下载网页 (重传)
重传功能:如果返回如503等错误吗,可以尝试重传,错误吗可以参考:https://tools.ietf.org/html/rfc7231
import urllib2
def download(url, num_retries=2):
print 'Downloading:',url
try:
html = urllib2.urlopen(url).read()
except urllib2.URLError as e:
print 'Download error:', e.reason
html = None
# 此部分实现当返回错误为5xx时,进行重传
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries-1)
# ——重传功能结束
return html
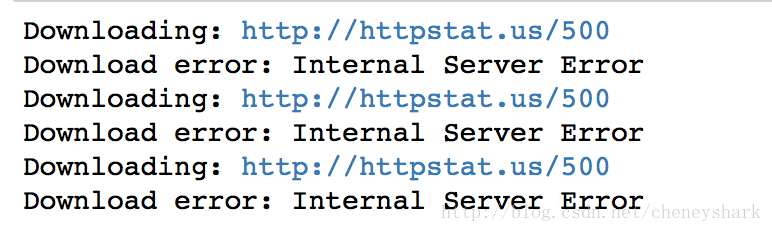
# 测试:这个网站始终会返回 500 错误吗
download('http://httpstat.us/500')
运行结果:
设置用户代理
缺省情况下,urllib2使用 Python-urllib/2.7 作为用户代理下载网页内容&#x








 本文介绍了爬虫的基本操作,包括如何下载网页,设置用户代理以避免被识别为机器人,以及如何进行ID遍历和链接爬虫。在链接爬虫部分,讲解了解析robots.txt文件的重要性以及设定爬虫的最大深度限制。
本文介绍了爬虫的基本操作,包括如何下载网页,设置用户代理以避免被识别为机器人,以及如何进行ID遍历和链接爬虫。在链接爬虫部分,讲解了解析robots.txt文件的重要性以及设定爬虫的最大深度限制。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









