







 本文详细介绍了数据预处理的三种方法:去均值、归一化和PCA白化,强调了预处理在训练中的重要性。此外,讲解了权重初始化的策略,包括全零初始化的错误、小随机数初始化的适用性,以及Xavier和He初始化方法。最后,讨论了正则化技术,如L2正则化、L1正则化、最大范式约束和随机失活,以及在损失函数中的应用。
本文详细介绍了数据预处理的三种方法:去均值、归一化和PCA白化,强调了预处理在训练中的重要性。此外,讲解了权重初始化的策略,包括全零初始化的错误、小随机数初始化的适用性,以及Xavier和He初始化方法。最后,讨论了正则化技术,如L2正则化、L1正则化、最大范式约束和随机失活,以及在损失函数中的应用。
本节主要讲了数据预处理、正则化以及损失函数
数据预处理
关于数据预处理我们有3种常用的方式,假设数据矩阵 X ,假设其尺寸是
去均值
去均值是预处理最常见的。对待训练的每一张图片的特征,都减去全部训练集图片的特征均值。它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。在numpy中,该操作可以通过代码X -= np.mean(X, axis=0)实现。而对于图像,更常用的是对所有像素都减去一个值,可以用X -= np.mean(X)实现,也可以在3个颜色通道上分别操作。
归一化
归一化是将数据的所有维度都归一化,使其数值范围都近似相等。实现归一化有两种方式。第一种是先对数据做零中心化(zero-centered),也就是去均值处理,然后每个维度都除以其标准差,实现代码为X /= np.std(X, axis=0)。第二种是对每个维度都做归一化,使得每个维度的最大和最小值是1和-1。这个预处理操作只有在确信不同的输入特征有不同的数值范围(或计量单位)时才有意义,但要注意预处理操作的重要性几乎等同于学习算法本身。在图像处理中,由于像素的数值范围几乎是一致的(0-255),所以进行此预处理不是必要的。

PCA和白化
PCA和白化是另外一种数据预处理方式。在经过去均值操作之后,我们可以计算数据的协方差矩阵,从而可以知道数据各个维度之间的相关性。
# 假设输入数据矩阵X的尺寸为[N x D]
X -= np.mean(X, axis = 0) # 对数据进行零中心化(重要)
cov = np.dot(X.T, X) / X.shape[0] # 得到数据的协方差矩阵 数据协方差矩阵的第 i,j 个元素是数据第 i 个和第
U,S,V = np.linalg.svd(cov)U的列是特征向量,S是装有奇异值的1维数组(因为cov是对称且半正定的,所以S中元素是特征值的平方)。为了去除数据相关性,将已经零中心化处理过的原始数据投影到特征基准上:
Xrot = np.dot(X,U) # 对数据去相关性 U是一组正交基向量。我们可以看做把原始数据 X 投射到这组维度保持不变的正交基底上,从而也就完成了对原始数据的去相关。如果去相关之后你再求一下Xrot的协方差矩阵,你会发现这时候的协方差矩阵是一个对角矩阵了。而numpy中的np.linalg.svd更好的一个特性是,它返回的U是对特征值排序过的,这也就意味着,我们可以用它进行降维操作。我们可以只取top的一些特征向量,然后做和原始数据做矩阵乘法,这个时候既降维减少了计算量,同时又保存下了绝大多数的原始数据信息,这就是主成分分析/PCA:
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced 变成 [N x 100] 上面的代码,将原始的数据集由
白化(whitening)。白化操作的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。该变换的几何解释是:如果数据服从多变量的高斯分布,那么经过白化后,数据的分布将会是一个均值为零,且协方差相等的矩阵。该操作的代码如下:
# 对数据进行白化操作:
# 除以特征值
Xwhite = Xrot / np.sqrt(S + 1e-5) 注意:增加噪声。分母中添加了1e-5(或一个更小的常量)来防止分母为0。该变换的一个缺陷是在变换的过程中可能会增加数据中的噪声,因为它将所有维度都拉伸到相同的数值范围,这些维度中也包含了那些只有极少差异性(方差小)而大多是噪声的维度。在实际操作中,这个问题可以用更强的平滑来解决(用比1e-5更大的值)。
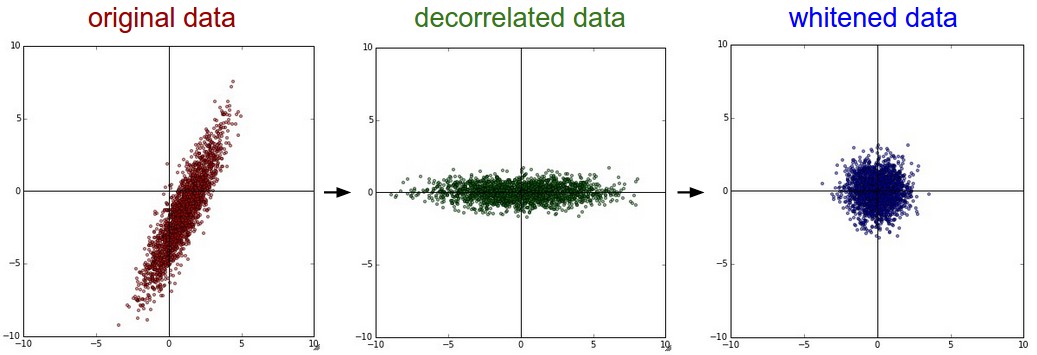
上图左边是二维的原始数据。中间是经过PCA操作的数据。可以看出数据首先是零中心的,然后变换到了数据协方差矩阵的基准轴上。这样就对数据进行去相关(协方差矩阵变成对角阵)。右边:每个维度都被特征值调整数值范围,将数据协方差矩阵变为单位矩阵。从几何上看,就是对数据在各个方向上拉伸压缩,使之变成服从高斯分布的一个数据点分布。
下面我们以CIFAR-10数据集(50000*3072)为例,看看预处理的效果。

