






1.研究背景
近年来,随着多媒体技术的高速发展,视频数据也呈现出爆炸性的增长。基于内容的视频检索已成为当前的迫切需求。特别在电影视频领域,单纯的播放已经无法满足用户日益增长的需要。如何准确快速地按照用户的需求检索出反映观众情感变化的电影视频片段成为当前的一个研究热点。在这种环境下,电影视频景别音阶的检测便应运而生。 在系统研究了电影导演创作手法的基础上,利用不同景别镜头的组合可以影响当前观众视觉心理这个原理,设计了一种基于电影视频的景别音阶识别与检测方法。 通过对以往研究成果的分析,针对当前视频镜头景别的分类特征多是基于体育视频而对电影视频效果不佳的问题,结合电影领域知识构建了局部运动占有率、摄像机运动和镜头间相似度等新的特征,与常用的其他特征相结合,利用贝叶斯分类器将电影镜头分为远景镜头、中景镜头和近景镜头并与其它分类算法进行了比较和分析。 根据景别变化同观众情感之间的关系,设计了5种能够激发观众情感的景别音阶,在景别识别的基础上实现了对景别音阶的检测。 实验结果表明,新的特征较好地反映了不同景别的特点。与现有的其它方法相比,远景与近景的识别在准确率和查全率上均有不同程度的提高。但是由于中景镜头本身的模糊性和构建的特征不能很好地反映中景镜头的特点,导致中景的识别率并不尽如人意。景别的识别直接影响到景别音阶的检测效果,而景别识别的效果在总体上还有待改善,因此未来的研究重点在于如何提高镜头景别的识别精度
2.功能介绍

3.景别分类过程&结果演示


4.视频展示
基于OpenCV的视频人像景别分类算法(源码&教程)_哔哩哔哩_bilibili
5.电影作品的景别分类
为满足上述需求,我们研究了电影拍摄艺术和视觉心理等相关领域知识,发现电影的景别音阶能够有效地诱发观众的情感变化。所以,检测和识别视频片段中的景别音阶,就能在电影视频中寻找到观众情感变化的片段。这可应用在视频检索和视频点播等领域,也是电影摘要生成的关键技术之一,有着比较高的学术价值和广泛的应用前景,同时也具有一定的挑战性。
从摄影的角度来说,景别是指由于摄像机相对静止物体的运动或者物体本身的运动,造成画面上被摄物体形象的改变"。景别的划分没有一个严格的标准,通常被分为远景镜头(Long Shot)、中景镜头(Medium Shot)和近景镜头或者特写镜头(Close-up Shot)。在某些特定的场合可能需要更详细的划分,比如特写镜头可能再被划分为一般特写和大特写镜头。下面分别介绍三种景别的定义:
(1)远景
远景镜头是一种持续时间较长的镜头,它反映了较多的信息。远景镜头是一种长镜头,在电影视频中主要用来交代场景发生的时间、地点和背景信息,一般被作为过渡镜头出现在整个电影场景的开头或结尾。在远景镜头中,人体所占的面积较小。
(2)中景
中景镜头是电影视频中最常用到的一类镜头。它不像远景镜头注重整体忽略细节,也不像近景镜头突出细节抹杀整体,而是把整体的信息放到一个次要的位置。用中景来表现一个人物,其占有的空间比远景大,一般包括人体膝盖以上的范围。有的把拍摄到的人体的肩部以上的镜头也作为中景镜头,虽然这样的划分一定的主观性,但是中景镜头都能够比较清楚地看到人体的形态。
(3)近景
如果利用画面中的人物作为参考,特写镜头仅仅拍摄人物颈部以上部分,或者拍摄人体某个细节部分。相对于中景镜头来说,特写镜头更加体现人或物的细节部分,其作用是将这些细节部分从周遭环境中突显出来,特写镜头往往更具表现力,更能引发观众的注意。
不同的景别带给观众不同的感觉.比如远镜头往往交代时间、地点或者背景,给人以客观的感受;近镜头对细节的描述较多,往往容易吸引观众的注意。因此,由远镜头-中镜头-中镜头-近镜头这样的镜头组合序列,带给观众的情感是从客观转向专注;反之,由近镜头-中镜头-远镜头这样的镜头组合使观众逐渐从紧张的情绪中缓和下来;而近镜头-近镜头-近镜头这样多个连续近镜头的场景,可能是某些观众喜爱的打斗场景。一些特定景别的镜头组合,常常能够引起观众的情感共鸣。由不同景别构成,能够引起人们情感变化的镜头组合,我们就称之为景别音阶。这些表现出不同景别的镜头犹如高低音色不同的琴键,在电影这部优雅的现代钢琴上,弹奏出行云流水般的音符。

