







目录
一、AutoGPT理念与应用
1. AutoGPT的价值
在 ChatGPT 问世之后,大家很容易就发现其依然具备一些很难解决的问题,比如:
- Token 超出限制怎么办?(目前最新的 GPT4 支持最多8,192 tokens)
- 如何完全自动化?任务需要多步串联,仍需要人工介入
- 如何集成外部能力?比如搜索,运行脚本、爬取网站等等
- 无法获取最新数据怎么办?最新的GPT4的训练数据时效为Sep 2021
而 AutoGPT 的目标就是基于 GPT4 将 LLM 的 "思想 "串联起来,自主地实现你设定的任何目标。
一句话来说,AutoGPT 是一个全能助手。只需要告诉其任务目标,他会自动完成中间可能涉及的一系列子任务,最终实现任务目标。
AutoGPT 可以实现阅读、写作,以及网页浏览的功能,它能够根据任务目标自己创建 prompt,然后再来完成这个任务。
- AutoGPT官网:https://github.com/Significant-Gravitas/Auto-GPT/
2. 应用场景
AutoGPT 官网显示,它能做到的事情主要为:
- 获取搜索和信息的互联网接入
- 长期和短期内存管理
- 使用 GPT-4 实例进行文本生成
- 访问流行的网站和平台
- 使用 GPT-3.5 进行文件存储和摘要
AutoGPT 支持以下多种安装方式:Docker、Git
- 安装官方文档:AutoGPT Documentation

3. 安装AutoGPT
以Windows操作系统Git方式为例,根据官方安装文档进行环境安装,步骤如下:
- AutoGPT官网下载auto-gpt源码文件(stable分支)

- OpenAi官网获取 Api Key(https://platform.openai.com/account/api-keys)

- 进入项目,复制配置文件
cp .env.template .env(复制.env.template文件并重命名为.env),修改配置文件中的OPENAI_API_KEY字段,设置为自己的API KEY和设置反向代理服务

4. 启动AutoGPT
- python -m venv venvAutoGPT (生成一个env,实现隔离环境)

- venvAutoGPT\Scripts\activate (启动env环境)
- python -m ensurepip --default-pip (在env环境升级packages)

- 进入AutoGPT-stable目录下执行:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
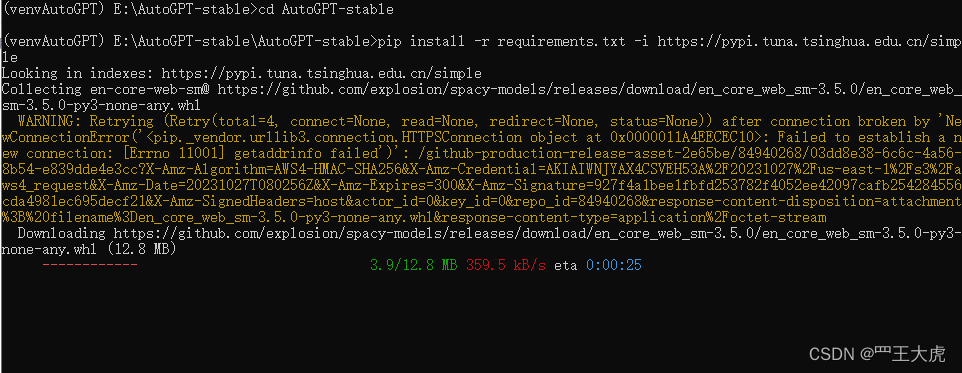
安装过程中报错,检查到本地计算机没有安装Git,需要安装并配置PATH:
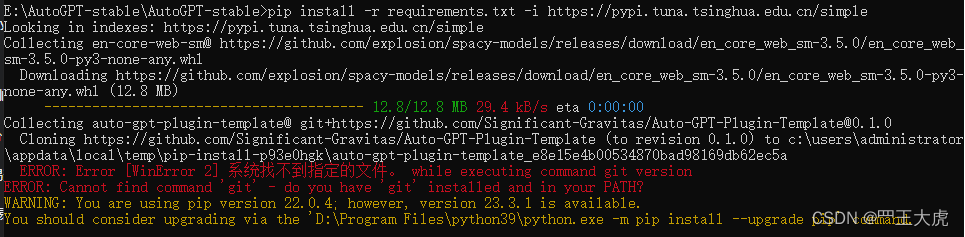
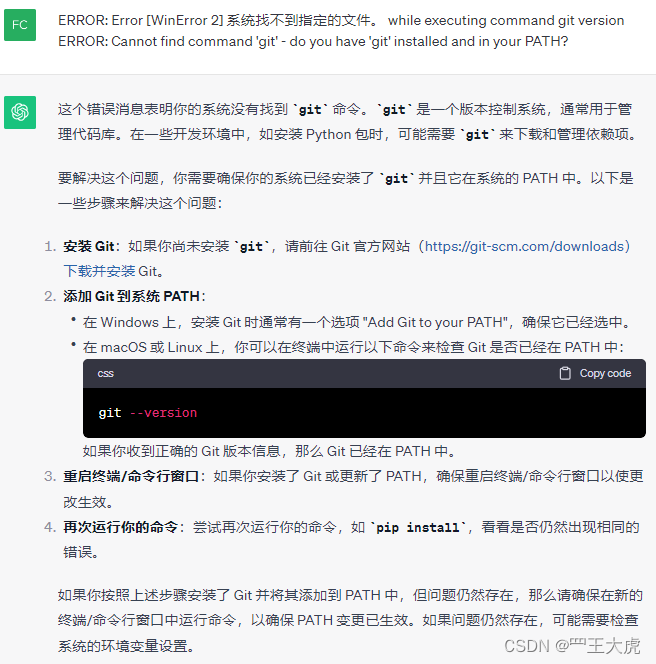
根据提示,安装git工具(Git - Downloads)并配置PATH可以解决上述问题,再重新执行pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 从指定的镜像源下载并安装依赖包。

