







GEDI 科学数据产品包括描述地球 3D 特征的足迹和网格数据集。这些数据产品被分配了不同的级别,这表明了数据在收集后所经历的处理量。所有产品都是公开可用的,其中较低级别的产品(L1 和 L2)来自 NASA 的土地过程分布式主动档案中心 ( LPDAC),较高级别的产品 (L3 和 L4) 来自 ORNL DAAC。 数据最初传输到戈达德太空飞行中心的GEDI任务运营中心 (MOC) ,该中心每周部署采购计划,然后通过科学运营中心 (SOC) 进行处理,将科学数据产品分发给上述 DAAC。
用于创建这些数据产品的物理理论、数学程序和模型假设在算法理论基础文档 (ATBD) 中进行了描述。这些可以在这里找到。
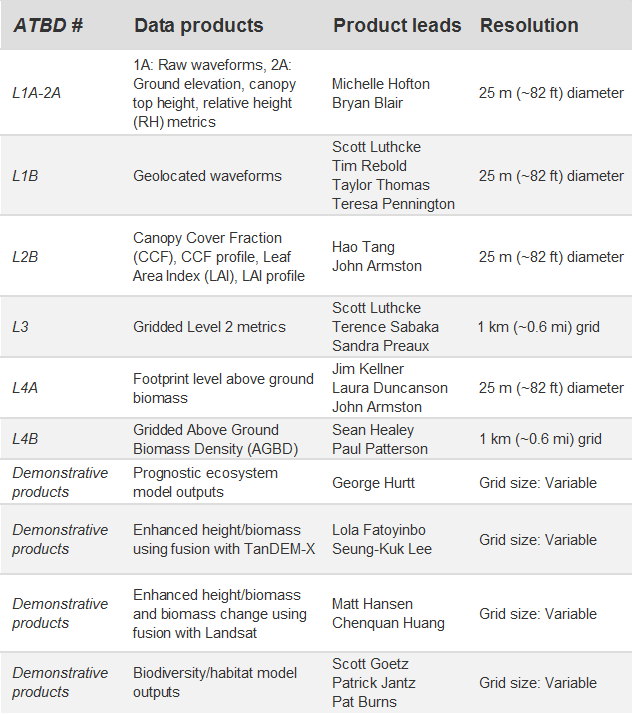
级别 1 - 地理定位波形
GEDI 系统收集的原始 GEDI 波形由我们的科学团队进行地理定位。
级别 2 - 足迹级别的树冠高度和轮廓指标
处理波形以提供冠层高度和剖面指标。这些是直接根据每个足迹的波形返回计算的值,例如地形高程、冠层高度、RH 指标和叶面积指数 (LAI)。这些指标提供了易于使用和解释的关于顶篷材料垂直分布的信息。
级别 3 - 网格树冠高度指标和可变性
3 级产品通过对冠层覆盖、冠层高度、LAI、垂直树叶剖面及其不确定性的 2 级足迹估计进行空间内插来网格化。
4A 和 4B 级 - 足迹和网格地上碳估计
4 级产品是 GEDI 产品的最高级别,代表模型的输出。来自 L2 数据产品的足迹指标使用校准方程转换为地上生物量密度的足迹估计。随后,这些足迹用于使用统计理论在 1 公里的单元格中产生平均生物量及其不确定性。
示范产品
这些科学产品展示了使用 GEDI 数据实现的一系列输出。与其他数据产品不同,这些输出仅针对有限的域创建。
预测生态系统模型输出
生态系统人口学模型 (ED) 以高分辨率提供大面积碳储量和通量的估计值。因为是高度结构模型,所以可以用激光雷达导出的植被结构信息来初始化ED。当使用来自 GEDI 的植被结构信息进行初始化时,ED 会在多个政府间气候变化专门委员会 (IPCC) 气候和土地利用变化情景下对热带和温带森林的碳固存潜力进行高空间分辨率估计。这些模拟通过政策对土地利用和发展的影响以及对大气二氧化碳浓度的影响,提供了对政策作用的现实评估。