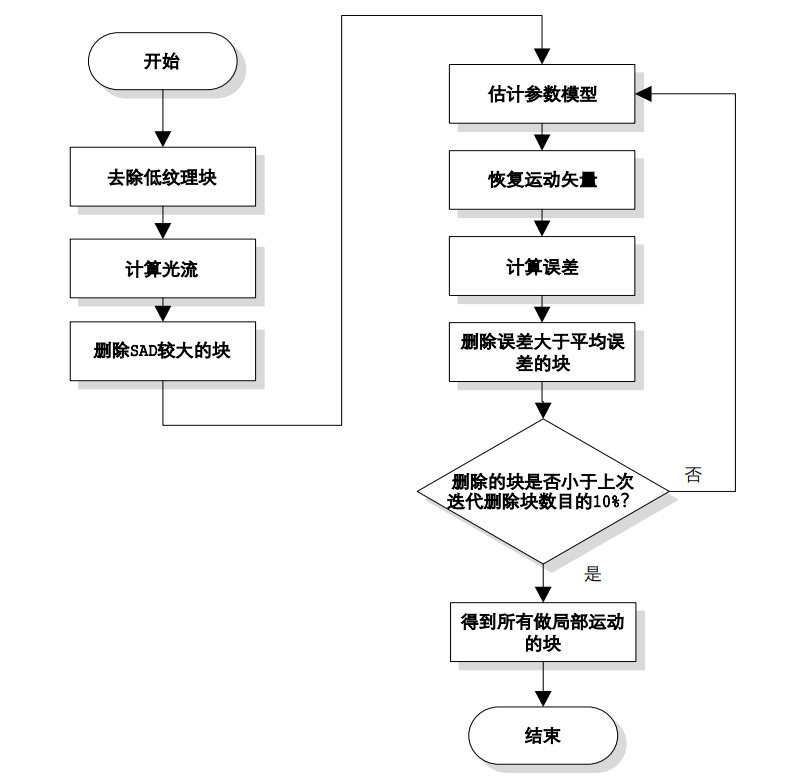
6.算法流程图
7.人脸特征
作为对象检测的一个重要组成部分,人脸检测技术长期以来受到极大的关注。在电影视频中,人是电影场景中出现最多的元素,认为电影是表现人类行为的一种艺术丝毫不为过。所以,如果能够确定电影中人脸甚至人体的位置和大小,那么判断电影视频镜头的景别也就变得相对容易。人脸的检测表示检测出视频帧画面中是否存在人脸,而人脸的定位则是在人脸存在的前提下从画面中寻找人脸对象确切位置的过程。因此,人脸的定位建立在人脸检测的基础之上。本文所关心的是人脸在画面中是否出现、大小以及位置,这就要求在具体的实现中使用人脸检测和人脸定位相结合的算法。在具体的实现中采用了adaboost 算法,采用该算法的原因是该算法的准确率高,速度较快。
人是在电影视频中出现最多的元素,人脸是人类最显著的特征。大多数情况下,画面中并不一定呈现整个人的躯体,出现的往往是包括人脸的上半身,且人脸一般出现在画面中的显著位置。通常在近景的对话镜头中,人脸所占的比例较大,且一般是正面,较容易被检测到。而对中景镜头来说,通常在一个画面中出现多个人脸,人脸占有的比例较小,而且位置也不一定在画面的中心部分。远景镜头一般并不表现人脸,多是表现一些时空间的过渡信息,即使在远景镜头中出现一些人脸,通常也难以被检测出来。
综上所述,为了识别出镜头的景别,需要在一个视频帧的画面中得到一些人脸的信息,具体有人脸出现的位置、人脸的大小以及人脸的个数。下图给出了一些人脸检测的例子。

8.代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_classification
from mpl_toolkits.mplot3d import Axes3D
def LDA(X, y):
X1 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
X2 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
len1 = len(X1)
len2 = len(X2)
mju1 = np.mean(X1, axis=0)#求中心点
mju2 = np.mean(X2, axis=0)
cov1 = np.dot((X1 - mju1).T, (X1 - mju1))
cov2 = np.dot((X2 - mju2).T, (X2 - mju2))
Sw = cov1 + cov2
w = np.dot(np.mat(Sw).I, (mju1 - mju2).reshape((len(mju1), 1))) # 计算w
X1_new = func(X1, w)
X2_new = func(X2, w)
y1_new = [1 for i in range(len1)]
y2_new = [2 for i in range(len2)]
return X1_new, X2_new, y1_new, y2_new
def func(x, w):
return np.dot((x), w)
if '__main__' == __name__:
X, y = make_classification(n_samples=500, n_features=2, n_redundant=0, n_classes=2,
n_informative=1, n_clusters_per_class=1, class_sep=0.5, random_state=10)
X1_new, X2_new, y1_new, y2_new = LDA(X, y)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
plt.plot(X1_new, y1_new, 'b*')
plt.plot(X2_new, y2_new, 'ro')
plt.show()
9.系统整合
下图源码&环境部署视频教程&自定义UI界面
参考博客《基于OpenCV的电影视频人像景别分类算法(源码&教程)》



















 3311
3311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