检测到本地计算机安装的Python版本为3.9,AutoGPT依赖的Python版本不能低于3.10,需要升级Python:


再cd到对应目录下,重新执行升级命令,如下:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

- .\run.bat (启动AutoGPT)

AutoGPT会缓存上一次的问题,重新打开时会询问你是否需要继续上一次操作。AutoGPT会接入互联网,获取最新的搜索和信息,也可以对结果进行文本生成。AutoGPT是一个全能助手,可以打造和定制化属于自己的人工智能工具。
二、ChatGPT 插件开发
ChatGPT 不仅仅只是具备一个聊天机器人的功能。在其开放了 api 之后,就可以将 GPT 模型强大的能力轻松的通过 API 调用的方式使用,在掌握 ChatGPT api 的基础使用的同时,也可以为后续学习 LangChain 打下重要的基础。
1. 官方学习文档
官方文档:https://platform.openai.com/docs/guides/gpt/chat-completions-api
官方示例代码:https://github.com/openai/openai-cookbook/
2. 环境准备
OpenAi 第三方库,openai 提供了一个封装的非常完备的 python 库,可以直接使用 pip 安装:pip install openai。创建好自己的Token:https://platform.openai.com/account/api-keys。注意调用 API 是收费的,但是 OpenAI 已经为我们免费提供了5美元的用量。
3. OpenAi 接口调用
import openai
# API_key
openai.api_key = 'sk-WWo6UJeXXjScHO6qjTluXXXXXAAABBBCCC'
# 反向代理
openai.api_base = 'https://apitoken.XXXAAABBBCCC.com/openai/v1'
# 发送请求
response = openai.ChatCompletion.create(
# 指定请求模型
model='gpt-3.5-turbo',
# 请求消息体,列表中支持多条消息,可以将旧消息作为维持上下文信息的数据一并传入本次请求
messages=[
{"role": "user", "content": "作为资深测试工程师,怎么结合AI人工智能,提高研发团队效率?"},
]
)
answer = response['choices'][0]['message']['content']
print(answer)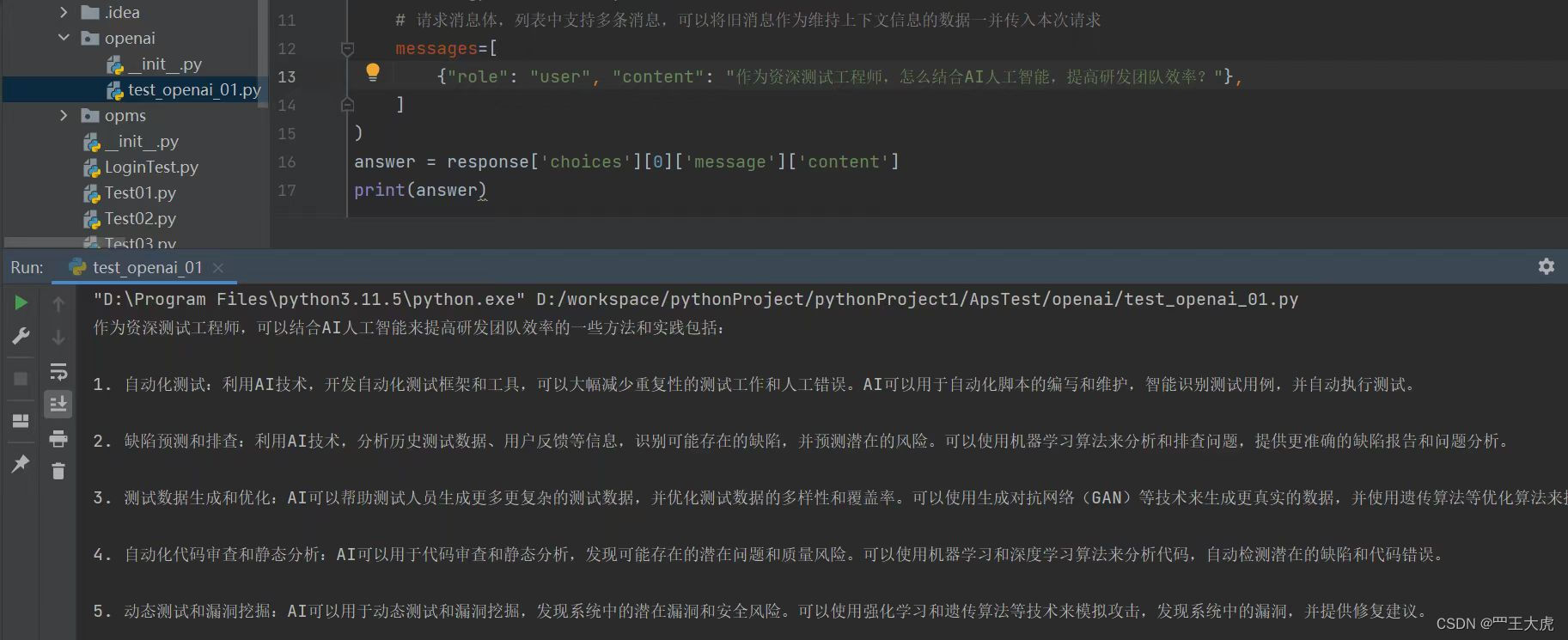
三、实现定制化AutoGPT
使用AutoGPT实现ChatGPT 无法实现的需求,比如直接生成文件;连接外网,查询信息,并生成Excel结果等。在使用AutoGPT时,提示词要明确一些,并且在过程中,需要不停的确认Command 是否正确,注意避免让AutoGPT 陷入死循环中。
1. 生成文件
使用过ChatGPT应该都知道ChatGPT只能生成文本类结果,是无法直接生成文件的。接下来就使用 AutoGPT 进行写入文件操作:
 AutoGPT会有一个思考的过程,并会将思考过程展示在终端中,提示要进行的下一步操作。生成好文件后,就可以终止任务,去本地的目录中看到对应的文件信息。
AutoGPT会有一个思考的过程,并会将思考过程展示在终端中,提示要进行的下一步操作。生成好文件后,就可以终止任务,去本地的目录中看到对应的文件信息。
2. 连接外网查询
AutoGPT 提示我们输入信息,输入提示词:查找2023年10月31日深圳的天气情况,生成一个shenzhen.txt文件,将天气结果写入其中。

