







通过这几天的试用,Llama3确实相当优秀,这里推荐给大家Llama3的私有部署,然后使用LobeChat搭建自己的知识库问答系统。大家可能以为部署Llama3需要什么样的硬件,先介绍硬件的配置,我使用Llama3 70b的硬件列表:
1、CPU E5-2696v3
2、内存64GB
3、Nvidia Tesla P40 24G 两片,运行70b强列建议使用两片P40。如果使用Llama3 8b的,可以使用一片P40。
4、硬盘:2TB NVME SSD,普通硬盘也用过,就是加载慢,一旦加载好,也很快,这里推荐使用使用SSD硬盘。因为可能会下载其他的大模型,这里我还使用了qwen 32b和qwen 72b,所以容量大点。
5、操作系统:选用ubuntu 22.04服务器版,当然debian也可以,设置本机IP:192.168.29.87。
一:使用Ollama部署Llama3
Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。支持多种大模型的本地化部署,在管理模型的同时,它还基于 Go 语言中的 Web 框架 gin (opens new window)提供了一些 Api 接口,让你能够像跟 OpenAI 提供的接口那样进行交互。这里就相当友好了,对那种不想花钱翻墙的小伙伴,可以使用他替代OpenAI 提供接口。
1、安装ollama
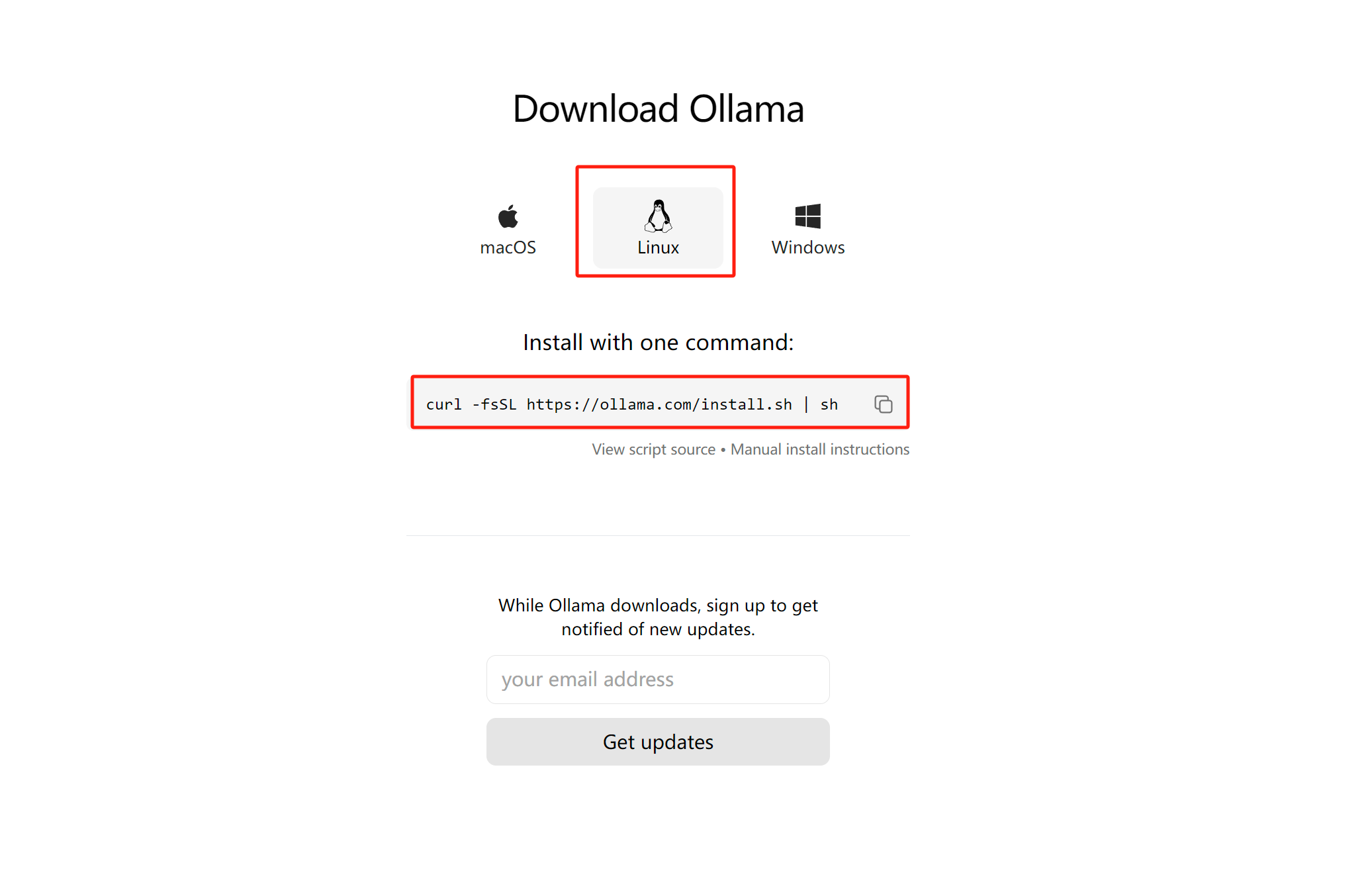
安装ollama:
curl -fsSL https://ollama.com/install.sh | sh注:这里默认你已经安装好了Nvidia驱动,Cuda、Cudnn等。
直接执行上面的指令安装ollama。
2、安装Llama3

