









以下内容为本人学习Stanford Andrew Ng的课程Machine Learning的笔记,如有问题,欢迎指出与讨论
机器学习框架
机器学习的目标就是对训练集(Training Set)施加一定的学习算法(Learning Algorithms)获取
hθ(x)
(Hypothesis),这也是建模的过程。
当模型建好后,输入测试集或验证集(Test Set\Validation Set)到
hθ(x)
中便会得到预期结果(Estimate Result)。
梯度下降 (Gradient Descent)
最简单的
hθ(x)
便是线性的了,即
hθ(x)=θ0+θ1x1+θ2x2+....+θnxn
若记
x0=1
,则上述式子可化简为
hθ(x)=∑i=0nθixi=θTX
补充一些常见的符号:
m为训练集中样本对 (x(i),y(i)) 的个数;
n为特征(feature)的维度;
下面定义损失函数,
J(θ)=12∑i=0n(hθ(x(i))−y(i))2
12 是为了以后运算求偏导时方便化简,求和项为把每个训练集中的样本对的输入带入 hθ(x) 后与真实结果做差;平方求和后便可得到模型对整体训练集的代价,之后要做的便是要去取代价函数 J(θ) 的最小值,即 minθJ(θ)
梯度下降中更新 θ 的核心公式为,
θ:=θ−α∂∂θJ(θ) ,α为步长。
可以很形象地把这个想象成下山问题,取此次迭代位置的梯度的反向,走一个步长*梯度的距离,如图:
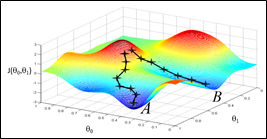
当然在线性情况下,我们不用考虑局部最优解的情况。Andrew已经给出图例,在线性情况下的 J(θ) 是一个碗形,只存在一个最优解。
随机梯度下降 (Stochastic Gradient Descent)
但是梯度下降的代价太大,每次都需要扫完整个训练集才能更新一次
θ
。于是就提出了随机梯度下降,二者对
θ
更新的公式很相近,只是变成了每次针对一个样本对更新
θj
:
θj:=θj−α∂∂θjJ(θ) =θj−α(hθ(x(i))−y(i))x(i)j
虽然,SGD每次不是朝着梯度最大的方向行进,但大致方向还是会趋向于最优解的。
神经网络 (Neural Network)
神经网络简单说就是由许多个神经元构成的网络,可以理解成中间生成了许多的中间 hθ(x) ,再相互叠加生成的模型;因为许多问题不是线性可分的,所以需要神经网络去把他转化为线性可分的,具体解释与例子见这里。















 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