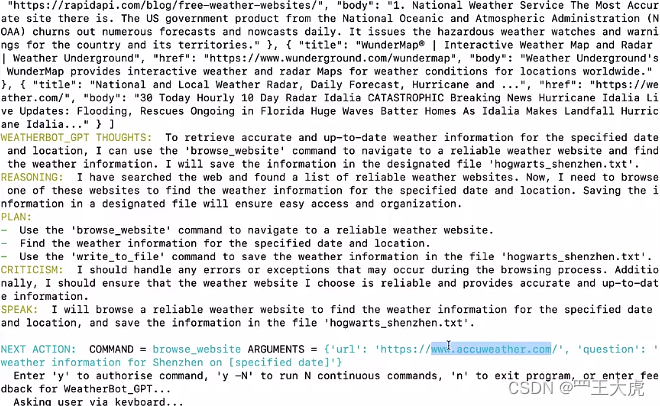
根据返回信息,选择对应的命令(Y/N)。最后可以看一下结果,成功生成一个shenzhen.txt文件,并且有天气的数据写入。
3. AutoGPT Command 原理
AutoGPT中提示的Command 其实只是一种由人类编写的程序函数,但它是提供给GPT调用的。比如谷歌搜索命令、文件操作命令、python执行命令等。这一点,从它的底层源码也不难发现。有了这些内容,GPT就知道它可以如何调用这些人类编写的函数,从而“获得”了网络访问能力和计算能力。
但是其实 AutoGPT 在火爆过一阵之后,发者们也发现了些问题,比如:
- 它可能会卡住,或者在一个已经有解任务中不停循环求解。
- 花费超出预期的token使用量。
越为复杂的场景, AutoGPT 处理起来可能愈发困难。但是Auto-GPT的底层原理并不复杂,它是依靠prompt实现的。如果作为一个比较有开发功底的人,如果我们想自己定制类似AutoGPT的效果,其实是比较容易的。后面继续学习基于LangChain的封装打造一个类似于AutoGPT 的人工智能应用工具。
四、知识拓展
1. 大模型应用开发-LangChain
GitHub - langchain-ai/langchain: ⚡ Building applications with LLMs through composability ⚡
2. 微调模型-fine-tuning
通过提供以下内容,微调可让您从 API 提供的模型中获得更多收益:
- 比即时设计更高质量的结果
- 能够训练比提示(prompt)中更多的例子
- 由于更短的提示(prompt)而节省了 tokens
- 更低的延迟请求
GPT-3 已经在来自开放互联网的大量文本上进行了预训练。当给出仅包含几个示例的提示(prompt)时,它通常可以凭直觉判断出您要执行的任务并生成合理的补全(completion)。这通常称为“小样本学习”。
微调通过训练比提示(prompt)中更多的示例来改进小样本学习,让您在大量任务中取得更好的结果。对模型进行微调后,您将不再需要在提示(prompt)中提供示例。这样可以节省成本并实现更低延迟的请求。
在高层次上,微调涉及以下步骤:
- 准备和上传训练数据
- 训练新的微调模型
- 使用您的微调模型
以上关于fine-tuning微调模型介绍信息,有兴趣的小伙伴可以详细查阅官网资料:
https://platform.openai.com/docs/guides/fine-tuning/
针对自己所在的领域,创建fine-tuning微调模型,利用微调模型分析自己公司的核心业务,分析公司的相关代码,创建符合公司业务场景的大模型。