在ollama界面,点击models,找到Llama3。在下拉菜单选择你要下载的模型。
然后在你的服务器执行:
#安装70b
ollama run llama3:70b
#安装8b
ollama run llama3:8b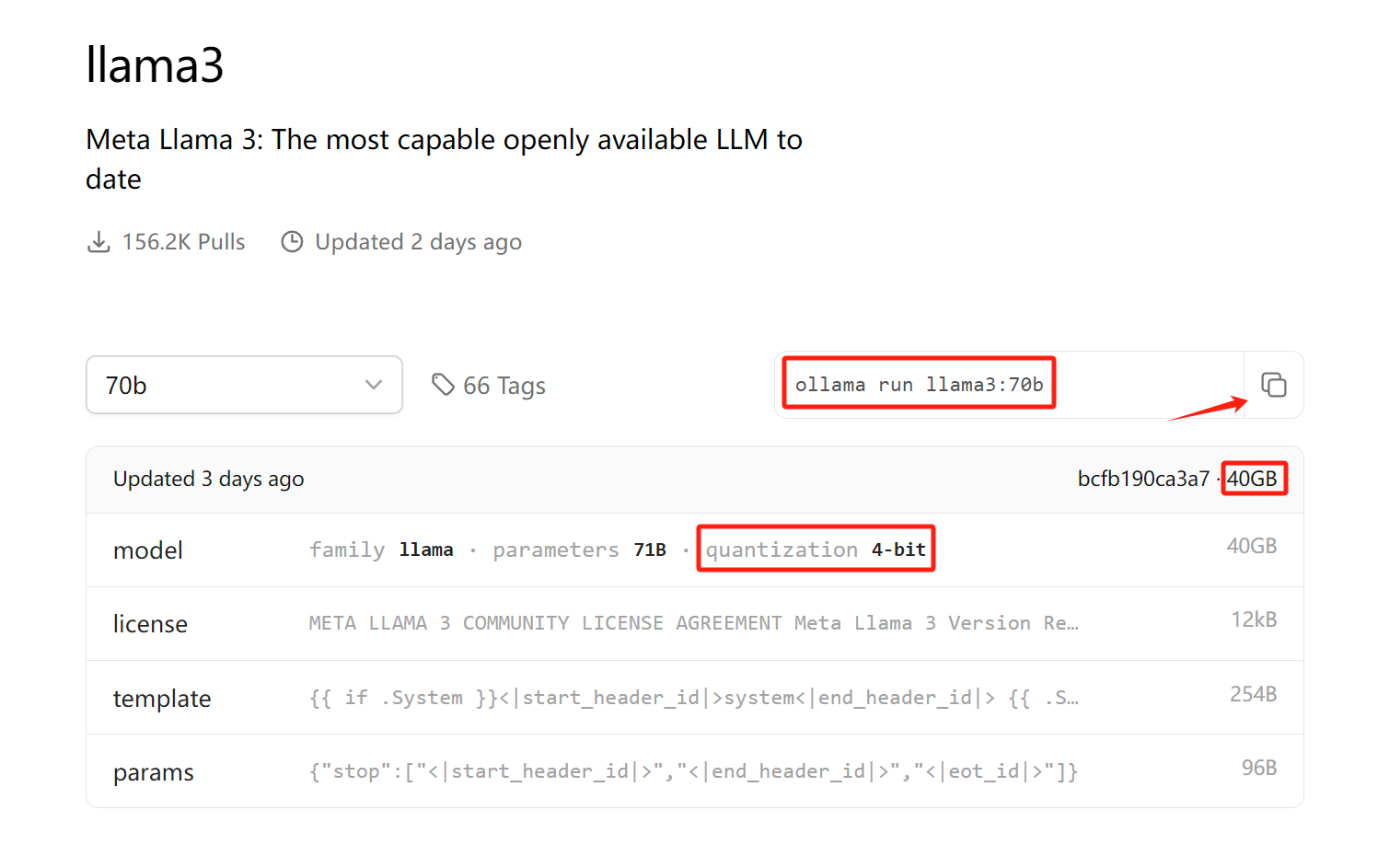
注:这个是4位量化版,当然如果你有更好的显卡,你可以下载16fp下面也有。
3、运行Llama3:
ollama run llama3:70b当然你也可以下载qwen32b和qwen72b进行对比测试。
#安装qwen 72b
ollama run qwen:72b
#安装qwen 32b
ollama run qwen:32b4、相关指令操作
ollama list :显示模型列表。
ollama show :显示模型的信息
ollama pull :拉取模型
ollama push :推送模型
ollama cp :拷贝一个模型
ollama rm :删除一个模型
ollama run :运行一个模型5、Ollama跨域访问及验证IP访问
默认情况下,你可以通过127.0.0.1端口11434访问Ollama API。当然如果你需要从外部访问ollama则需要修改ollama.service文件。
vim /etc/systemd/system/ollama.service修改如下内容:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.targetEnvironment="OLLAMA_HOST=192.168.29.87:11434"
Environment="OLLAMA_ORIGINS=*"
增加以上两句,IP地址为你自己的本机IP。
验证ollama API方法:
curl http://192.168.29.87:11434
二:部署LobeChat
请参考:在本地部署LobeChat_lobechat本地部署-CSDN博客
这里注意:部署所使用的lobechat版本:0.147.21,因为lobechat版本更新太快,新版本已经可以支持ollama了,但仍有问题,等新版本稳定了,再使用,所以这里仍旧使用:0.147.21。
1、lobechat下载地址
https://github.com/lobehub/lobe-chat/releases

2、设置LLM

Ollama的API遵从OpenAI的API接口,所以可以直接在OpenAI的API里直接使用。
(1)将OpenAI开关打开
(2)OpenAI API Key:可以随便写。
(3)接口地址:http://192.168.29.87:11434/v1
(4)模型列表:填写你下载的的几个模型
3、修改【默认助手】

在这里选定你要使用哪个模型,如上图。
三:为什么使用LobeChat进行测试
因为LobeChat有丰富的插件:

如何下载这些插件:

几百种应用,可以尽情的选吧。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











