






简介
MFCC是一种语音特征提取技术,它产生与20世纪80年代。MFCC为了从人发出的音频中去除噪音和情感的影响,提取特征值便于我们进行进一步的分析。
人的发声由很多部位共同影响的结果,如嘴形、牙齿等因素,这种形状可以决定声音的输出。如果我们可以精确的确定形状,那么我们就可以对发出的因素进行科学的表示。这篇文章将带你走进MFCC技术,解释它为什么能够很好的用于语音识别领域以及如何实现它。
首先我们来确定一下如何进行MFCC的步骤:
-----1.将音频分解为帧;
-----2.对于每一帧,计算周期功率谱;
-----3.将mel滤波器应用到功率谱中,计算每个滤波器的能量和;
-----4.计算能量的对数值;
-----5.对每个对数能量进行离散余弦变换(DCT);
-----6.保留DCT的2-13个系数,其余系数舍去;
现在我们来探讨一下每一步的细节以及为什么要这么做。
一个音频信号通常是不断变化的,为了简化,我们通常假设一个较短时间内音频信号不会有较大的变化(我们指统计上),所以我们把每一帧划分成20-40ms为宜,若该时间太短,则没有足够的信号来进行功率估计;方之,若太长,则每一帧信号变化太多。
下一步是计算每一帧的周期功率谱,这个源自人的耳锅,它随声音的大小而发生不同频率的振动。通过耳锅的不同位置上的振动,不同的神经元将会通知大脑现在听到的音频频率。我们的周期图同样为我们做出这种工作,确定帧中存在哪些频率。
周期图同样存在一些ASR(Automatic Speech Recognition)不需要的信息。实际上耳锅无法辨别两个空间上相近的频率。当频率变大时,这种影响更明显。因此,我们采取周期图块,并且将它们进行累加来得知在不同频率区域的能量是多少。这个是有我们的mel滤波器完成的,第一个滤波器非常狭窄,可以告诉我们频率为0Hz附近的能量是多少,当频率渐渐变高时,我们的滤波器也会越来越宽,我们只关心每一个点能量是多少。mel级别告诉我们如何去划分滤波器以及滤波器的宽度如何选择。
一旦我们有了滤波器的能量,我们对它取对数,这也是受人类听力启发的;通常我们无法听出线性级别的音量,通常若声音扩大两倍,我们需要放入8倍的能量进去。这就意味着能量上有较大的变化并不代表声音大小变化很大,为什么这里我们使用对数而不是取平方根,那是因为我们可以使用cepstral mean subtraction,它是一个频道归一化的技巧。
最后一步是计算对数能量的DCT,关于这个有两点原因:因为我们的滤波器通常都有交叠,因此滤波器能量彼此相关;DCT对能量进行去相关,意味着协方差的对角矩阵可以用来对HMM分类器进行建模。但是注意,DCT中26个系数只有12个被保留下来,这是因为DCT的高阶系数代表滤波器能量的快速变化,事实证明这些快速变化影响ASR的表现,所以我们去除高阶系数。
什么是mel scale(梅尔规模)?
mel scale将感知频率与音频的实际频率相联系起来,人们更容易区分低频中的微小频率变化,而对高频中的微小频率变化则难以区分。使用mel scale可以帮助更加模拟人的听觉。
从频率到mel scale的计算公式为

反过来,从mel scale回到频率的公式为

实现步骤:
我们从一段语音信号开始,假设该信号的采样频率为16KHz。
1.将信号以20-40ms为一帧进行划分,25ms较为标准。这意味着对于一个16KHz的信号,共有0.025*16000=400个样本。帧的间隔通常为10ms,即160个样本,即第一帧400个样本从样本0开始,第二帧400个样本从样本160开始,帧之间具有交叠部分,直到达到语音文件结尾为止。如果语音文件不能划分成偶数个帧,用0填满它。
下一步是进行对每个单一帧进行提取12个MFCC系数,我们约定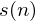 为我们的时域信号,
为我们的时域信号, 为第i帧的时域型号,n的取值为1-400,但我们计算复数离散傅立叶变换,我们得到
为第i帧的时域型号,n的取值为1-400,但我们计算复数离散傅立叶变换,我们得到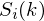 ,i表示第i帧,
,i表示第i帧, 是第i帧的功率谱。
是第i帧的功率谱。
2.为了计算每一帧的DFT,执行下面的运算:

其中,h(n)为样本分析的汉明窗,K是DFT的长度。接下来每一帧的功率谱估计即

这就是功率谱的周期图估计,我们将会进行512个点的FFT,只保留开始的257个系数。
3.计算梅尔间距滤波器。这里一般有20-40(26最好)个三角形滤波器,应用到第2步的功率谱上面,我们的滤波器有26个向量组成,每个向量元素个数为257,每个向量大部分为0,但是有一部分频率的值非零。为了计算滤波器的能量,我们把每一个滤波器与功率谱进行相乘,然后系数相加,最后这就给了我们26个数值,它们代表每一个滤波器上面的能量。下图说明了这些细节:

4.分别计算第3步中26个能量的对数值。
5.对26个对数能量进行DCT,得到26个系数,我们只取前12个。
这样,我们对于每一帧得到的12个数称为Mel Frequency Cepstral Coefficients,即梅尔频率倒谱系数。
关于计算梅尔间距滤波器的细节部分:
这一部分为了方便讲解我们使用10个滤波器,实际中应该使用26-40个滤波器。我们首先要选择频率上下限,一般取300Hz为最小频率,8000Hz为最大频率。当然如果语音的采样频率为8000Hz,那么我们的最大频率修改为4000Hz。然后进行如下步骤:
1.使用方程1,将频率转化为梅尔频率,即300Hz变为401.25Mels,8000Hz变为2834.99Mels。
2.对于这个例子,我们需要10个滤波器,因此需要找到12个点。意味着我们要在梅尔最大最小频率之间再插10个等间隔频率,即
m(i) = 401.25, 622.50, 843.75, 1065.00, 1286.25, 1507.50, 1728.74,1949.99, 2171.24, 2392.49, 2613.74, 2834.99
h(i) = 300, 517.33, 781.90, 1103.97, 1496.04, 1973.32, 2554.33, 3261.62, 4122.63, 5170.76, 6446.70, 8000
f(i) = floor((nfft+1)*h(i)/samplerate)
f(i) = 9, 16, 25, 35, 47, 63, 81, 104, 132, 165, 206, 256
5.现在我们可以来建立滤波器了,第一个滤波器应该从第一个点开始,在第二个点处到达峰值,在第三个点处为0......同理可得其他,公式如下所示:

最后,10个滤波器的图像如下所示:

(工作时,频率从300Hz开始)
最后一点:Deltas and Delta-Deltas
又名差和加速系数,MFCC特征系数仅仅概括单一帧的功率谱,但是语音信号似乎是动态的,例如MFCC特征系数随时间变化的轨迹如何,实践表明,计算MFCC后,再加上一些原始的特征向量能够提高ASR的表现。(如果我们有12个MFCC,又有12个delta系数,这样一共得到24个系数)
计算delta系数的公式如下:

其中 是一个delta系数,由
是一个delta系数,由 和
和 计算而来,N的典型值一般取2,差和加速系数计算方法类似,不过它们的是对delta来求的,而不是c。
计算而来,N的典型值一般取2,差和加速系数计算方法类似,不过它们的是对delta来求的,而不是c。















 8631
8631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









