






背景
本博文主要是创建了一个新的SpringBoot项目,实现基本的增删改查,分页查询,带条件的分页查询功能。是方便初学者学习后端项目的一个比较清晰明了的实践代码,读者可根据博文,从自己动手创建一个新的SpringBoot项目,到使用PostMan测试基本请求,完完全全实践一遍,写出自己的代码,或者实现自己想要的功能。因为在这个过程中会遇到许多的问题,从JDK的版本选择到跑通SpringBoot项目,最后到成功发起一个请求。所以,最好是自己练习一下,最终做到游刃有余。
环境的安装
本次SpringBoot项目主要用到,一是IDEA,二是MYSQL(服务端),三是DBeaver(一个数据库的客户端),四是PostMan(用于发送HTTP请求)。
建议读者先按照MYSQL包,再按照DBeaver, 调通数据库以后,再开始编写项目。
另外就是在一开始建立一个数据库的时候,这里不要写具体的名称。数据库连接以后,再定义具体的数据库名,mydatabase
我们本次的建表语句如下:
-- mydatabase.student_info definition | |
CREATE TABLE `student_info` ( | |
`id` int NOT NULL AUTO_INCREMENT, | |
`name` varchar(100) CHARACTER SET utf8mb3 NOT NULL DEFAULT '""', | |
`address` varchar(100) CHARACTER SET utf8mb3 NOT NULL, | |
`other` varchar(100) CHARACTER SET utf8mb3 NOT NULL, | |
`age` int NOT NULL, | |
PRIMARY KEY (`id`) | |
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=macce; |
建好表以后,往表中添加如下示例数据。添加好的表数据如下

创建一个新的SpringBoot项目
1、新建一个project;
这边我们使用maven管理依赖,maven的依赖管理目录可以单独设置一个空目录,自己比较好找到的目录,有时候依赖下载失败,需要从这个目录中删除一些依赖文件;目录的设置可在项目生成以后在IDEA中进行设置。然后jdk的版本有8 就选择8, 没有的话,这里随便选一下,后面编译的时候,可以在IDEA中重新设置。
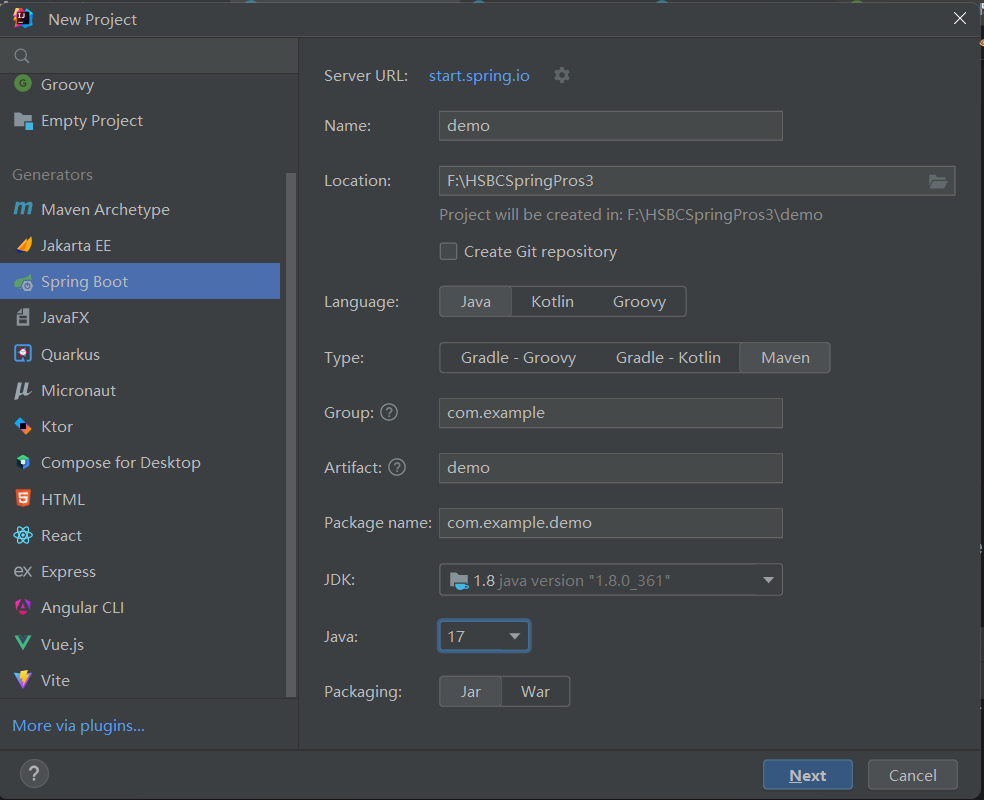
点击下一步,可以设置SpringBoot的版本。以及要在pom中引入哪些依赖包,方便我们后续写代码的时候调用。我这边简单选了几个,如果还有要使用的依赖,直接勾选就行,或者项目建好后手动在pom添加也可以。

