







1. CH2-kNN(1)
2. CH2-kNN(2)
3. CH2-kNN(3)
4. CH3-决策树(1)
5. CH3-决策树(2)
6. CH3-决策树(3)
7. CH4-朴素贝叶斯(1)
8. CH4-朴素贝叶斯(2)
9. CH5-Logistic回归(1)
10. CH5-Logistic回归(2)
======== No More ========
这篇博客讲的是决策树的测试、存储,还会展示一个实例。
测试决策树
这里的测试,指的就是建好了树之后,拿一条新的数据进行分类。
大致过程:从决策书根节点开始,比较待分类数据的改节点特征,并根据特征值,沿着决策树的边进入下一个节点,直到进入叶节点,就能给这条数据分类了。
def classify(inputTree,featNames,testVec):
firstStr = inputTree.keys()[0] #当前树的根节点的特征名称
secondDict = inputTree[firstStr] #根节点的所有子节点
featIndex = featNames.index(firstStr) #找到根节点特征对应的下标
key = testVec[featIndex] #找出待测数据的特征值
valueOfFeat = secondDict[key] #拿这个特征值在根节点的子节点中查找,看它是不是叶节点
if isinstance(valueOfFeat, dict): #如果不是叶节点
classLabel = classify(valueOfFeat, featNames, testVec) #递归地进入下一层节点
else: classLabel = valueOfFeat #如果是叶节点:确定待测数据的分类
return classLabelclassify函数接收三个参数:
(1)inputTree: 事先构建好的决策树。实际类型是一个dict,就像这样子(详情可以看上一篇博客):

(2)featNames: 特征的名称。按顺序的。
(3)testVec:一条待测数据的特征向量。
第7行: 用isInstance方法判断valueOfFeat是不是dict类型,也就是判断要找的这个子节点是不是一棵树。
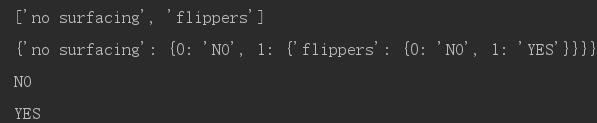
例如上面这个例子,我们拿到一条待测数据,首先比较它的'no surfacing'特征值。
如果是0的话,进入0这个子节点。此时valueOfFeat是'NO',不是dict类型,所以到达了叶节点,于是把它分类成'NO'。
如果是1的话,进入1这个子节点。此时valueOfFeat是{'flippers': {0: 'NO', 1: 'YES'}}},是dict类型,所以还只是一个内部节点,必须进一步分类。然后就递归地调用classify函数,进入下一层节点...
我们运行试试看:
dataSet, feats = createDataSet()
feats_copy = feats[:] #由于createTree函数会改变feats,所以先深复制一份feats
theTree = createTree(dataSet, feats)
print feats_copy, '\n', theTree
print classify(theTree, feats_copy, [1,0])
print classify(theTree, feats_copy, [1,1])结果:
待测数据 [1,0] 被分类成“NO”,[1,1]被分类成YES。
------------------------------------------------------------------------------------------------
决策树的存储
我们不希望每次拿新数据进行分类前,都构造一遍决策树。所以得想个办法把它存到硬盘上。
作者用的是pickle这个模块,用来将对象持久化。
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'w')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)就是把建好的决策树(dict类型)存进文件,或者拿出来。
运行一下试试看:
storeTree(theTree, 'storage.txt')
print grabTree('storage.txt')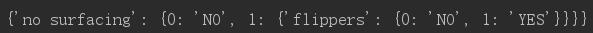
------------------------------------------------------------------------------------------------
实例:使用决策树预测隐形眼镜类型
这是一个“隐形眼镜数据集”。完整的数据集(挺小的):

4个特征,1个标签:
特征1(age):有3种特征值(young, pre, presbyopic)
特征2(prescript):有2种特征值(hyper, myope)
特征3(astigmatic):有2种特征值(yes, no)
特征4(tearRate):有2种特征值(reduced, normal)
标签有3种: hard, soft, no lenses
代码:
fp = open('lenses.txt')
lensesDataSet = [line.strip().split('\t') for line in fp.readlines()]
lensesFeatNames = ['age','prescript', 'astigmatic', 'tearRate']
lensesTree = createTree(lensesDataSet, lensesFeatNames)
print lensesTree结果:

然后我们还是把它画出来看一眼吧:
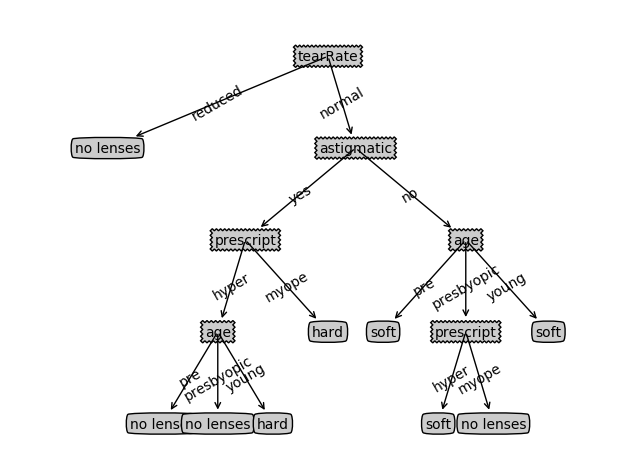
如果医生参考这棵决策树来给患者推荐隐形眼镜的话,那么他最多只用问4个问题就可以了。
这棵决策树非常好地匹配了实验数据,但是我们发现这些匹配选项可能太多了。这个问题被称为“过度匹配(overfitting)”。为了减轻这个问题,我们可以裁剪决策树,去掉一些没必要的叶节点。如果叶节点只能增加少许信息,那么可以删除它,将它并入到其他叶节点中。
作者说:这章使用的算法是ID3,它无法直接处理数值型(即连续性)数据。第9章就会讲另外一个决策树构造算法:CART,同时也会进一步讨论过度匹配的问题。














 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