图片最左边是原始的图像(49张)。
左二是一张图3072个特征值向量中的前144个。靠前面的特征向量解释了数据中大部分的方差,可见它们与图像中较低的频率相关。
左三是49张经过了PCA降维处理的图片,展示了前144个特征向量。每个原始图像为3072维的向量,向量中的元素是图片上某个位置的像素在某个颜色通道中的亮度值。而现在仅使用了前144维的向量,每个元素表示了特征向量对于组成这张图片的贡献度。为了让图片正常显示,需要将144维度重新变成基于像素基准的3072个数值进行可视化。因为U是一个旋转,可以通过乘以U.transpose()[:144,:]来实现。可以看见图像变得有点模糊了,这正好说明前面的特征向量获取了较低的频率。可以看出,大多数信息还是保留了下来。
最右边图像是将“白化”后的数据进行显示。其中144个维度中的方差都被压缩到了相同的数值范围。然后144个白化后的数值通过乘以U.transpose()[:144,:]转换到图像像素基准上。现在较低的频率被隐去,突出了较高的频率。
实际上在卷积神经网络中并不会采用PCA和白化这些变换。然而对数据进行零中心化操作还是非常重要的,对每个像素进行归一化也很常见。
任何预处理策略(比如数据去均值)都只能在训练集数据上进行计算,算法训练完毕后再应用到验证集或者测试集上。例如,如果先计算整个数据集图像的平均值然后每张图片都减去平均值,最后将整个数据集分成训练/验证/测试集,这个做法是错误的。应该先分成训练/验证/测试集,只是从训练集中求图片平均值,然后各个集(训练/验证/测试集)中的图像再减去这个平均值。
权重初始化
在开始训练网络之前,还需要初始化网络的参数。
错误:全零初始化。在训练完毕后,虽然不知道网络中每个权重的最终值,但如果数据经过恰当的归一化,就可以假设所有权重数值中大约一半为正数,一半为负数。这样,有人会想把权重的初始值设为0,因为在期望上来说0是最合理的猜测。这个做法错误的!因为如果网络中的每个神经元都计算出同样的输出,然后它们就会在反向传播中计算出同样的梯度,从而进行同样的参数更新。换句话说,如果权重被初始化为同样的值,神经元之间就失去了不对称性的源头。
不太好:小随机数初始化。权重初始值最好非常接近0又不能等于0。解决方法就是将权重初始化为很小的数值,以此来打破对称性。其思路是:如果神经元刚开始的时候是随机且不相等的,那么它们将计算出不同的更新,并将自身变成整个网络的不同部分。
小随机数权重初始化的实现方法是:W = 0.01 * np.random.randn(fan_in,fan_out)。其中randn函数是基于零均值和标准差的一个高斯分布来生成随机数的。根据这个式子,每个神经元的权重向量都被初始化为一个随机向量,而这些随机向量又服从一个多变量高斯分布,这样在输入空间中,所有的神经元的指向是随机的。也可以使用均匀分布生成的随机数,但是从实践结果来看,对于算法的结果影响极小。
注意。并不是小数值一定会得到好的结果,可能会导致梯度饱和。例如,一个神经网络的层中的权重值很小,那么在反向传播的时候就会计算出非常小的梯度(因为梯度与权重值是成比例的)。这就会很大程度上减小反向传播中的“梯度信号”,在深度网络中,就会出现问题。
正确:使用1/sqrt(n)校准方差(Xavier init)。小随机数初始化存在一个问题,随着输入数据量的增长,随机初始化的神经元的输出数据的分布中的方差也在增大。我们可以除以输入数据量的平方根来调整其数值范围,这样神经元输出的方差就归一化到1了。也就是说,建议将神经元的权重向量初始化为:w = np.random.randn(fan_in,fan_out) / sqrt(fan_in)。其中fan_in是输入数据的数量。这样就保证了网络中所有神经元起始时有近似同样的输出分布。实践经验证明,这样做可以提高收敛的速度。
我们从数学的角度,简单解释一下,为什么上述操作可以归一化方差。考虑在激励函数之前的权重 w 与输入
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3057
3057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









