







 本文介绍了Cortex-M系列处理器的指令集特点,包括从Cortex-M0到M33的不同型号所支持的指令集特性。涵盖了Thumb指令集的发展、DSP功能增强以及浮点运算的支持等内容。
本文介绍了Cortex-M系列处理器的指令集特点,包括从Cortex-M0到M33的不同型号所支持的指令集特性。涵盖了Thumb指令集的发展、DSP功能增强以及浮点运算的支持等内容。

Cortex-M 处理器ARM架构规范的规范
所有的Cortex-M 处理器都支持Thumb指令集。整套Thumb指令集扩展到Thumb-2版本时变得相当大。但是,不同的Cortex-M处理器支持不同的Thumb 指令集的子集,如下图所示(点击可查看大图)。

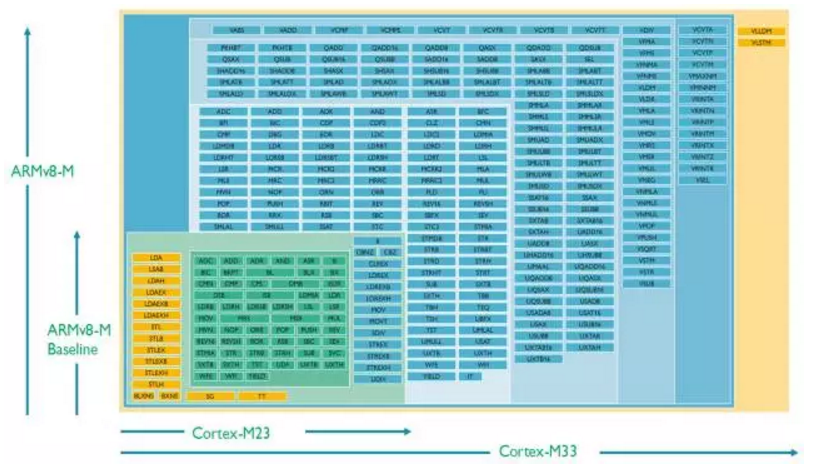
Cortex-M 处理器的指令集
> > > >
Cortex-M0/M0+/M1指令集
Cortex-M0/M0+/M1处理器基于ARMv6-M架构。这是一个只支持56条指令的小指令集,大部分指令是16位指令,如图3所示只占很小的一部分。但是,此类处理器中的寄存器和处理的数据长度是32位的。对于大多数简单的I/O控制任务和普通的数据处理,这些指令已经足够了。这么小的指令集可以用很少的电路门数来实现处理器设计,Cortex-M0 和 Cortex-M0+最小配置仅仅12K门。然而,其中的很多指令无法使用高位寄存器(R8 到R12), 并且生成立即数的能力有限。这是平衡了超低功耗和性能需求的结果。
> > > >
Cortex-M3指令集
Cortex-M3处理器是基于ARMv7-M架构的处理器,支持更丰富的指令集,包括许多32位指令,这些指令可以高效的使用高位寄存器。另外,M3还支持:
-
查表跳转指令和条件执行(使用IT指令)
-
硬件除法指令
-
乘加指令(MAC)
-
各种位操作指令
更丰富的指令集通过几种途径来增强性能:例如,32位Thumb指令支持了更大范围的立即数,跳转偏移和内存数据范围的地址偏移。支持基本的DSP操作(例如,支持若干条需要多个时钟周期执行的MAC指令,还有饱和运算指令)。最后,这些32位指令允许用单个指令对多个数据一起做桶型移位操作。
支持更丰富的指令导致了更大的面积成本和更高的功耗。典型的微控制器,Cortex-M3的电路门数是Cortex-M0 和 Cortex-M0+两倍还多。但是,处理器的面积只是大多数现代微控制器的很小的一部分,多出来的面积和功耗经常不那么重要。
> > > >
Cortex-M4指令集
Cortex-M4在很多地方和Cortex-M3相同:流水线,编程模型。Cortex-M4支持Cortex-M3的所有功能,并额外支持各种面向DSP应用的指令,像SIMD, 饱和运算指令,一系列单周期MAC指令(Cortex-M3只支持有限条MAC指令,并且是多周期执行的),和可选的单精度浮点运算指令。
Cortex-M4的SIMD操作可以并行处理两个16位数据和4个8位数据。例如,下图展示的QADD8 和 QADD16 操作:
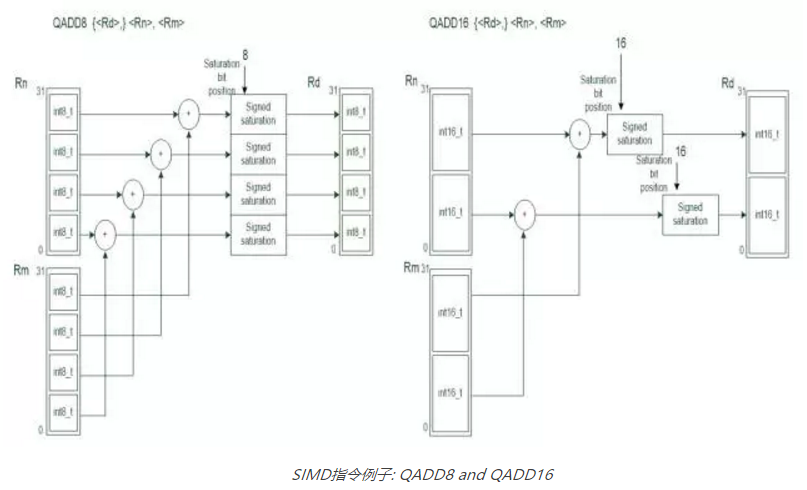
SIMD指令例子: QADD8 and QADD16
在某些DSP运算中,使用SIMD可以加速更快计算16位和8位数据,因为这些运算可以并行处理。但是,一般的编程中,C编译器并不能充分利用SIMD运算能力。这是为什么Cortex-M3 和 Cortex-M4典型benchmark的分数差不多。然而,Cortex-M4的内部数据通路和Cortex-M3的不同,某些情况下Cortex-M4可以处理的更快(例如,单周期MAC,可以在一个周期中写回到两个寄存器)。
