









背景介绍
Ollama 是目前最流行的大模型本地化工具之一。
Ollama 支持一系列开源大模型,包括主流的聊天模型和文本嵌入模型(Embedding Models)等。 ChatOllama 是基于 Ollama 的 Web 应用,它可以让用户直接在浏览器中使用 Ollama。ChatOllama 支持多种大模型,包括 Ollama 支持的所有大模型,以及 OpenAI,Anthropic 的大模型。
ChatOllama 的作者是 B 站的一名 up @ 五里墩茶社
他经常发布一些关于 LLM 的教程,学到很多,感谢!
本文档是结合他的视频和 GitHub 文档做的实践和翻译。版权归他,侵权就删。
本文将使用 Docker 一键运行 ChatOllama,让用户可以在本地快速部署 ChatOllama。
ChatOllama 用户手册
https://github.com/sugarforever/chat-ollama?tab=readme-ov-file#users-guide
Ollama https://ollama.ai
下载 docker
Install Docker Desktop on Windows | Docker Docs
我用的 Windows 系统
Ollama
Ollama https://ollama.ai
Ollama GitHub 仓库 ollama/ollama: Get up and running with Llama 2, Mistral, Gemma, and other large language models. (github.com)
选择 windows 预览版傻瓜式安装不多赘述,是很好的开源模型库,可以通过 GitHub 查看如何使用,为了方便学习,我摘录如下:
目前已入驻模型
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| 注意下载根据自己的内存来决定,推荐普通电脑用 qwen 1.8 b |
查询已安装的模型
ollama list
运行模型 windows 直接运行软件即可默认开机启动
ollama serve
配置 docker-compose.yaml
这个文件在 GitHub 仓库中有,找个位置放着。
version: '3.1'
services:
chromadb:
image: chromadb/chroma
ports:
- "8000:8000"
restart: always
volumes:
- chromadb_data:/chroma/.chroma/index
chatollama:
environment:
- CHROMADB_URL=http://chromadb:8000
- DATABASE_URL=file:/app/sqlite/chatollama.sqlite
- REDIS_HOST=redis
image: 0001coder/chatollama:latest
ports:
- "3000:3000"
pull_policy: always
restart: always
volumes:
- ~/.chatollama:/app/sqlite
redis:
image: redis:latest
restart: always
volumes:
- redis_data:/data
volumes:
chromadb_data:
redis_data:
配置解释:
这个文件定义了三个服务(services):chromadb、chatollama 和 redis,以及两个数据卷(volumes):chromadb_data 和 redis_data。
- chromadb:
- 使用镜像
chromadb/chroma,并映射端口将宿主机的 8000 端口与容器的 8000 端口进行绑定。 - 设置为始终重启 (
restart: always),意味着如果容器意外终止,则会自动重启它。 - 挂载数据卷
- chromadb_data:/chroma/.chroma/index,这意味着容器内的/chroma/.chroma/index目录会被持久化存储在宿主机上的chromadb_data卷中。