,
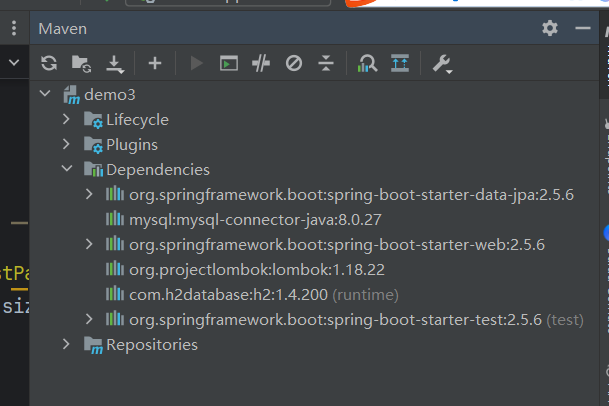
点击create, 并使用new windows打开,就得到一个新的SpringBoot项目。接下来就等待依赖下载成功,下载成功以后,maven的目录是这样的。本次项目的pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?> | |
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" | |
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> | |
<modelVersion>4.0.0</modelVersion> | |
<parent> | |
<groupId>org.springframework.boot</groupId> | |
<artifactId>spring-boot-starter-parent</artifactId> | |
<version>2.5.6</version> | |
<relativePath/> <!-- lookup parent from repository --> | |
</parent> | |
<groupId>com.example</groupId> | |
<artifactId>demo3</artifactId> | |
<version>0.0.1-SNAPSHOT</version> | |
<name>demo3</name> | |
<description>demo3</description> | |
<url/> | |
<licenses> | |
<license/> | |
</licenses> | |
<developers> | |
<developer/> | |
</developers> | |
<scm> | |
<connection/> | |
<developerConnection/> | |
<tag/> | |
<url/> | |
</scm> | |
<properties> | |
<java.version>8</java.version> | |
</properties> | |
<dependencies> | |
<dependency> | |
<groupId>org.springframework.boot</groupId> | |
<artifactId>spring-boot-starter-data-jpa</artifactId> | |
</dependency> | |
<dependency> | |
<groupId>mysql</groupId> | |
<artifactId>mysql-connector-java</artifactId> | |
</dependency> | |
<dependency> | |
<groupId>org.springframework.boot</groupId> | |
<artifactId>spring-boot-starter-web</artifactId> | |
</dependency> | |
<dependency> | |
<groupId>org.projectlombok</groupId> | |
<artifactId>lombok</artifactId> | |
<optional>true</optional> | |
</dependency> | |
<dependency> | |
<groupId>com.h2database</groupId> | |
<artifactId>h2</artifactId> | |
<scope>runtime</scope> | |
</dependency> | |
<dependency> | |
<groupId>org.springframework.boot</groupId> | |
<artifactId>spring-boot-starter-test</artifactId> | |
<scope>test</scope> | |
</dependency> | |
</dependencies> | |
</project> | |
配置文件 application.yml
配置文件中的数据库的用户名和密码都要和你实际进行数据库连接时配置的一样,url也是如此。
server.port: 8088 是tomcat的端口号。
com.mysql.cj.jdbc.Driver是一个驱动类,是MySQL Connector 驱动程序中的 JDBC 驱动类,用于在 Java 应用程序中建立与 MySQL 数据库的连接。 一旦建立了连接,JDBC 驱动类允许 Java 应用程序执行 SQL 查询、更新和其他数据库操作。应用程序可以使用 JDBC API 与数据库进行通信,发送和接收数据。JDBC 驱动类还支持事务管理。Java 应用程序可以使用 JDBC API 开启、提交或回滚事务,确保数据库操作的原子性、一致性、隔离性和持久性(ACID 属性)。在发生错误或异常时,驱动类也会生成适当的异常,应用程序可以捕获并处理这些异常。
加载驱动类是建立连接和执行数据库操作的第一步!
url 指的是数据库连接的 URL,它用于指定要连接的数据库的位置和其他连接参数,localhost指的是本地的主机名,3306是mysql的默认端口号。mydatabase是要连接的数据库的名称。应用程序和数据库通信,首先会通过该url建立连接,不过root和password需要和数据库连接配置中严格一致,否则会连不到数据库。
有关hibernate 的这段配置意味着通过 JPA 和 Hibernate 配置了禁用自动 DDL(Data Definition Language)生成、打印执行的SQL语句到控制台,以及指定了 Hibernate 使用的 MySQL 数据库方言是 MySQL 5 的 InnoDB 存储引擎方言。use_jdbc_metadata_defaults参数当设置为 false 时,Hibernate 将不使用 JDBC 元数据的默认设置。
重点说明一下ddl-auto, 等于none是指Hibernate 不会尝试自动创建、更新或删除数据库表结构。
server.port: 8088 | |
spring: | |
datasource: | |
