







等概率生成
rand5生成rand3
现在有一个Rand5函数,可以生成等概率的[0, 5)范围内的随机整数,要求利用此函数写一个Rand3函数(除此之外,不能再使用任何能产生随机数的函数或数据源),生成等概率的[0, 3)范围内的随机整数。
思路是:
生成0-4的概率是相同的,进一步,生成0-2的概率也是相同的,这就满足了等概率的条件了。
int Rand3() {
int x;
do {
x = Rand5();
} while (x >= 3);
return x;
}rand3生成rand5
类似的,虽然3比5小,但是可以通过x = Rand3()*3 + Rand3()的方式,产生0-8的随机数。这样一来,总的可能情况9就比5要大了,然后采用上面类似的方法。
int Rand5() {
int x;
do {
x = Rand3()*3 + Rand3();
}
while (x >= 5);
return x;
}rand_m生成rand_n
归纳总结:将这个问题进一步抽象,已知random_m()随机数生成器的范围是[0, m),求random_n()生成[0, n)范围的函数,m < n && n <= m *m。
设t为n的最大倍数,且满足t<m*m,即 t = ((m*m)/n)*n。
int Rand_n() {
int x;
t = ((m * m) / n) * n;
do {
x = Rand_m() * m + Rand_m ();
} while (x >= t);
return x % n;
}不等概率生成
rand以不等概率生成0和1, 如何以1/n的等概率产生1~n之间的任意一个数?
已知随机函数rand(),以p的概率产生0,以1-p的概率产生1,现在要求设计一个新的随机函数newRand(),使其以1/n的等概率产生1~n之间的任意一个数。
思路:
可以通过已知随机函数rand()产生等概率产生0和1的新随机函数Rand(),然后调用k(k为整数n的二进制表示的位数)次Rand()函数,得到一个长度为k的0和1序列,以此序列所形成的整数即为1–n之间的数字。
注意:从产生序列得到的整数有可能大于n,如果大于n的话,则重新产生直至得到的整数不大于n。
第一步:由rand()函数产生Rand()函数,Rand()函数等概率产生0和1。
这是因为01和10出现的概率都是p*(1-p),所以可以看做是等概率事件。
int Rand() {
while(1) {
int i1 = rand();
int i2 = rand();
if(i1 == 0 && i2 == 1)
return 1;
else if(i1 == 1 && i2 == 0)
return 0;
}
}第二步:计算整数n的二进制表示所拥有的位数k,k = 1 +log2n(log以2为底n)
第三步:调用k次Rand()产生随机数,产生的k个01序列表示1-n之间的数。
int newRand() {
while(1) {
int result = 0;
int k=log2(n)+1;//bit位数
//生成k次
for(int i = 0 ; i < k ; ++i)
if(Rand() == 1)
result |= (1 << i);
//如果result<n,说明0-n-1的概率是等概率事件
if(result < n)
return result+1;
}
}蓄水池抽样问题
给出一个数据流,这个数据流的长度很大或者未知。并且对该数据流中数据只能访问一次。请写出一个随机选择算法,使得数据流中所有数据被选中的概率相等。
思路:
首先从最简单的例子出发:数据流只有一个数据。我们接收数据,发现数据流结束了,直接返回该数据,该数据返回的概率为1。
看来很简单,那么我们试试难一点的情况:假设数据流里有两个数据。我们读到了第一个数据,这次我们不能直接返回该数据,因为数据流没有结束。我们继续读取第二个数据,发现数据流结束了。因此我们只要保证以相同的概率返回第一个或者第二个数据就可以满足题目要求。因此我们生成一个0到1的随机数R,如果R小于0.5我们就返回第一个数据,如果R大于0.5,返回第二个数据。
接着我们继续分析有三个数据的数据流的情况。为了方便,我们按顺序给流中的数据命名为1、2、3。我们陆续收到了数据1、2和前面的例子一样,我们只能保存一个数据,所以必须淘汰1和2中的一个。应该如何淘汰呢?不妨和上面例子一样,我们按照二分之一的概率淘汰一个,例如我们淘汰了2。继续读取流中的数据3,发现数据流结束了,我们知道在长度为3的数据流中,如果返回数据3的概率为1/3,那么才有可能保证选择的正确性。也就是说,目前我们手里有1,3两个数据,我们通过一次随机选择,以1/3的概率留下数据3,以2/3的概率留下数据1。那么数据1被最终留下的概率是多少呢?