- 使用镜像
- chatollama:
- 设置环境变量,其中
CHROMADB_URL指向chromadb服务,DATABASE_URL表示使用 SQLite 数据库存储,并指向容器内部的/app/sqlite/chatollama.sqlite文件,REDIS_HOST设置为redis服务名称。 - 使用镜像
0001coder/chatollama:latest,并在宿主机上通过端口映射暴露应用在 3000 端口 (ports: - "3000:3000"). - 同样设置为始终重启,并且拉取策略是始终获取最新镜像 (
pull_policy: always)。 - 挂载宿主机目录
~/.chatollama到容器内/app/sqlite,用于持久化聊天应用相关的SQLite数据库文件。
- 设置环境变量,其中
- redis:
- 使用 Redis 的最新镜像。
- 设置为始终重启,并挂载数据卷
- redis_data:/data,将容器内的 Redis 数据持久化到宿主机的redis_data卷。
运行配置文件
在所在文件夹按住 CTRL+右键,呼出 cmd 运行以下代码
docker compose up
系统自动按照配置文件运行。
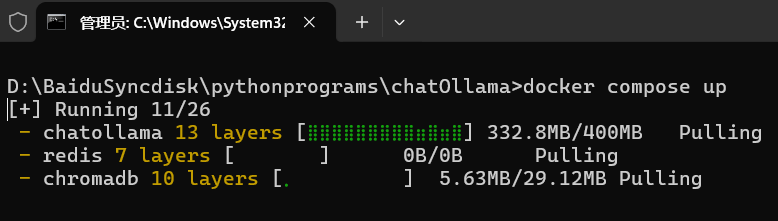
初始化数据库
程序运行完后,同样在在所在文件夹按住 CTRL+右键,呼出 cmd 运行以下代码初始化数据库。
docker compose exec chatollama npx prisma migrate dev
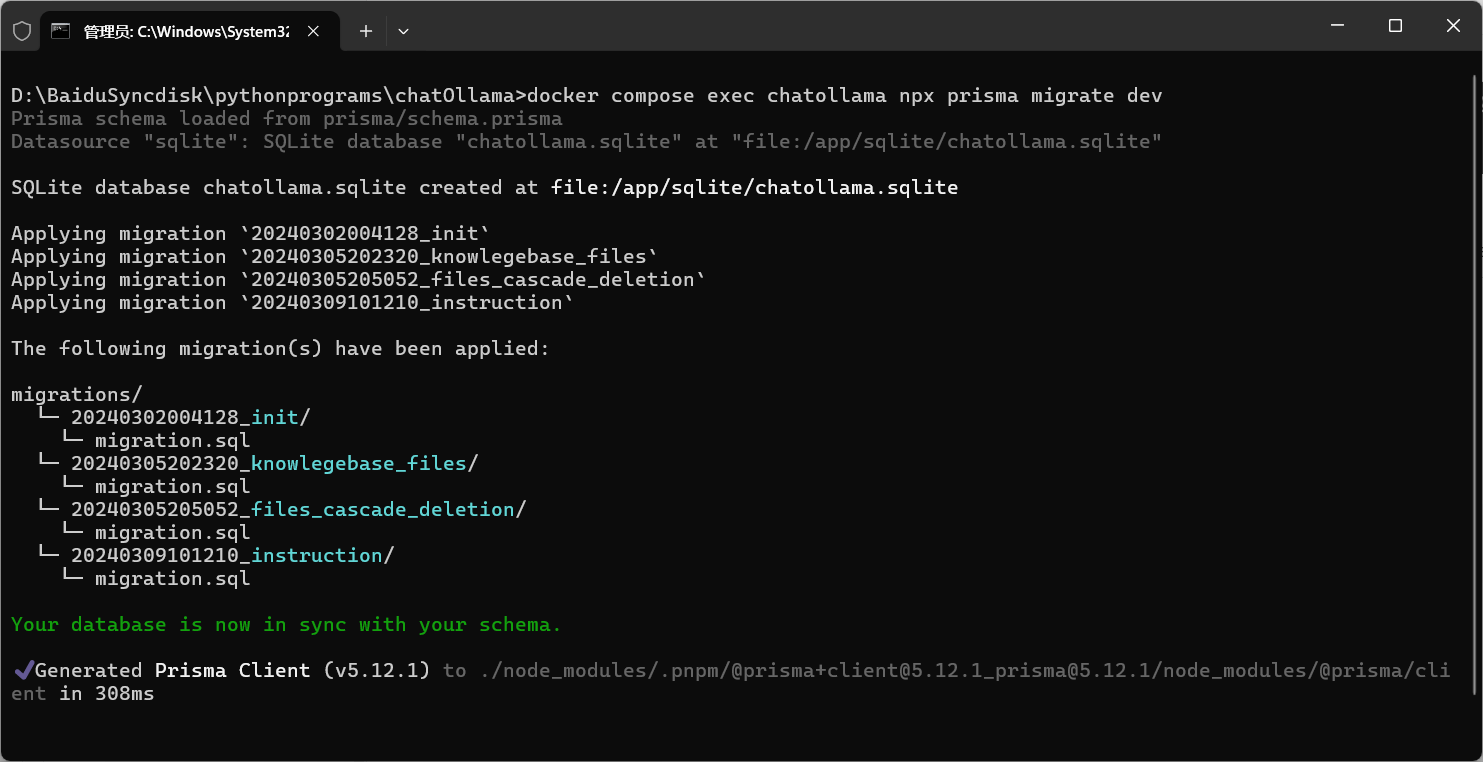
至此已经完成代码拉取。
浏览器输入 localhost: 3000 端口。就可以看到程序正常运行。
修改 ollama 窗口地址
由于 ChatOllama 在 Docker 容器内运行,如果您的 Ollama 服务器在本地以默认端口运行,请在设置中将 Ollama 服务器设置为 http://host.docker.internal:11434。
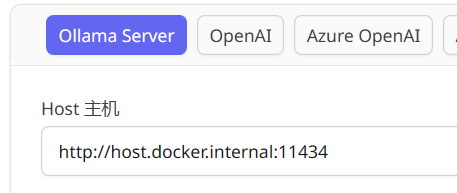
本地知识库搭建准备
使用知识库时,我们需要一个有效的嵌入模型。它可以是 Ollama 下载的模型之一,也可以是从第三方服务提供商(例如 OpenAI)下载的模型之一。
可以在ollama下载模型以进行嵌入。 nomic-embed-text
可以在模型页面 http://localhost:3000/models 上执行此操作,如果您使用的是 Docker,则可以通过以下 CLI 执行此操作。
# In the folder of docker-compose.yaml
$ docker compose exec ollama ollama pull nomic-embed-text:latest
当前实现的效果
该应用为开源程序,技术路线 ollama+JavaScript+Nuxt 3+RAG+LangChain+Redis+chromadb
RAG Retrieval-Augmented Generation 检索增强生成 是一种结合检索与生成技术的自然语言处理(NLP)架构。
Nuxt 3 是一个基于 Vue. Js 框架的静态网站生成器和应用框架。
基于 LangChain 高级 RAG 技术的本地知识库。它采用了 Chroma 作为向量存储,Redis 作为文档存储
推荐使用 Nomic-embed-text: latest 模型实现
目前实现的功能:
- 查询及下载 ollama 内模型
- 调用本地开源大预言模型
- 建立本地知识库,进行 RAG 检索
- 通过 api key 调用 chatgpt 等模型
我是纯新手,只是做好物分享,有什么不对的地方请指正。



















 8756
8756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