使用与 TANDEM-X 融合提高高度/生物量
TanDEM-X 是一种干涉合成孔径雷达任务 (InSAR),由两个航天器组成,可同时对地球上的一个位置进行成像。高分辨率森林高度图可以从 TanDEM-X 采集生成,并使用 GEDI 观测进行改进。反过来,这些高度图可用于升级 GEDI 激光雷达生物量估计。正在开发的高级算法将 TanDEM-X 的墙到墙映射能力与 GEDI 激光雷达的空间采样相结合,以比单独使用任一任务所能达到的分辨率和精度更高的分辨率和精度提供改进的高度和生物量估计。这项工作是 GEDI 与德国航天局 (DLR) 正式合作的一部分。

通过融合 GEDI 和 25 M TANDEM-X (TDX) 数据创建的美国新罕布什尔州哈伯德布鲁克实验森林的生物量估计值。
使用与 LANDSAT 融合提高高度/生物量
GEDI 的足迹大小和准确的地理定位允许与植被变化的 Landsat 地图融合,以提供高空间分辨率的植被高度估计和每年到 5 年时间尺度的地上碳储量变化。当与 GEDI 的森林结构观测相结合时,Landsat 的森林面积和森林干扰估计值提供了迄今为止最准确的森林砍伐碳排放估计值。
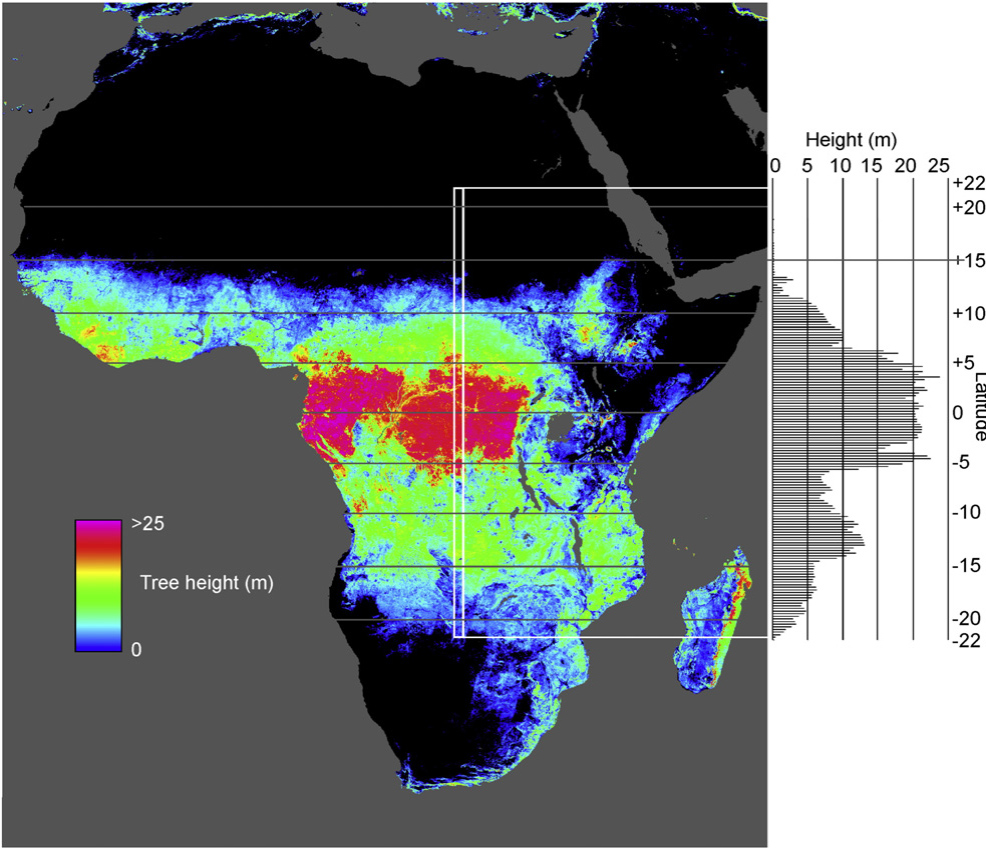
生物多样性和栖息地模型
栖息地异质性指数是使用来自 GEDI 波形的植被高度分布的垂直和水平信息作为栖息地质量以及多尺度植物和动物多样性的指标来制定的。预测模型是针对特定区域开发的,这取决于用于模型校准和验证的原位生物多样性数据的可用性。然后使用源自 Landsat 的植被损失和干扰图来估计土地利用对栖息地质量和生物多样性的潜在影响。
引用:

















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