driver-class-name: com.mysql.cj.jdbc.Driver | |
username: root | |
password: 123456 | |
url: jdbc:mysql://localhost:3306/mydatabase | |
jpa: | |
hibernate: | |
ddl-auto: none | |
show-sql: true | |
properties: | |
hibernate: | |
temp: | |
use_jdbc_metadata_defaults: false | |
dialect: org.hibernate.dialect.MySQL5InnoDBDialect | |
业务代码
在Web后端应用程序中,Controller主要接收来自用户的请求并根据请求调用适当的业务逻辑(Service层),然后将处理结果返回给用户。
总结的说,Controller的作用是:1、接收请求;2、调用Service层的方法;3、参数解析,对请求头中的参数进行解析;4、返回响应结果。将处理结果封装成适当的响应(如HTML页面、JSON数据等)返回给客户端。我这边为了方便起见,直接调repository中的方法了,后续补充一个Service层。
1、先写一个Controller
package com.example.demo3.controller; | |
import com.example.demo3.repository.StudentEntity; | |
import com.example.demo3.repository.StudentRepository; | |
import org.springframework.beans.factory.annotation.Autowired; | |
import org.springframework.data.domain.Page; | |
import org.springframework.data.domain.PageRequest; | |
import org.springframework.data.domain.Pageable; | |
import org.springframework.data.jpa.domain.Specification; | |
import org.springframework.web.bind.annotation.*; | |
import javax.persistence.criteria.CriteriaBuilder; | |
import javax.persistence.criteria.CriteriaQuery; | |
import javax.persistence.criteria.Predicate; | |
import javax.persistence.criteria.Root; | |
import java.util.List; | |
@RestController // 注意,该注解表明是是rest风格的API, 返回值通常是数据对象,Spring 将数据转换为JSON或者XML格式,返回给客户端。 | |
// controller返回的是视图名称或者ModelAndView对象。需要配置@ReponseBody使用,即在方法的前面加上这个注解。 | |
@RequestMapping("/student") | |
public class StudentController { | |
@Autowired | |
StudentRepository repository; | |
//查, 通过姓名查询 | |
@RequestMapping(value = "/byname", method = {RequestMethod.GET}) | |
//@ResponseBody | |
public List<StudentEntity> findByName(@RequestParam("name") String name) { | |
return repository.findByName(name); | |
} | |
// 全部返回,线上我们一般都用分页查询,因为数据量比较大嘛。直接返回全部数据的接口用的很少或者几乎不用。 | |
@GetMapping(value = "/all") | |
public List<StudentEntity> findAlls() { | |
List<StudentEntity> all = repository.findAll(); | |
return all; | |
} | |
// 增 | |
@PostMapping(value = "/add") | |
private String addOne(@RequestBody StudentEntity student){ | |
repository.save(student); | |
return "学生" + student.getName() + "添加成功"; | |
} | |
// 改 | |
@PutMapping(value = "/update") | |
private String updateOne(@RequestBody StudentEntity student){ | |
repository.save(student); | |
return "学生" + student.getName() + "修改成功"; | |
} | |
// 删 | |
@DeleteMapping(value = "/delete") | |
private String deleteOne(@RequestParam("id") Integer id) { | |
repository.deleteById(id); | |
return "学生" + id + "删除成功"; | |
} | |
// 简单分页查询 | |
@GetMapping("/page") | |
public Page<StudentEntity> findByPage(@RequestParam(value = "page", defaultValue = "0") int page, @RequestParam(value = "size", defaultValue = "2") Integer size) { | |
Pageable pageable = PageRequest.of(page, size); | |