数据1被留下:(1/2)*(2/3) = 1/3
数据2被留下概率:(1/2)*(2/3) = 1/3
数据3被留下概率:1/3
这个方法可以满足题目要求,所有数据被留下返回的概率一样!
因此,我们做一下推论:
假设当前正要读取第n个数据,则我们以1/n的概率留下该数据,否则留下前n-1个数据中的一个。
以这种方法选择,所有数据流中数据被选择的概率一样。
海量数据
在海量数据中,基本的思路是分治。我们还应该关心数据的具体特性,如果数据的取值范围已知了,那儿可以采用桶排序的思想,因为后续归并每个桶时只需要顺序处理就行了;如果数据是正整数,而且不重复,那么直接使用位图排序。
两个文件中相同的数据记录
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:利用hash求模分治
可以估计每个文件安的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 遍历文件a,对每个url求取
hash(url)%1000,然后根据结果将url分别存储到1000个小文件中。这样每个小文件的大约为300M。 - 遍历文件b,采取相同的方式将url分别存储到另外1000个小文件中。这样处理后,所有可能相同的url都在对应的小文件中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
- 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2
如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否存在(注意会有一定的错误率)。
10个文件中分别存放了query记录,统计其频度
有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
思路:
- 顺序读取10个文件,按照hash(query)%10的结果将query写入到新的10个文件中。
- 对于10个新的文件,用hash_map(query, query_count)来统计每个query出现的次数。
- 利用快速/堆/归并排序,按照query_count进行排序。这样又得到了10个排好序的文件。
- 对10个排好序的新文件进行归并排序。
统计词频为top100的单词
一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
思路:
- 顺序读文件,对于每个词x,取
hash(x)%5000,然后按照该值存到5000个小文件中。这样每个文件大概是200k左右。 - 对每个小文件,用堆排序取出词频为top100的单词。然后另存一个小文件。这样又得到了5000个小文件。
- 把这5000个小文件进行归并处理,取出真正的top100的单词。
海量日志,找出访问百度次数最多的IP
- 首先把访问百度的日志中的IP取出来,注意到IP是32位的,最多有
2^32个,所以还是采用hash(ip)%1000的方法,把所有记录映射到1000个小文件; - 在每个小文件中,分别找出频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的1个)。
- 在这1000个最大的IP中,找出那个频率最大的IP。
在2.5亿个整数中找出不重复的整数
注意:内存不足以容纳这2.5亿个整数。
思路:
方案1
- hash取模,分别映射到1000个小文件中;
- 在每个小文件中,找到不重复的整数;
- 汇总所有不重复的整数。
方案2
采用位图法,但是给每个数分配2位,00表示不存在,01表示出现一次,10表示多次,11无意义。共需内存2^32 * 2 / 8 = 1GB内存,还可以接受。
- 顺序扫描这2.5亿个整数,查看并更新位图中中对应的位,如果是00变01,01变10,10保持不变。
- 扫描完以后,依次查看bitmap,把对应位是01(表示只出现过一次)的整数输出。
ps:其实给每个数只分配1位,在扫描时发现已经为1时,直接输出,这样也行。。
海量数据分布在100台电脑上,统计出次数top10的数据
- 首先用堆排序,在每台电脑上求出top10。
- 把每台电脑上的top10组合起来,一共1000个数据,再用一次堆排序,求出总的top10。
寻找热门搜索
搜索引擎会通过日志文件把用户每次搜索使用的查询串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复度比较高,虽然总数是1千万,但是如果去除重复的,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
思路:
- 先采用trie树,关键字域保存该查询串出现的次数,没有出现为0。
- 用大小为10的最小堆来找到频率最高的10个查询串。
n台电脑,每台存有n个数,找到n^2个数中的中位数
思路:
- 先大体估计一下这些数的范围,假设这些数都是32位无符号整数(共有2^32-1个)。我们把0到2^32-1的整数划分为n个范围段,可看作n个桶;
