







 本文分析了O2O优惠券的数据,发现线下优惠券核销率低,主要因素包括满减门槛、折扣额度和门店距离。7%的优惠券被使用,其中79%的用户对优惠券不敏感。优惠券拉新效果有限,但小额满减和近距离门店的优惠券核销率较高。建议关注优惠券类型和用户营销。
本文分析了O2O优惠券的数据,发现线下优惠券核销率低,主要因素包括满减门槛、折扣额度和门店距离。7%的优惠券被使用,其中79%的用户对优惠券不敏感。优惠券拉新效果有限,但小额满减和近距离门店的优惠券核销率较高。建议关注优惠券类型和用户营销。
写在前面的话
本文的数据分析任务是我在几个月前为了准备面试锻炼自己的数据分析思路做的,项目中没有涉及到机器学习建模内容,是一个单纯用数据得出结论的任务。因为准备时间仓促,所以项目里待完善的内容很多。最后机缘巧合也没有去应聘数据分析师的工作,因此想把这个项目分享出来,希望对想准备数据分析面试的读者有所帮助。本文的数据集来自天池中一个O2O优惠券核销率预测的比赛,感兴趣的读者可以自行下载相关数据集。
数据介绍
本文所使用的数据集是关于O2O营销活动优惠券发放的,提供的数据集包括线上和线下两部分。在线下数据集中包括用户id,商家id,优惠券id,折扣率,用户经常活动地点离最近商家距离,收到优惠券的日期以及核销优惠券的日期。线上数据集中除了线上数据集中提供的信息外还提供了用户的线上行为,包括点击,购买和领取,但线上数据集不提供距离信息。在本次数据分析任务中我分成了三步对优惠券的核销行为进行分析,分别是线下行为,线上行为和线上线下共同用户的行为。
线下行为
首先导入本次分析任务要用到的所有python library。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import statsmodels.stats as sms
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.stattools import adfuller
import plotly.express as px
from plotly import graph_objects as go数据清洗
# 读取线下数据集
offline_df=pd.read_csv('/content/drive/MyDrive/o2o/ccf_offline_stage1_train.csv')
offline_df.head()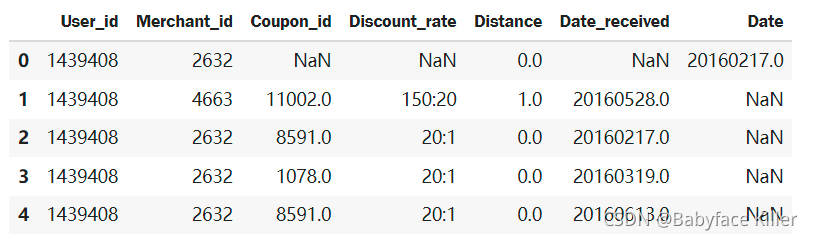
上面展示的就是线下数据集包含的字段。
print('线下消费行为数据{}行'.format(offline_df.shape[0]))![]()
# 数据清洗
# 每个字段缺失值
offline_df.isnull().sum() 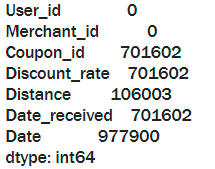
首先我们可以看到数据集里面缺失值还是非常多的,那么为什么会出现这些缺失值呢?从上面缺失字段的统计可以发现Coupon_id, Discount_rate, Date_received三者确实数量一致符合数据逻辑,即没有领取优惠券的消费记录中不含有这三条信息。而Distance出现缺失值说明不能提供用户的位置信息,可能用户关闭了定位功能或用户活动范围内没有最近的门店。Date出现缺失值就说明用户在产生领取行为后没有核销优惠券。
根据我们之前分析的缺失值出现原因,分别制定不同的填充缺失值策略。对于没有领取优惠券的消费,我们可以把Coupon_id, Discount_rate填补为0且填补值不与这两个字段中其他取值冲突。因为Distance的取值为0-10,所以对于Distance的缺失值我们可以填充为11。
offline_df['Coupon_id'].fillna(0,inplace=True)
offline_df['Discount_rate'].fillna(0,inplace=True)
offline_df['Distance'].fillna(11,inplace=True)
offline_df.dtypes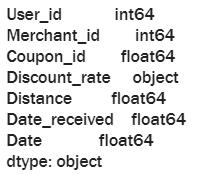
通过观察数据类型,我们会发现有些字段的数据类型不太合理,比如Coupon_id, Distance,Date_received 和 Date。我们可以手动来转换这些字段的数据类型:
# 转换逻辑:Coupon_id及Distance应为整数型取值数据,Date_received和Date应为日期型数据
convert_dict={'Coupon_id':'int64','Distance':'int64'}
offline_df=offline_df.astype(convert_dict)
offline_df['Date_received']=pd.to_datetime(offline_df['Date_received'],format='%Y%m%d')
offline_df['Date']=pd.to_datetime(offline_df['Date'],format='%Y%m%d')接下来,我们把没有核销优惠券的日期填充为自定义的dummy date,在这里我使用的是2021-01-01,因为数据集中的数据都是2016年的所以当然不会出现2021年的日期,也可以使用其他的日期来填充。
# 将没有消费的日期和没有领取优惠券的日期填充为dummy date
offline_df['Date_received'].fillna('2021-01-01',inplace=True)
offline_df['Date'].fillna('2021-01-01',inplace=True)
offline_df['Date_received']=pd.to_datetime(offline_df['Date_received'])
offline_df['Date']=pd.to_datetime(offline_df['Date'])我们再来观察一下清理后的数据集:
offline_df.head() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









