







1. CH2-kNN(1)
2. CH2-kNN(2)
3. CH2-kNN(3)
4. CH3-决策树(1)
5. CH3-决策树(2)
6. CH3-决策树(3)
7. CH4-朴素贝叶斯(1)
8. CH4-朴素贝叶斯(2)
9. CH5-Logistic回归(1)
10. CH5-Logistic回归(2)
======== No More ========
这次要介绍的内容是Logistic Regression(LR,逻辑斯蒂回归)。
首先介绍介绍一下“回归”的概念。
我觉得百度百科上的解释就挺好的。
回归,指研究一组随机变量(Y1 ,Y2 ,…,Yi)和另一组(X1,X2,…,Xk)变量之间关系的统计分析方法。通常(Y1 ,Y2 ,…,Yi)是因变量,(X1,X2,…,Xk)是自变量。
当因变量和自变量呈现线性关系时,我们可以利用称为线性回归方程的最小二乘函数,对自变量和因变量之间关系进行建模。基于这种线性模型的回归分析称为线性回归(Linear regression)。其目的是寻找合适的参数,用一条直线去拟合散列的数据点,就像下图这个样子。线性回归在之后的章节会讲到。

而这篇博客要介绍的Logistic回归,做的是这么一件事情:根据现有的数据,对分类的边界线建立回归公式,以此进行分类。
它和线性回归在直观上的一个区别就是,数据点不一定呈现行排列,也许是这里一坨,那里一坨,它们每一坨代表一个类,里面的数据点具有同一个标签。就像下面这个样子:

我们要做的就是找出分类的边界线。这个边界线是用回归公式来表示的。我们在训练分类器的时候,所做的事情就是利用最优化算法,找出回归公式中的最佳回归系数。
这里的概念有点多,后文会一一介绍。还是先按惯例把算法的特点介绍一下。
-------------------------------------------------------------------------------------
Logistic回归(Logistic Regression)
(1)是一种基于最优化算法的分类方法。
(2)优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型: 数值型和标称型数据。
-------------------------------------------------------------------------------------
基于Logistic回归和Sigmoid函数的分类
基于Logistic回归的分类模型是这样的,给定任意一组输入,然后通过某个函数得到输出,这个输出就是输入数据的分类。比如,在二分类情况下,这个函数就输出0或1。
符合这个性质的函数有很多种,其中一种就是Sigmoid函数:
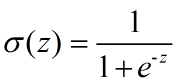
这个函数长这样:
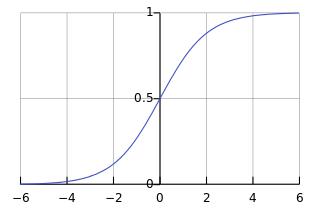
当z为0的时候,函数值为0.5;随着z的增大,函数值逼近于1;随着z的减小,函数值逼近于0.
所以,这个函数很适合做我们刚才提到的二分类的分类函数。假设输入数据的特征是(x0, x1, x2, ..., xn),我们在每个特征上乘以一个回归系数 (w0, w1, w2, ... , wn),然后累加得到sigmoid函数的输入z:
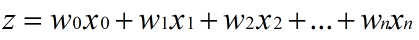
那么,输出就是一个在0~1之间的值,我们把输出大于0.5的数据分到1类,把输出小于0.5的数据分到0类。这就是Logistic回归的分类过程。
我们要做的,就是确定这个分类器中的最佳回归系数,即(w0, w1, w2, ... , wn)
上面这个公式可以写成下面这样的形式。其中w是行向量,x是列向量。x是分类器的输入数据,w是回归系数。

哦对了,顺便说一句,sigmoid函数的导数挺有趣的:

可以自行验证一下。
-------------------------------------------------------------------------------------
梯度上升法
现在我们就去找最佳参数w。方法用的是最优化算法,这里首先介绍其中一种:梯度上升法。
它的思想是:要找到某个函数的最大值,最好最快的方法就是沿着函数的梯度方向探寻。如果梯度记为▽(读作“Nabla”),那么函数f(x,y)的梯度由下式表示:
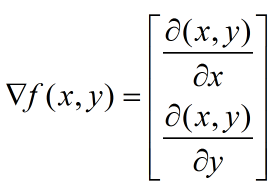
其中,函数f(x,y)必须要在带计算的(x,y)点上有定义,并且可微。
梯度上升法其实类似于“爬山”的过程,我们想到达这座山的最高点,每次前进一小步,每到一个点的时候,都希望能找到最佳的移动方向(即上面所计算的梯度),并按照这个方向前进下一步。画个图就明白了:
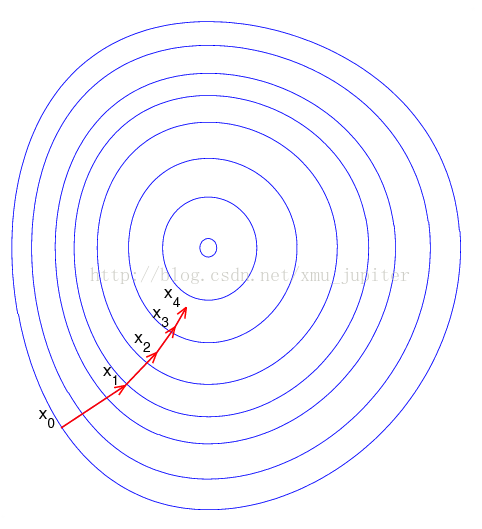
假设我们从x0这个点开始,然后想接近中心的那个最高点。那么首先计算x0点的梯度,移动到X1点。然后计算X1点的梯度,移动到X2.....如此循环迭代,直到满足停止条件。
那么,梯度为什么总是代表最佳的移动方向呢?因为,它求的是函数关于各个变量的偏导数,所以它总是代表函数值增长最快的方向。
说到这里只定义了移动方向,而没定义每次移动的距离。我们把这个距离称为“步长”,记做 α
用向量来表示的话,梯度上升法的迭代公式如下:

它其实就是在不断的更新我们要找的回归系数w。这个公式会不断迭代执行,直到达到了迭代次数,或算法达到了某个事先设定的允许误差范围。
现在问题是,这个公式是怎么来的?步长 × 函数f(w)的梯度 ,然后加到原来的w上就得到了新的w,是这么个道理没错。不过f(w)这个函数到底指的是什么呢?难道就是作为预测函数的sigmoid吗?


作者根本没讲啊!作者根本没讲啊!作者根本没讲啊!
入门教程也不用入成这个样子吧!
好吧,我们直接去看代码吧,也许能有点启示
这个例子是这样的:有100个样本点,每个样本点有2个数值型特征:X1和X2,分类的种数为2种:0和1
数据集长这样:

上代码:
from numpy import *
def loadDataSet():
dataMat = []; labelMat = [] #训练数据集,标签List
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #分别是X0,X1,X2
labelMat.append(int(lineArr[2])) #标签
return dataMat, labelMat
def sigmoid(z):
return 1.0/(1+exp(-z))
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #100 * 3的矩阵
labelMat = mat(classLabels).transpose() #100 * 1的列向量
m, n = shape(dataMatrix) #行数(样本数:100)、列数(特征数:3)
alpha = 0.001 #目标移动的步长
maxCycles = 500 #迭代次数
weights = ones((n,1)) #初始回归系数。3*1的列向量,每个系数初始化为1.0。weights为numpy.matrix型
for k in range(maxCycles): #循环500次
h = sigmoid(dataMatrix*weights) #矩阵乘法:每个样本的特征值×系数,拔得出来的值作为sigmoid函数输入
error = (labelMat - h) #计算每个样本的sigmoid输出与标签的差值
weights = weights + alpha * dataMatrix.transpose()* error #仍然懵逼
return weights
loadDataSet用来从文本里面获取样本数据集和样本标签。要注意的是第8行,人为地给每个样本多加了一个特征X0,且设置值为1.0
gradAscent就是梯度上升法训练过程的函数。
样本数据集是DataMatIn;标签List经过转置(transpose)后变成了列向量;weights是列向量,包含了3个回归系数,初始化为1.0:

然后看循环里面的内容:
h计算的是每个样本特征乘以系数并累加后,作为sigmoid函数的输入得到的输出。是个100*1的列向量
error是计算h中每个值与labelMat中对应值的误差:

然而!然而!然而!最关键的倒数第2行代码仍然看不懂啊!
我们把这行代码和之前那条让人懵逼的公式对照来看一下:
weights = weights + alpha * dataMatrix.transpose()* error

这样看来...样本数据集的矩阵转个置,再乘上error,就是f(w)的梯度了。所以...f(w)到底长什么样子呢???
先不管那么多,我们先看一下按照这样的做法,更新w到底有没效果吧。我们关注的是预测出的分类与真实标签的误差,即error。error里面有100项,我们就取一项error[0]来观察一下。我们在倒数第2行的前面,加一句:
print '第 {} 次循环,error[0]= {}'.format(k + 1, error[0])看下结果:
dataMat, labelMat = loadDataSet()
gradAscent(dataMat, labelMat)

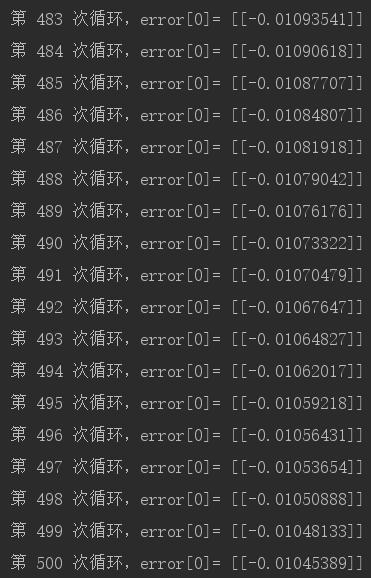
从数量级可以看出,error从最初的一个负值,不断地接近0,也就是说,误差越来越小。
所以,倒数第二行的代码是没问题的。但问题就是它和之前那条式子的含义到底是什么,这点我很想弄清楚。
然后,找啊找啊,就找到了这篇东西!里面有详细的推导过程!
-------------------------------------------------------------------------------------
梯度上升法 · 公式推导
很好。我们来解决心中的疑问,关于更新w的那条公式和那行代码,到底是怎样来的。
我们首先得了解代价函数(cost function)
代价函数,按照这位大神的说法,是“用于找到最优解的目的函数”
而按我的理解,在回归问题中,代价函数的作用,是评价算法所做的预测与实际类别(预测)之间的误差。
对于梯度上升法,它的一个较为合适的代价函数如下:
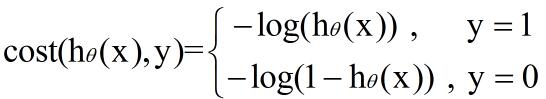
其中,hθ(x)就是算法所做出的预测,即,将训练样本的数据特征x与回归系数w(此处是用θ来表示)进行向量乘法,并作为sigmoid函数得到的输出。

y就是训练样本所对应的真正类别(标签)。
我们直观地可以看下这个代价函数的作用:当预测准确(即y=1且预测值h接近于1,或当y=0且h接近于0)时,cost接近于0,即误差接近于0;而当预测错误(即y=1而预测值h接近于0,或当y=0而h接近于1)时,cost就为趋于无穷大,即误差趋于无穷大。
我们可以将上面那个分段函数合并成一条式子:

以上是对于一条训练样本而言,评价出的预测误差。那么对于有m条训练样本的一个数据集而言,代价函数就变成这个样子,就是把所有样本的预测误差累加起来。我们用J(θ)来表示:
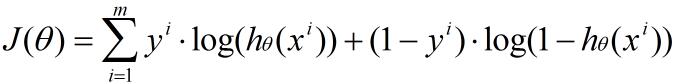
回到梯度上升法。我们希望这个代价函数的函数值向0趋近,所以求梯度,即J(θ)对回归系数θ的三项各自求偏导:
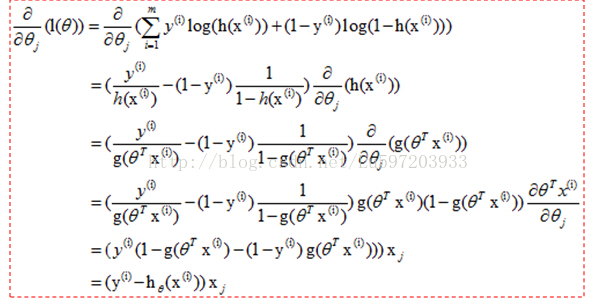
没啥复杂的。第2行后面那个小尾巴,是根据链式法则,hθ(xi)对θj求导。
第4行最后那儿:

当 j=0 时,就是对θ0求偏导,得到 . 其他两项也一样。
推导的结果里面没带上求和符号,所以结果就是:

至此,真相已经浮出水面了!

我们把上面这个梯度公式和那行代码对照来看一下:
weights = weights + alpha * dataMatrix.transpose()* error
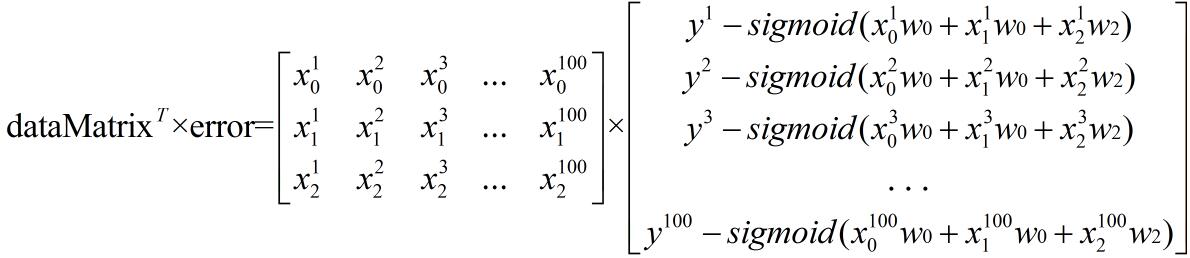
和梯度公式对照下,发现可以完全对上啊!
再看这条公式:
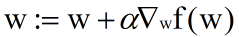
所以,f(w)指的其实是代价函数!
-------------------------------------------------------------------------------------
实例结果展示
我们来看下经过500次迭代更新后,最终的w是多少。
dataMat, labelMat = loadDataSet()
print gradAscent(dataMat, labelMat)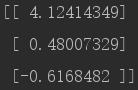
作为这篇又臭又长的博客的结尾,我们把所有数据点和分类界线在图里面给画出来。
def plotBestFit(dataMat, labelMat, weights):
import matplotlib.pyplot as plt
dataArr = array(dataMat) #将Numpy的matrix类型转为array类型
n = shape(dataArr)[0] #样本数:100
xcord1 = []; ycord1 = [] #标签为1的数据点的x坐标、y坐标
xcord2 = []; ycord2 = [] #标签为0的数据点的x坐标、y坐标
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') #s参数是数据点的粗细,marker是标记('s'是正方形,默认圆形)
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1) #直线的x坐标范围
y = (-weights[0]-weights[1]*x)/weights[2] #直线的方程
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()值得注意的是倒数第4行。我们有了最佳回归系数之后,就可以列出最佳拟合直线的方程。根据sigmoid函数的性质,横坐标为0处是两个分类(0和1)的分界线,所以令sigmoid函数的输入为0,就得到了分界线的方程:

其中x0是1,所以 x2=(-w0-w1x1) / w2
在图里面,令x1为横坐标,令x2为纵坐标,就能在图里把这条直线显示出来了。
dataMat, labelMat = loadDataSet()
weights=gradAscent(dataMat, labelMat)
plotBestFit(dataMat, labelMat, weights.getA()) #getA()函数将Numpy.matrix型转为ndarray型














 3019
3019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









