







卷积神经网络 (CNNs / ConvNets)
卷积神经网络和上一章讲的常规神经网络非常相似:它们都是由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。整个网络依旧是一个可导的评分函数:该函数的输入是原始的图像像素,输出是不同类别的评分。在最后一层(往往是全连接层),网络依旧有一个损失函数(比如SVM或Softmax),并且在神经网络中我们实现的各种技巧和要点依旧适用于卷积神经网络。
那么有哪些地方变化了呢?卷积神经网络的结构基于一个假设,即输入数据是图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
卷积网络结构
神经网络的输入是一个向量,然后在一系列的隐层中对它做变换。每个隐层都是由若干的神经元组成,每个神经元都与前一层中的所有神经元连接。但是在一个隐层中,神经元相互独立不进行任何连接。最后的全连接层被称为“输出层”,在分类问题中,它输出的值被看做是不同类别的评分值。
常规神经网络对于大尺寸图像效果不尽人意。在CIFAR-10数据集中,图像的尺寸是 32∗32∗3 (宽高均为32像素,3个颜色通道),因此,对应常规神经网络的第一个隐层中,每一个单独的全连接神经元就有 32∗32∗3=3072 个权重。这个数量看起来还可以接受,但是很显然这个全连接的结构不适用于更大尺寸的图像。举例说来,一个尺寸为 200∗200∗3 的图像,会让神经元包含 200∗200∗3=120,000 个权重值。而网络中肯定不止一个神经元,那么参数的量就会快速增加!显而易见,这种全连接方式效率低下,大量的参数也很快会导致网络过拟合。
神经元的三维排列。卷积神经网络针对输入全部是图像的情况,将结构调整得更加合理,获得了不小的优势。与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度(这里的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数)。
举个例子,CIFAR-10数据集中的图像是作为卷积神经网络的输入,该数据体的维度是 32∗32∗3 (宽度,高度和深度)。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。对于用来分类CIFAR-10数据集中的图像的卷积网络,其最后的输出层的维度是1x1x10,因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。下面是例子:
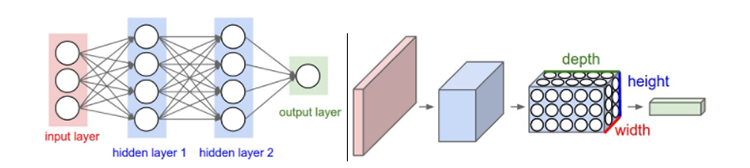
左边是一个3层的神经网络。右边是一个卷积神经网络,图例中网络将它的神经元都排列成3个维度(宽、高和深度)。卷积神经网络的每一层都将三维的输入数据变化为神经元三维的激活数据并输出。在这个例子中,红色的输入层装的是图像,所以它的宽度和高度就是图像的宽度和高度,它的深度是3(代表了红、绿、蓝3种颜色通道)。
卷积神经网络是由层组成的。每一层都有一个简单的API:用一些含或者不含参数的可导的函数,将输入的三维数据变换为三维的输出数据。
A ConvNet is made up of Layers. Every Layer has a simple API: It transforms an input 3D volume to an output 3D volume with some differentiable function that may or may not have parameters.
