







目录
Logistic回归是一种最优化算法。用一条直线对一些数据点进行拟合的过程被称为回归。利用Logistic回归进行分类的主要思想是:根据现有数据利用Logistic回归生成最佳拟合线,并以此作为数据的分类边界线。逻辑回归假设数据服从伯努利分布,通过极大似然估计的方法,运用梯度下降来求解参数,来达到数据二分类的目的。
Sigmoid函数
若要处理的是二分类问题,我们期望的函数输出会是0或1,类似于单位阶跃函数,可是该函数是不连续的,不连续不可微。

因此我们换一个函数——Sigmoid函数,当x=0时,y为0.;随着x的增大,y值趋近于1,随着x的减小,y趋近于0,当横坐标足够大时,Sigmoid函数就会看起来像一个阶跃函数。

而Sigmoid函数,它的输入会是如下线性模型:
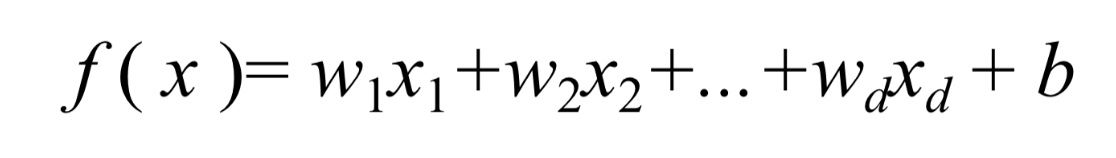
若采用向量的写法,上述公式可以写为 :
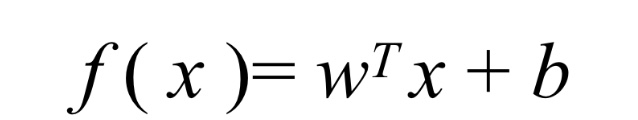
其中,向量x是分类器的输入数据,向量w,b为待求解系数,我们称其为线性回归,线性回归的目的就是学习一个线性模型以尽可能准确地预测实值输出标记(f(xi)~yi),为了得到最佳系数,需要用到最优化理论的一些知识。
最小二乘法(线性模型)
数据是一维的
我们的学习目标就是:

关于上式,分别对w和b求导,可得:

数据是多维的
我们有相同的目的,但要把w和b整合成向量形式:
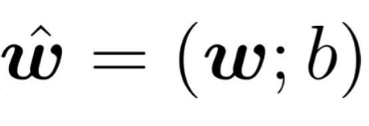
这是我们最小二乘法出来的式子,向量的平方和= 一个行向量*一个列向量:
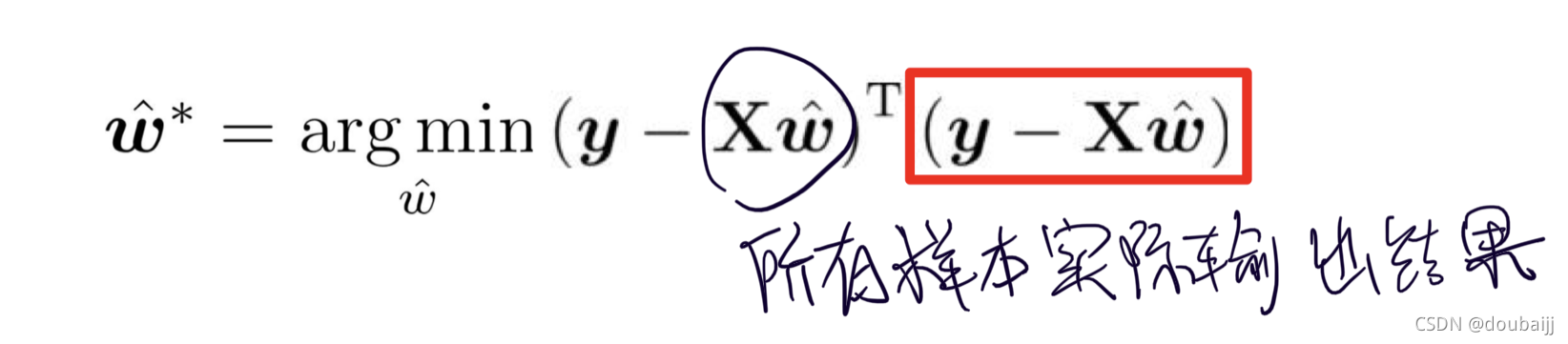
根据上式对w求导,可得w的解析解;计算整理会得到下式:
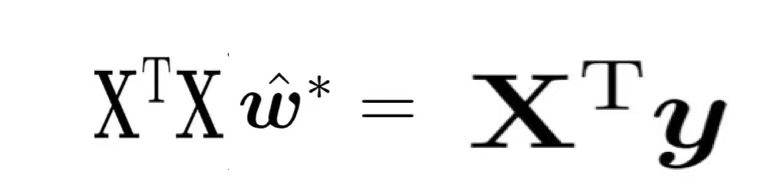

对数线性回归(非线性模型)
我们拿到的数据有时并不满足线性回归模型,这时我们就可以推广至:
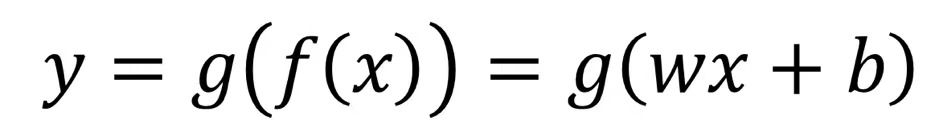
注意:函数g一定式单调可微的。
假设实例所对应的输出标记是在指数尺度上变化,那我们就可以将输出标记的对数作为线性模型逼近的目标,则:

极大似然估计
我们的Sigmoid函数就不是常规的线性模型,我们的目标同样是求解未知参数w、b,这时我们也不能用线性模型里提到的的最小二乘法,而应该使用极大似然估计法。
至于为什么,我参考了一些资料:最小二乘法的目标函数是非秃函数,有很多局部最优解,不利于求解;而最大似然估计的目标函数就是对数似然函数,是关于(w,b)的高阶连续可导凸函数,可以方便通过一些凸优化算法求解,比如梯度下降法、牛顿法等。
极大似然估计就是根据已知结果去反推最大概率导致该已知结果的参数。这正是我们需要的求参过程。

假设数据服从伯努利分布,以下是一部分的求解过程(为了降低计算难度,通常会采用对数加法替换概率乘法):


因此我们的求参步骤如下:
- 写出似然函数
- 对似然函数取对数,并整理
- 求导数,令导数为0,得到似然方程
- 解似然方程,得到的参数即为所

引入一个知识点,样本作为正例的相对可能性的对数(正例的可能性和负例的可能性的比值的对数),被称为对数几率:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