- 扫描每台电脑上的n个数,根据每个数所属的范围段映射到第i台电脑上;注意这个过程中,每台电脑上存储的数应该是O(N)的。
- 依次统计每台电脑上,范围段的总个数,并顺序累加,直到找到第k台电脑,在该电脑上累加的数大于或等于
n^2 / 2,而在第k-1台电脑上的累加数小于n^2 / 2,并把这个数记为x。那么我们要找的中位数就在第k台电脑上,并排在第n^2/2 - x位。 - 对第k台电脑上的的数进行排序,并找出第
n^2/2 - x位的数,即为所求。
设计一个秒杀系统
什么是秒杀
秒杀场景一般会在电商网站举行一些活动或者节假日在12306网站上抢票时遇到。对于电商网站中一些稀缺或者特价商品,电商网站一般会在约定时间点对其进行限量销售,因为这些商品的特殊性,会吸引大量用户前来抢购,并且会在约定的时间点同时在秒杀页面进行抢购。
秒杀系统场景特点
秒杀时大量用户会在同一时间同时进行抢购,网站瞬时访问流量激增。
秒杀一般是访问请求数量远远大于库存数量,只有少部分用户能够秒杀成功。
秒杀业务流程比较简单,一般就是下订单减库存。
秒杀架构设计理念
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。
削峰:对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有利用缓存和消息中间件等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
内存缓存:秒杀系统最大的瓶颈一般都是数据库读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
可拓展:当然如果我们想支持更多用户,更大的并发,最好就将系统设计成弹性可拓展的,如果流量来了,拓展机器就好了。像淘宝、京东等双十一活动时会增加大量机器应对交易高峰。
架构方案
一般秒杀系统架构:
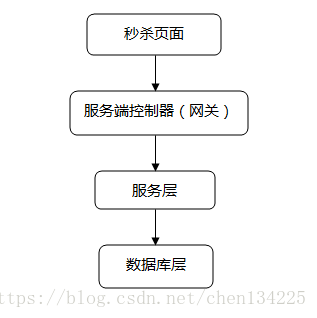
设计思路
将请求拦截在系统上游,降低下游压力:秒杀系统特点是并发量极大,但实际秒杀成功的请求数量却很少,所以如果不在前端拦截很可能造成数据库读写锁冲突,甚至导致死锁,最终请求超时。
充分利用缓存:利用缓存可极大提高系统读写速度。
消息队列:消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程,后台业务根据自己的处理能力,从消息队列中主动的拉取请求消息进行业务处理。
前端方案
浏览器端(js):
页面静态化:将活动页面上的所有可以静态的元素全部静态化,并尽量减少动态元素。通过CDN来抗峰值。
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求,比如可以采取IP限流
后端方案
服务端控制器层(网关层):
限制uid(UserID)访问频率:我们上面拦截了浏览器访问的请求,但针对某些恶意攻击或其它插件,在服务端控制层需要针对同一个访问uid,限制访问频率。
服务层:
上面只拦截了一部分访问请求,当秒杀的用户量很大时,即使每个用户只有一个请求,到服务层的请求数量还是很大。比如我们有100W用户同时抢100台手机,服务层并发请求压力至少为100W。
采用消息队列缓存请求:既然服务层知道库存只有100台手机,那完全没有必要把100W个请求都传递到数据库啊,那么可以先把这些请求都写到消息队列缓存一下,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
利用缓存应对读请求:对类似于12306等购票业务,是典型的读多写少业务,大部分请求是查询请求,所以可以利用缓存分担数据库压力。
利用缓存应对写请求:缓存也是可以应对写请求的,比如我们就可以把数据库中的库存数据转移到Redis缓存中,所有减库存操作都在Redis中进行,然后再通过后台进程把Redis中的用户秒杀请求同步到数据库中。
数据库层:
数据库层是最脆弱的一层,一般在应用设计时在上游就需要把请求拦截掉,数据库层只承担“能力范围内”的访问请求。所以,上面通过在服务层引入队列和缓存,让最底层的数据库高枕无忧。
案例:利用消息中间件和缓存实现简单的秒杀系统
Redis是一个分布式缓存系统,支持多种数据结构,我们可以利用Redis轻松实现一个强大的秒杀系统。
我们可以采用Redis 最简单的key-value数据结构,用一个原子类型的变量值(AtomicInteger)作为key,把用户id作为value,库存数量便是原子变量的最大值。对于每个用户的秒杀,我们使用 RPUSH key value插入秒杀请求, 当插入的秒杀请求数达到上限时,停止所有后续插入。
然后我们可以在台启动多个工作线程,使用 LPOP key 读取秒杀成功者的用户id,然后再操作数据库做最终的下订单减库存操作。
当然,上面Redis也可以替换成消息中间件如ActiveMQ、RabbitMQ等,也可以将缓存和消息中间件 组合起来,缓存系统负责接收记录用户请求,消息中间件负责将缓存中的请求同步到数据库。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