卷积网络的层结构
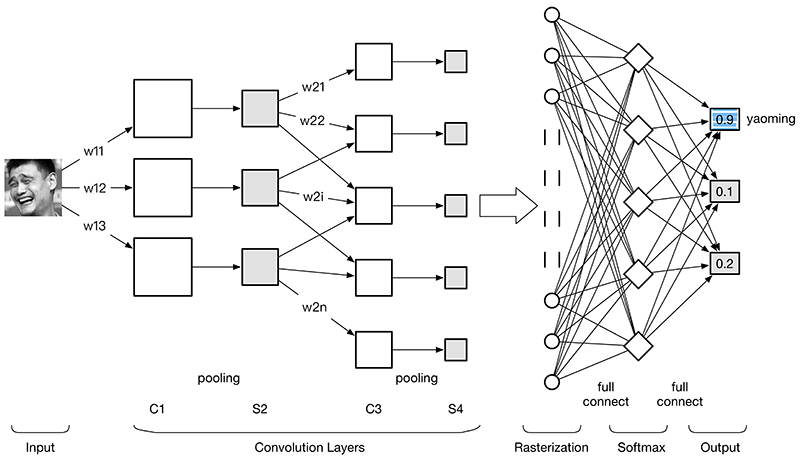
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。卷积神经网络主要由三种类型的层构成:卷积层,下采样层、全连接层。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。
输入 [32x32x3] 存有图像的原始像素值,本例中图像宽高均为 32,有 3 个颜色通道。
卷积层 中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用12个滤波器(也叫作核),得到的输出数据体的维度就是[32x32x12]。
ReLU层 将会逐个元素地进行激活函数操作,比如使用以0为阈值的max(0,x)作为激活函数。该层对数据尺寸没有改变,还是[32x32x12]。
下采样层 在在空间维度(宽度和高度)上进行降采样(downsampling)操作,数据尺寸变为[16x16x12],一般都是把图片长和宽度各缩小一半。
全连接层 将会计算分类评分,数据尺寸变为 [1x1x10],其中10个数字对应的就是CIFAR-10数据集中10个类别的分类评分值。正如其名,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
由此看来,卷积神经网络一层一层地将图像从原始像素值变换成最终的分类评分值。其中有的层含有参数,有的没有。具体说来,卷积层和全连接层对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数(神经元的突触权值和偏差)。而ReLU层和下采样层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
总结
简单案例中卷积神经网络的结构,就是一系列的层将输入数据变换为输出数据(比如分类评分)。
卷积神经网络结构中有几种不同类型的层(目前最流行的有卷积层、全连接层、ReLU层和下采样层)。
每个层的输入是三维数据,然后使用一个可导的函数将其变换为三维的输出数据。
有的层有参数,有的没有(卷积层和全连接层有,ReLU层和下采样没有)。
有的层有额外的超参数,有的没有(卷积层、全连接层和下采样层有,ReLU层没有)。



一个卷积神经网络的激活输出例子:
左边的输入层存有原始图像像素,右边的输出层存有类别分类评分。在处理流程中的每个激活数据体是铺成一列来展示的。因为对3D数据作图比较困难,我们就把每个数据体切成层,然后铺成一列显示。最后一层装的是针对不同类别的分类得分,这里只显示了得分最高的5个评分值和对应的类别。
卷积层
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量。
首先讨论的是,再没有大脑和生物意义上的神经元之类的比喻下,卷积层到底在计算什么。卷积层的参数是有一些可学习的滤波器集合构成的。每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据一致。举例来说,卷积神经网络第一层的一个典型的滤波器的尺寸可以是5x5x3(宽高都是5像素,深度是3是因为图像应为颜色通道,所以有3的深度)。在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(更精确地说是卷积),然后计算整个滤波器和输入数据任一处的内积。当滤波器沿着输入数据的宽度和高度滑过后,会生成一个2维的激活图(activation map),激活图给出了在每个空间位置处滤波器的反应。直观地来说,网络会让滤波器学习到当它看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的斑点,甚至可以是网络更高层上的蜂巢状或者车轮状图案。
在每个卷积层上,我们会有一整个集合的滤波器(比如12个),每个都会生成一个不同的二维激活图。将这些激活映射在深度方向上层叠起来就生成了输出数据。
以大脑做比喻:如果你喜欢用大脑和生物神经元来做比喻,那么输出的3D数据中的每个数据项可以被看做是神经元的一个输出,而该神经元只观察输入数据中的一小部分,并且和空间上左右两边的所有神经元共享参数(因为这些数字都是使用同一个滤波器得到的结果)。现在开始讨论神经元的连接,它们在空间中的排列,以及它们参数共享的模式。