return repository.findAll(pageable); | |
} | |
// 带条件复杂分页查询 | |
@GetMapping("/page2") | |
public Page<StudentEntity> findByPage2(@RequestParam(value = "name") String name, @RequestParam(value = "age") Integer age, @RequestParam(value = "page", defaultValue = "0") int page, @RequestParam(value = "size", defaultValue = "2") Integer size) { | |
Pageable pageable = PageRequest.of(page, size); | |
Specification<StudentEntity> specification = prediacte(name, age); | |
return repository.findAll(specification, pageable); | |
} | |
public static Specification<StudentEntity> prediacte(String name, Integer age) { | |
return (Root<StudentEntity> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) -> { | |
// 这边简单用name和age查询一下 | |
Predicate namePredicate = criteriaBuilder.equal(root.get("name"), name); | |
Predicate agePredicate = criteriaBuilder.equal(root.get("age"), age); | |
return criteriaBuilder.and(namePredicate, agePredicate); | |
}; | |
} | |
} |
2、Repository
这个是dao层,主要是执行一些和数据库交互的功能。在和数据库交互的时候,我们要创建一个实体类Entity, 这边我们叫做StudentEntity实体对象,相应的,数据库里面也应该有和这个实体类一一映射的表。数据库中的表名就可以写在注解@Table里。
@Entity注解的作用如下。首先, @Entity的含义是用于标识一个java类作为JPA(java persistence api)实体类, 表示该类将映射到数据库中的表。也就是说,实体类和数据库表的映射关系由该注解的实现,其中的映射关系具体体现在:实体类的属性和数据库表的字段一一对应。
@id注解用于表示某个字段作为表的主键,每个表必须要显式定义一个主键。
@Column 注解是 JPA(Java Persistence API)中用于描述实体属性与数据库表列之间映射关系的注解。通过 @Column 注解,可以指定实体类属性与数据库表中列的映射细节,如列名、数据类型、长度、是否可为空等。即可以更精细地控制实体属性与数据库表列的映射关系。如代码所示,name中指定的列名和表中的对应起来,然后private 属性就可以任意取一个名字了,不过建议还是都对应起来。
StudentEntity
package com.example.demo3.repository; | |
import lombok.Data; | |
import javax.persistence.*; | |
@Entity | |
@Table(name = "student_info") | |
@Data | |
public class StudentEntity { | |
@Id | |
@Column(name = "id") | |
@GeneratedValue(strategy = GenerationType.IDENTITY) | |
private int id; | |
@Column(name = "name") | |
private String name; | |
@Column(name = "age") | |
private int age; | |
@Column(name = "address") | |
private String address; | |
@Column(name = "other") | |
private String other; | |
} | |
以下是StudentRepository类,这边定义的几个方法都是直接调用Spring JPA 封装好的方法,可直接调用。如果遇到比较复杂的场景,我们也可以在这里写一个接口,再写接口方法的具体实现。
package com.example.demo3.repository; | |
import org.springframework.data.domain.Page; | |
import org.springframework.data.domain.Pageable; | |
import org.springframework.data.jpa.repository.JpaRepository; | |
import org.springframework.data.jpa.repository.JpaSpecificationExecutor; | |
import java.util.List; | |
public interface StudentRepository extends JpaRepository<StudentEntity, Integer>, JpaSpecificationExecutor<StudentEntity> { | |
List<StudentEntity> findByName(String name); | |
List<StudentEntity> findAll(); | |
void deleteById(Integer id); | |
Page<StudentEntity> findAll(Pageable pageable); | |
} |
测试结果
有两种测试方法,可以在网页端直接输入url发起HTTP请求,由于我们的HTTP请求中要使用对象,所以选择Postman会比较方便。
1、根据name查询

