







 本文是斯坦福大学CNN课程的学习笔记,介绍了梯度下降法在优化损失函数中的作用。通过数值梯度和分析梯度计算梯度,并详细讲解了批量梯度下降法在大规模数据集中的应用,强调了mini-batch的重要性。
本文是斯坦福大学CNN课程的学习笔记,介绍了梯度下降法在优化损失函数中的作用。通过数值梯度和分析梯度计算梯度,并详细讲解了批量梯度下降法在大规模数据集中的应用,强调了mini-batch的重要性。
本课程笔记是基于今年斯坦福大学Feifei Li, Andrej Karpathy & Justin Johnson联合开设的Convolutional Neural Networks for Visual Recognition课程的学习笔记。目前课程还在更新中,此学习笔记也会尽量根据课程的进度来更新。
p.s: 最近由于在赶一个会议,所以这个课程笔记落下很多,我会抓紧赶上的T T。还有农历年要到啦,祝大家新年快乐!
在之前的章节中,我们已经得到了loss function,并且希望loss尽可能小,因为这说明我们分类器的预测结果和ground truth相接近。那么我们所要做的就跟下面这张图的意思差不多,我们在一座叫做loss的山谷里,为了找到谷底(loss最小),我们虽然被蒙住了眼睛,但是可以通过坡度是否下降来判断我们是不是在向谷底的方向走。也就是说,我们要利用梯度下降进行loss的优化。

1. Follow the gradient
“坡度”在一维空间中其实就是斜率(导数),其数学表达式是这样的:
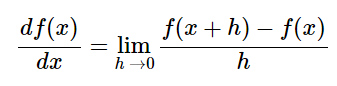
那么梯度其实就是多维空间中的斜率,是通过对每一维求偏导得到的向量。
如何计算梯度呢?有两种方法,numerical gradient和analytic gradient,我们下面逐一说明。
1.1 Numerical Gradient
第一种方法是按照定义的数学表达式从数值上去进行计算。在我们的问题中f是loss,x是权重W,按照上述公式,我们可以对每一维W增加一个h,然后看loss的变化,求得这一维上的偏导。如下图,我们对每一维W都计算gradient,最后再根据总的gradient选择这一步我们“走”的方向。这种方法是估计的,并且计算量很大,因为每一步的optimization都需要计算所有维W的偏导,导致效率很低。

1.2 Analytic Gradient
我们知道loss function本身就是W的函数,我们可以直接对公式进行求导啊
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3424
3424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