局部连接:
在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的接受区域(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
例1:假设输入数据体尺寸为[32x32x3],如果感知域(或滤波器尺寸)是5×5,那么卷积层中的每个神经元会有输入数据体中 [5x5x3] 区域的权重,共 5x5x3=75 个权重(还要加一个偏差参数)。注意这个连接在深度维度上的大小必须为3,和输入数据体的深度一致。
例2:假设输入数据体的尺寸是 [16x16x20],感知域是 3×3,那么卷积层中每个神经元和输入数据体就有 3x3x20=180 个连接。再次提示:在空间上连接是局部的(3×3),但是在深度上是和输入数据体一致的(20)。
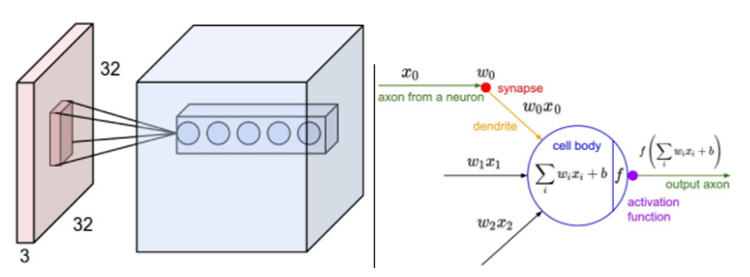
左边:红色的是输入数据体,蓝色的部分是第一个卷积层中的神经元。卷积层中的每个神经元都只是与输入数据体的一个局部在空间上相连,但是与输入数据体的所有深度维度全部相连(所有颜色通道)。在深度方向上有多个神经元(本例中5个),它们都接受输入数据的同一块区域(接受区域相同)。
右边:神经网络章节中介绍的神经元保持不变,它们还是计算权重和输入的内积,然后进行激活函数运算,只是它们的连接被限制在一个局部空间。
步长 和 Padding
空间排列:上文讲解了卷积层中每个神经元与输入数据体之间的连接方式,但是尚未讨论输出数据体中神经元的数量,以及它们的排列方式。3个超参数控制着输出数据体的尺寸:深度(depth),步长(stride)和零填充(zero-padding)。下面是对它们的讨论:
首先,输出数据体的深度是一个超参数:它和使用的滤波器的数量一致,而每个滤波器在输入数据中寻找一些不同的东西。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界,或者是颜色斑点激活。我们将这些沿着深度方向排列、接受区域相同的神经元集合称为深度列(depth column)。
其次,在滑动滤波器的时候,必须指定步长。当步长为1,滤波器每次移动1个像素。当步长为2,滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。
在下文可以看到,有时候将输入数据体用0在边缘处进行填充是很方便的。这个零填充(zero-padding)的尺寸是一个超参数。零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。
输出数据体在空间上的尺寸可以通过输入数据体尺寸(W),卷积层中神经元的感知域(F),步长(S)和零填充的数量(P)的函数来计算。输出数据体的空间尺寸为 (W−F+2P)/S+1 。比如输入是7×7,滤波器是3×3,步长为1,填充为0,那么就能得到一个 5×5的输出。如果步长为2,输出就是3×3。下面是例子:
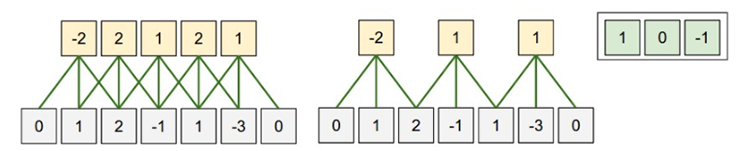
空间排列的图示在本例中只有一个空间维度(x轴),神经元的接受区域尺寸F=3,输入尺寸W=5,零填充P=1。左边:神经元使用的步长S=1,所以输出尺寸是(5-3+2)/1+1=5。
右边:神经元的步长S=2,则输出尺寸是(5-3+2)/2+1=3。注意当步长S=3时是无法使用的,因为它无法整齐地穿过数据体。从等式上来说,因为(5-3+2)=4是不能被3整除的。
本例中,神经元的权重是[1,0,-1],显示在图的右上角,偏差值为0。这些权重是被所有黄色的神经元共享的。
使用零填充:在上面左边例子中,注意输入维度是5,输出维度也是5。之所以如此,是因为接受区域是3并且使用了1的零填充。如果不使用零填充,则输出数据体的空间维度就只有3,因为这就是滤波器整齐滑过并覆盖原始数据需要的数目。一般说来,当步长S=1时,零填充的值是P=(F-1)/2,这样就能保证输入和输出数据体有相同的空间尺寸。这样做非常常见,在介绍卷积神经网络的结构的时候我们会详细讨论其原因。
步长的限制:注意这些空间排列的超参数之间是相互限制的。举例说来,当输入尺寸W=10,不使用零填充则P=0,滤波器尺寸F=3,这样步长S=2就行不通,因为 (W−F+2P)/S+1=(10−3+0)/2+1=4.5 ,结果不是整数,这就是说神经元不能整齐对称地滑过输入数据体。