3. 代码分析
- 源代码
- 架构图、流程图、时序图
- 挖掘bug
- 语法树分析
- 知识图谱
- 用例的分析、生成
运用大模型,可以将原始非结构化数据,导入到ChatGPT和 llama大模型中进行分析, 转化为知识图谱,在生成测试用例、自动化测试用例以及bug挖掘。
4. 知识图谱
4.1 什么是知识图谱?
知识图谱也称为语义网络,表示现实世界实体(即对象、事件、状况或概念)的网络,并说明它们之间的关系。 这些信息通常存储在图形数据库中,并以图形结构直观呈现出来,即为知识“图”。
一个知识图谱主要由三个部分组成:节点、边和标签。 任何对象、场所或人员都可以是节点。 边定义了节点之间的关系。例如,节点可以是客户(如A公司)和代理机构(如 B机构)。 边会将这种关系归类为 A公司 和 B机构 之间的客户关系。
知识图谱处理实体与实体之间产生的关联,而关联之间又会产生不同子任务。通过建立图模型,把所有信息建立联系,通过搜索引擎查询、计算,获得精准结果。知识图谱中的知识包含任何信息,如订单、客户、物流等信息都可以成为知识图谱中的知识。
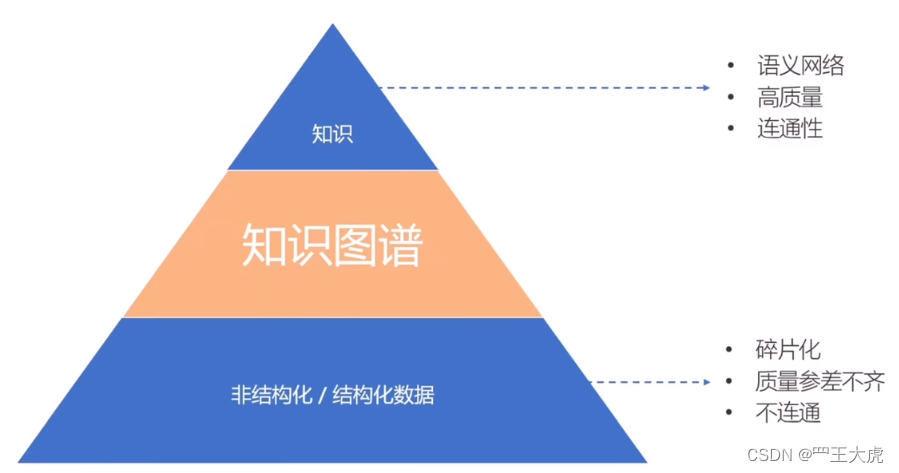
知识图谱分为两个主要的因素,顶点和边。而实体和关联又是知识图谱中两个非常核心的元素,知识图谱有了这两个元素,就能构建出一个完整的图谱来。一般情况下,实体和关联他们本身并不是一个单纯标签或者一个名词,他们都有属于他们自己的属性,尤其是实体,基本上所有的知识图谱里面实体都是有属性的,但不见得关联都有属性,有一些可能是关联本身并没有属性,只是有一个标签而已。
4.2 知识图谱的工作原理
知识图谱通常由不同来源的数据集组成,这些数据集的结构经常各不相同。 模式、身份和上下文协同工作,为不同的数据提供结构。 模式为知识图谱提供了框架,身份用于对底层节点进行了适当的分类,上下文则决定了知识的存在环境。 这些组件有助于区分具有多种含义的单词。 这使产品(例如 Google 的搜索引擎算法)能够确定 Apple(品牌)和 Apple(水果)之间的区别。
由机器学习驱动的知识图谱利用自然语言处理 (NLP),通过语义丰富过程构建节点、边和标签的综合视图。 在摄取数据时,这个过程使知识图谱能够识别单个对象,并理解不同对象之间的关系。 然后,将这些工作知识与其他相关和相似的数据集进行比较和整合。 知识图谱完成后,问答和搜索系统便能够检索和重用给定查询的综合答案。 虽然面向消费者的产品展示了其节省时间的能力,但同样的系统也可以应用于业务环境,由此避免了手动数据收集和集成工作,为制定业务决策提供支持。
围绕知识图谱的数据集成工作还可以支持创建新知识,可以在数据点之间建立联系,而这可能是以前一直未曾实现的。
4.3 知识图谱的作用

