输入:样本集D={x1,x2,...,xm}
邻域参数(ε,MinPts).
过程:
初始化核心对象集合:Ω = Ø
for j=1,2,...,m do
确定样本xj的ε-邻域N(xj);
if |N(xj)|>=MinPts then
将样本xj加入核心对象集合Ω
end if
end for
初始化聚类簇数:k=0
初始化未访问样本集合:Γ =D
while Ω != Ø do
记录当前未访问样本集合:Γold = Γ;
随机选取一个核心对象 o ∈ Ω,初始化队列Q=<o>
Γ = Γ\{o};
while Q != Ø do
取出队列Q中首个样本q;
if |N(q)|<=MinPts then
令Δ = N(q)∩Γ;
将Δ中的样本加入队列Q;
Γ = Γ\Δ;
end if
end while
k = k+1,生成聚类簇Ck = Γold\Γ;
Ω = Ω\Ck
end while
输出:
簇划分C = {C1,C2,...,Ck}
算法实现
#计算两个向量之间的欧式距离defcalDist(X1 , X2 ):
sum = 0for x1 , x2 in zip(X1 , X2):
sum += (x1 - x2) ** 2return sum ** 0.5#获取一个点的ε-邻域(记录的是索引)defgetNeibor(data , dataSet , e):
res = []
for i in range(shape(dataSet)[0]):
if calDist(data , dataSet[i])<e:
res.append(i)
return res
#密度聚类算法defDBSCAN(dataSet , e , minPts):
coreObjs = {}#初始化核心对象集合
C = {}
n = shape(dataSet)[0]
#找出所有核心对象,key是核心对象的index,value是ε-邻域中对象的indexfor i in range(n):
neibor = getNeibor(dataSet[i] , dataSet , e)
if len(neibor)>=minPts:
coreObjs[i] = neibor
oldCoreObjs = coreObjs.copy()
k = 0#初始化聚类簇数
notAccess = range(n)#初始化未访问样本集合(索引)while len(coreObjs)>0:
OldNotAccess = []
OldNotAccess.extend(notAccess)
cores = coreObjs.keys()
#随机选取一个核心对象
randNum = random.randint(0,len(cores))
core = cores[randNum]
queue = []
queue.append(core)
notAccess.remove(core)
while len(queue)>0:
q = queue[0]
del queue[0]
if q in oldCoreObjs.keys() :
delte = [val for val in oldCoreObjs[q] if val in notAccess]#Δ = N(q)∩Γ
queue.extend(delte)#将Δ中的样本加入队列Q
notAccess = [val for val in notAccess if val notin delte]#Γ = Γ\Δ
k += 1
C[k] = [val for val in OldNotAccess if val notin notAccess]
for x in C[k]:
if x in coreObjs.keys():
del coreObjs[x]
return C
defloadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split(' ')
fltLine = map(float,curLine)
dataMat.append(fltLine)
return dataMat
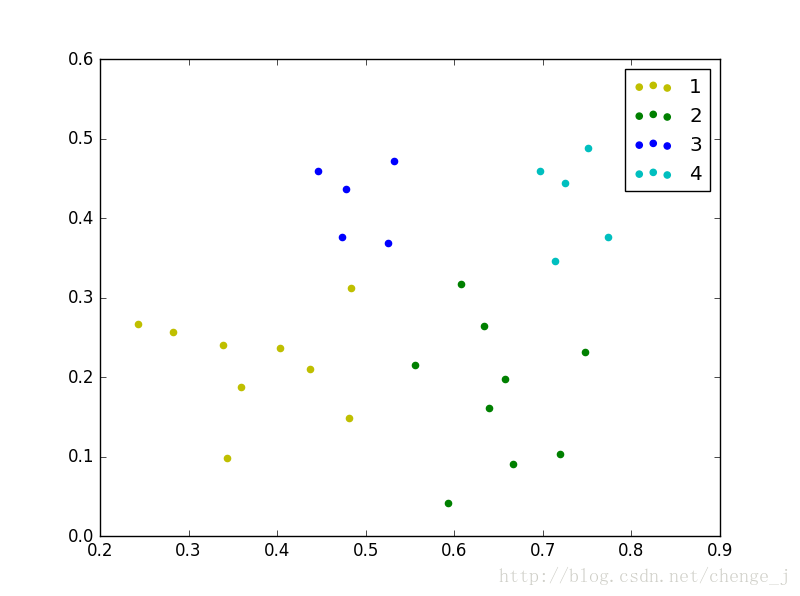
画图方法
defdraw(C , dataSet):
color = ['r', 'y', 'g', 'b', 'c', 'k', 'm']
for i in C.keys():
X = []
Y = []
datas = C[i]
for j in range(len(datas)):
X.append(dataSet[datas[j]][0])
Y.append(dataSet[datas[j]][1])
plt.scatter(X, Y, marker='o', color=color[i % len(color)], label=i)
plt.legend(loc='upper right')
plt.show()























 2925
2925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