2、增加一个student

3、修改id=xx的学生的信息

4、删除id=xx的学生信息
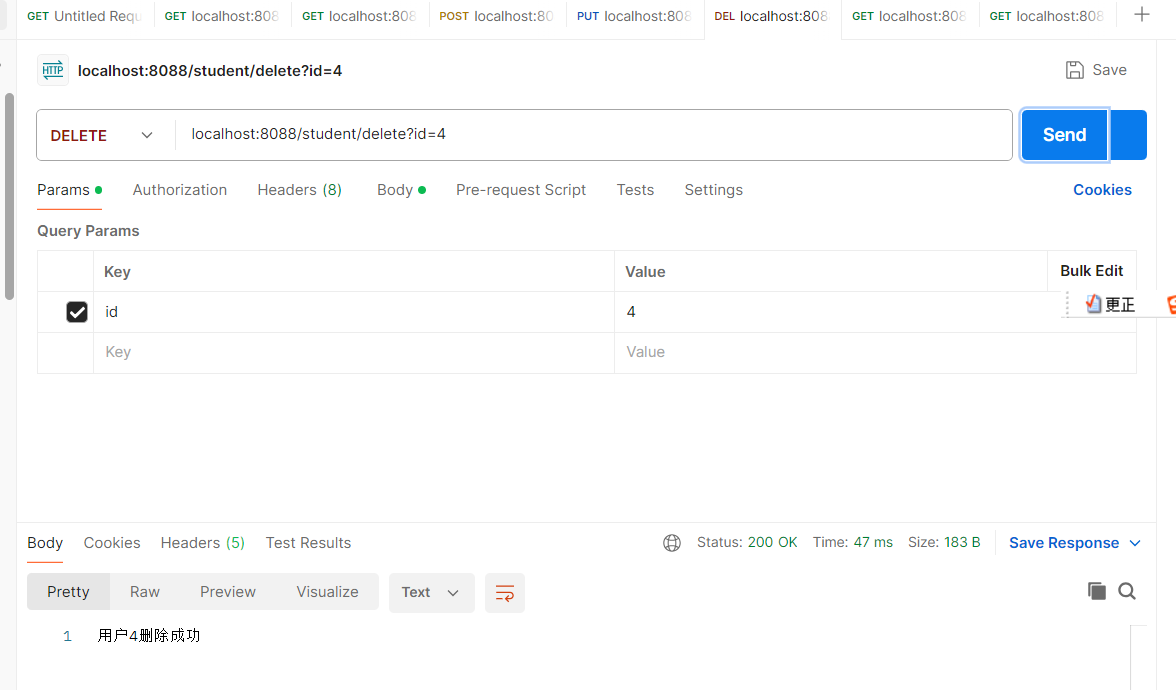
5、分页查询

我们默认的是取第0页的数据,每页取size个数据。 故"pageSize": 2,"pageNumber": 0。 totalPages指的是总共有多少条数据, "totalPages": 3指的是一共要分多少页。5条数据,每页2个数据,那么就是分3页。"sort"是分页时排序的属性。 | |
{ | |
"content": [ | |
{ | |
"id": 1, | |
"name": "小红", | |
"age": 18, | |
"address": "深圳市", | |
"other": "女;本科毕业,程序员" | |
}, | |
{ | |
"id": 2, | |
"name": "小黑", | |
"age": 29, | |
"address": "广州市", | |
"other": "男;本科毕业,程序员" | |
} | |
], | |
"pageable": { | |
"sort": { | |
"empty": true, | |
"sorted": false, | |
"unsorted": true | |
}, | |
"offset": 0, | |
"pageSize": 2, | |
"pageNumber": 0, | |
"paged": true, | |
"unpaged": false | |
}, | |
"totalElements": 5, | |
"last": false, | |
"totalPages": 3, | |
"number": 0, | |
"size": 2, | |
"sort": { | |
"empty": true, | |
"sorted": false, | |
"unsorted": true | |
}, | |
"numberOfElements": 2, | |
"first": true, | |
"empty": false | |
} |
6、带条件的分页查询

{
"content": [
{
"id": 2,
"name": "小黑",
"age": 29,
"address": "广州市",
"other": "男;本科毕业,程序员"
}
],
"pageable": {
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"offset": 0,
"pageNumber": 0,
"pageSize": 2,
"unpaged": false,
"paged": true
},
"last": true,
"totalPages": 1,
"totalElements": 1,
"number": 0,
"size": 2,
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"numberOfElements": 1,
"first": true,
"empty": false
}后面我会加一个Service层。今天就先写这么多吧。

















 6569
6569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