5. 开发技术
如果你想自己做一个人工智能AI的平台,那么你需要具备以下技能:
- 如何使用ChatGPT API
- 掌握编程语言(Python、Java)
- 具备工具开发技术栈 和 平台开发技术栈
工具开发,使用Python打包工具,上传至pip官网,也可以加上licence机制,进行商业化运作。
平台开发,掌握Flask 或 Django框架,快速搭建网站
Welcome to Flask — Flask Documentation (2.3.x)
6. 大模型应用开发
- 工具,whisper(语音识别工具),如给音频智能配字幕等
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
- 平台,代码分析平台、bug挖掘平台、用例生成平台
- SAAS服务,实现小助手在线提供服务,客户提供一个网页地址、提供一个app, 平台直接生成手工与测试用例、思维导图
- 后台任务 + 微调 + 知识图谱,实现精准测试、绩效分析、关联依赖分析
7. 大模型选择
- ChatGPT
- Llama 2
GitHub - facebookresearch/llama: Inference code for LLaMA models
- 清华开源大模型-chatGLM(双语对话语言模型 - 中文效果最佳)
GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
8. 部署私有化大模型
目前市面上比较成熟的大模型框架有ChatGPT、llama、以及chatGLM,ChatGPT比较的昂贵,当前最佳的选择方案是llama2模型,开放程度高。为何需要部署私有化大模型?主要是因为企业的代码不能对外,不能联网,所以需要根据公司的业务特点,搭建企业专属的私有化大模型。
部署私有化大模型基本要求:
- 软件方面(原始非结构化数据、大模型选择、知识图谱、应用)
- 硬件方面(显卡、闪存、等)
- 个人学习建议使用小型显卡:navida4090
- 企业级:CUDA (需要对模型进行微调和训练)

- 网站开发技术
- Flask 或 Django框架















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