案例:Krizhevsky构架赢得了2012年的ImageNet挑战,其输入图像的尺寸是 [227x227x3]。在第一个卷积层,神经元使用的接受区域尺寸F=11,步长S=4,不使用零填充P=0。因为 (227-11)/4+1=55,卷积层的深度K=96,则卷积层的输出数据体尺寸为[55x55x96]。55x55x96个神经元中,每个都和输入数据体中一个尺寸为[11x11x3]的区域全连接。在深度列上的96个神经元都是与输入数据体中同一个[11x11x3]区域连接,但是权重不同。有一个有趣的细节,在原论文中,说的输入图像尺寸是224×224,这是肯定错误的,因为(224-11)/4+1的结果不是整数。这件事在卷积神经网络的历史上让很多人迷惑,而这个错误到底是怎么发生的没人知道。我的猜测是Alex忘记在论文中指出自己使用了尺寸为3的额外的零填充。
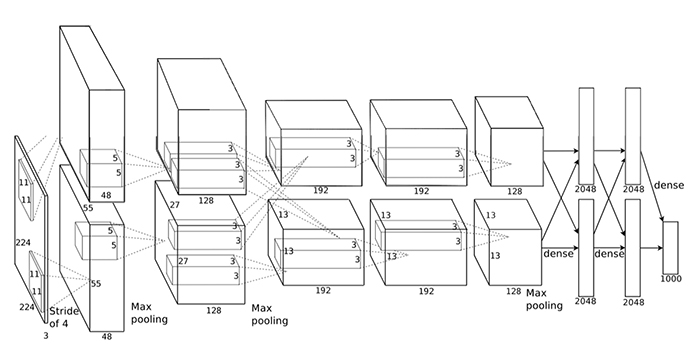
Krizhevsky ImageNet架构,同时被广称为AlexNet,caffeNet就是AlexNet的改版。
参数共享
在卷积层中使用参数共享是用来控制参数的数量。就用上面的例子,在第一个卷积层就有55x55x96=290,400个神经元,每个有11x11x3=364个参数和1个偏差。将这些合起来就是290400×364=105,705,600 个参数。单单第一层就有这么多参数,显然这个数目是非常大的。
作一个合理的假设:如果一个特征在计算某个空间位置(x,y)的时候有用,那么它在计算另一个不同位置(x2,y2)的时候也有用。基于这个假设,可以显著地减少参数数量。换言之,就是将深度维度上一个单独的2维切片看做深度切片(depth slice),比如一个数据体尺寸为[55x55x96]的就有96个深度切片,每个尺寸为[55×55]。在每个深度切片上的神经元都使用同样的权重和偏差。在这样的参数共享下,例子中的第一个卷积层就只有96个不同的权重集了,一个权重集对应一个深度切片,共有96x11x11x3=34,848个不同的权重,或34,944个参数(+96个偏差)。在每个深度切片中的55×55个权重使用的都是同样的参数。在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。这样,每个切片只更新一个权重集。
注意,如果在一个深度切片中的所有权重都使用同一个权重向量,那么卷积层的前向传播在每个深度切片中可以看做是在计算神经元权重和输入数据体的卷积。这也是为什么总是将这些权重集合称为滤波器(filter)(或卷积核(kernel)),因为它们和输入进行了卷积。

图:Krizhevsky等学习到的滤波器例子。这96个滤波器的尺寸都是[11x11x3],在一个深度切片中,每个滤波器都被55×55个神经元共享。注意参数共享的假设是有道理的:如果在图像某些地方探测到一个水平的边界是很重要的,那么在其他一些地方也会同样是有用的,这是因为图像结构具有平移不变性。所以在卷积层的输出数据体的55×55个不同位置中,就没有必要重新学习去探测一个水平边界了。
注意 有时候参数共享假设可能没有意义,特别是当卷积神经网络的输入图像是一些明确的中心结构时候。这时候我们就应该期望在图片的不同位置学习到完全不同的特征。一个具体的例子就是输入图像是人脸,人脸一般都处于图片中心。你可能期望不同的特征,比如眼睛特征或者头发特征可能(也应该)会在图片的不同位置被学习。在这个例子中,通常就放松参数共享的限制,将层称为局部连接层(Locally-Connected Layer)。
Numpy例子:为了让讨论更加的具体,我们用代码来展示上述思路。假设输入数据体是numpy数组X。那么:
- 一个位于(x,y)的深度列将会是X[x,y,:]。
- 在深度为d处的深度切片,或激活图应该是X[:,:,d]。
卷积层例子:假设输入数据体X的尺寸X.shape:(11,11,4),不使用零填充(P=0),滤波器的尺寸是F=5,步长S=2。那么输出数据体的空间尺寸就是(11-5)/2+1=4,即输出数据体的宽度和高度都是4。那么在输出数据体中的激活映射(称其为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