> > > >
Cortex-M7指令集
Cortex-M7支持的指令集和Cortex-M4相似,添加了:
-
浮点数据架构是基于FPv5的,而不是Cortex-M4的FPv4,所以Cortex-M7支持额外浮点指令
-
可选的双精度浮点数据处理指令
-
支持缓存数据预取指令(PLD)
Cortex-M7的流水线和Cortex-M4的非常不同。Cortex-M7是6级双发射流水线,可以获得更高的性能。多数为Cortex-M4设计的软件可以直接运行在Cortex-M7上。但是,为了充分利用流水线差异来达到最好的优化,软件需要重新编译,并且在许多情况下,软件需要一些小的升级,以充分利用像Cache这样的新功能。
> > > >
Cortex-M23指令集
Cortex-M23的指令集是基于ARMv8-M的Baseline子规范,它是ARMv6-M的超集。扩展的指令包括:
-
硬件除法指令
-
比较和跳转指令,32位跳转指令
-
支持TrustZone安全扩展的指令
-
互斥数据访问指令(通常用于信号量操作)
-
16位立即数生成指令
-
载入获取及存储释放指令(支持C11)
在某些情况下,这些增强的指令集可以提高处理器性能,并且对包含多个处理器的SoC设计有用(例如,互斥访问对多处理器的信号量处理有帮助)
> > > >
Cortex-M33指令集
因为Cortex-M33设计是非常可配置的,某些指令也是可选的。例如:
-
DSP指令(Cortex-M4 和Cortex-M7支持的)是可选的。
-
单精度浮点运算指令是可选的,这些指令是基于FPv5的,并且比Cortex-M4多几条。
Cortex-M33也支持那些ARMv8-M Mainline引入的新指令:
-
支持TrustZone安全扩展的指令
-
载入获取及存储释放指令(支持C11)
指令集特性比较总结
ARMv6-M, ARMv7-M 和 ARMv8-M架构有许多指令集功能特点, 很难介绍到所有的细节。但是,下面的表格总结了那些关键的差异。
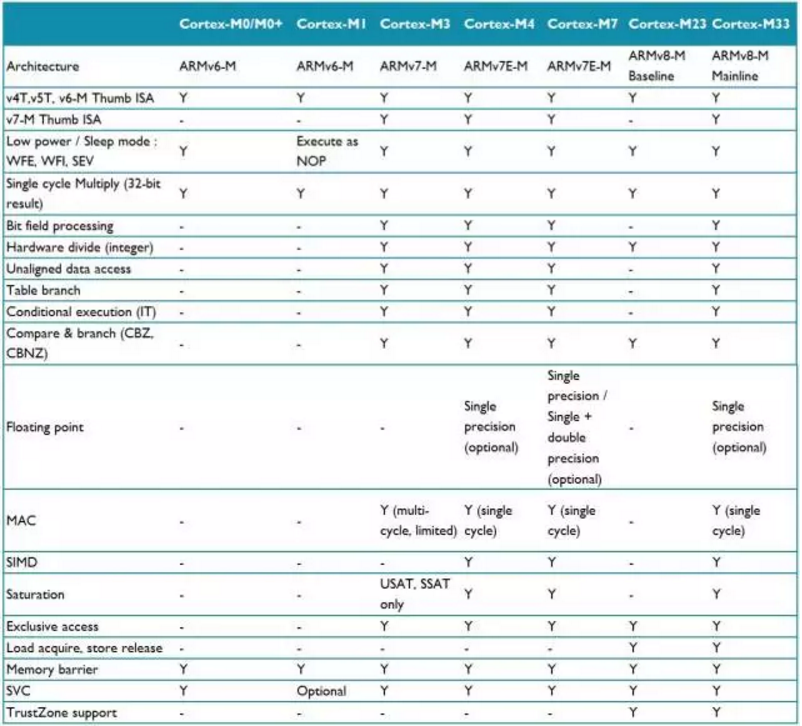
指令集特性总结
Cortex-M处理器指令集的最重要的特点是向上兼容。Cortex-M3的指令是Cortex-M0/M0+/M1的超集。所以,理论上讲,如果存储空间分配是一致的,运行在Cortex-M0/M0+/M1上的二进制文件可以直接运行在Cortex-M3上。同样的原理也适用于Cortex-M4/M7和其他的Cortex-M处理器;Cortex-M0/M0+/M1/M3支持的指令也可以运行在Cortex-M4/M7上。
虽然Cortex-M0/M0+/M1/M3/M23处理器没有浮点运算单元配置选项,但是处理器仍然可以利用软件来做浮点数据运算。这也适用于基于Cortex-M4/M7/M33但是没有配置浮点运算单元的产品。在这种情况下,当程序中使用了浮点数,编译工具包会在链接阶段插入需要的运行软件库。软件模式的浮点运算需要更长的运行时间,并且会略微的增加代码大小。但是,如果浮点运算不是频繁使用的,这种方案是适合这种应用的。

















 2619
2619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









