函数 可以得到可以得到 最多的是‘s’因此 空缺项填s
#sns.countplot(x='Embarked',data=x_train)
x_train['Embarked'].replace(np.nan,'S',
inplace=True)
#处理Fare只有一个缺失值,查看分布可知,没有什么规律,
'''
(1)查询是哪条数据的票价信息欠缺,查看数据
(2)查询信息Pclass=3,Embarked=“s”的数据,并返回DataFrame对象
(3)讲缺失信息填为查询到信息的中值
'''
print(x_train.isnull().sum())
#sns.countplot(x='Fare',data=x_train)
print(x_train[np.isnan(x_train['Fare'])])
pclass3_fares=x_train.query('Pclass==3 & Embarked=="S"')
pclass3_fares=pclass3_fares['Fare'].replace(np.nan,0)
median_fare=np.median(pclass3_fares)
print(median_fare)
x_train.loc[x_train['PassengerId']==1044,'Fare']=median_fare
#print(x_train.isnull().sum())
#结果可知没有缺失值
#对于sex字段 进行替换 male--1 female--0
x_train['Sex'].replace(['male','female'],[1,0],inplace=True)
#print(x_train.head())下图是对Embarked的统计,可以看出"s"港口上船的人最多,此时缺失值填写“S”。

1.4 训练数据和预测数据
#数据清洗与分割
print(x_train.shape)
x_train=pd.get_dummies(x_train)#类似于one hot编码
print(x_train.shape)
#数据清洗 训练:测试=8:2 shuffle=True表示进行清洗数据
from sklearn.model_selection import train_test_split
#print(train_test_split.__doc__)
train_x,test_x,train_y,test_y=train_test_split(x_train,y_train,
train_size=0.8,
random_state=42,
shuffle=True)
print("train_x,test_x,train_y,test_y,shape is:\n{}\n{}\n{}\n{}\n"
.format(train_x.shape,test_x.shape,train_y.shape,test_y.shape)2. 决策树模型
2.1创建决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn import metrics
#创建模型
model=DecisionTreeClassifier()
model.fit(train_x,train_y)2.2 预测与计算精度
#预测结果
#预测训练集
train_pre=model.predict(train_x)
test_pre=model.predict(test_x)
#计算预测精度
train_acc=accuracy_score(train_y,train_pre)
test_acc=accuracy_score(test_y,test_pre)
print('train_acc:%f\n,test_acc:%f'%(train_acc,test_acc))最后得到:![]()
2.3 ROC
#计算ROC
y_score_dt=model.predict_proba(test_x)
fp,tp,thresholds=metrics.roc_curve(test_y,y_score_dt[:,1])
print(fp,tp)
auc_score=metrics.roc_auc_score(test_y,y_score_dt[:,1])
print(auc_score)![]()
















 3210
3210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











