









看到这样的python代码,很懵逼???
[n for n in range(1, dividend+1) if dividend % n == 0]或者这个:
f = list(zip(prob,labels)) rank = [values2 for values1, values2 in sorted(f, key=lambda x:x[0])]查了一下,这种写法是 list comprehension (下文简记为lc)被翻译为 列表推导式。
读完这篇教程,你能了解py中lc与另一门非常流行的脚本语言js的异同,并写出这样让新手摸不着头脑的代码。
——黎明的那道光的会越过黑暗,打破一切恐惧我能找到答案。
目录
1. 使用lc之前的世界
正常地使用一个list之前首先创建一个list:
1.1 使用append创建一个指定长度的数组
a_list = []
for i in range(10):
a_list.append(i)
print(a_list)
如果要修改其中的元素,最基本的方法:(遍历数组常见方法:参考博客)
a_list = []
for i in range(10):
a_list.append(i)
print(a_list)
for i in range(len(a_list)):
a_list[i] = a_list[i] - 1
print(a_list) ![]()
1.2 使用map高效遍历数组
类似Javascript的map,在JS中,使用map(传入一个函数作为参数,这里传入了一个匿名函数(arrow function))可以返回一个数组(forEach仅仅遍历返回)。
let a = [1, 2, 3, 4, 5];
re = a.map((e) => Math.pow(e, 2));
console.log(re);![]()
在python中,也可以使用map对可迭代(iterable)对象进行map的处理,传入一个函数:
map(func, iter)下面使用map方法对a_list进行处理,并对得到的map object使用list方法强制转换为list
a_list = []
for i in range(10):
a_list.append(i)
print(a_list)
def func(e):
return e**2 + .03
re = list(map(func, a_list))
print(re)
1.3 使用lc替代append
但是使用lc就不一样了,同样创建一个含有[1, 2, 3, ..., 10]的list,lc只需要一行:
lc_list = [x for x in range(10)]
print(lc_list)![]()
分析一下其语法形式:
[ele's expression for loop]分成两部分看,前半部分是ele的表达式——“ele's expression”,后半部分是for loop,这里的写法和1.1中讨论的循环遍历方法完全一致。
更好的理解ele's expression & for loop => 再来几个例子:
1.3.1 lc + enumerate
re = [0.03, 1.03, 4.03, 9.03, 16.03, 25.03, 36.03, 49.03, 64.03, 81.03]
lc_list = [index + element for index, element in enumerate(re)]
print(lc_list)![]()
1.3.2 lc + for in range
lc_list = [ele**2 for ele in range(10)]
print(lc_list) ![]()
1.3.3 lc + const + for
lc_list = [1 for ele in range(10)]
print(lc_list)![]()
1.3.4 lc + random + for
import random
lc_list = [random.randint(1, 100) for ele in range(10)]
print(lc_list)![]()
1.3.5 lc + func + for
import random
def ret_alpha():
box = ['a', 'b', 'c', 'd', 'e']
return box[random.randint(0, len(box)-1)]
lc_list = [ret_alpha() for ele in range(10)]
print(lc_list)
![]()
2. 更长的lc——加上条件判断
[n for n in range(1, dividend+1) if dividend % n == 0]开头的python语句已经懂了前一半,现在还剩下后一半:
if dividend % n == 0能够猜出,这里应该是通过这个if来是过滤掉某些n值,使得最终得到的list只包含for loop中的感兴趣元素。
给lc添加过滤条件的一般语法是:
[ele's expression for loop [if statement]] # [] means optional 将1中的例子加上条件判断,我们可以生成含偶数和指定基数的列表:
lc_list = [i for i in range(10) if i % 2 == 0 or i == 3]
print(lc_list)![]()
当然可以来点有意思的,加上天气:
def get_weather():
return "rainy"
lc_list = [i for i in range(10) if i % 2 == 0 or (i == 3 and get_weather() == 'sunny')]
print(lc_list)
![]()
3. 更复杂的lc——加上lambda表达式
3.1 python中的lambda表达式
为了保证完整性,这里仅仅做简单介绍,完整的python lambda结合装饰器、Type Annotations(类似JS->TS的进化)等高级内容的应用:参考资料
与JS不同,JS中的this指针会在arrow function(js中的箭头函数,即js中的匿名函数)中获得外部作用域中的this的空间作用域,而python中lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。python中的lambda表达式的一般表示为:
lambda [arg1 [,arg2,.....argn]] : expression另一个与JS的Arrow function的显著区别是:JS中的匿名函数可以拓展为很复杂的函数,但是python则只能有一行:
下面举一个JS封装的获取天气的API例子,里面对箭头函数进行了拓展 {}
// js 的 arrow function 带有 {} 的拓展形式
function getWeather(woeid) {
fetch(`http://cors-anywhere.herokuapp.com/https://www.metaweather.com/api/location/${woeid}/`)
.then((data) => {
console.log(data);
return data.json();
})
.then((result) => {
const location = result.title;
const weather_today = result.consolidated_weather[0];
console.log(`Temperature in ${location} stay between ${weather_today.min_temp} and ${weather_today.max_temp}`);
})
.catch((error) => {
console.log(error);
});
}
在js的=>不进行{}拓展的时候,JS和Python一样,JS中 "=>" 后面的部分为匿名函数的返回值而不必显式地指明return,Python中 ":" 后面的表达式为返回值也不需要显式地指明return,例如:
def loop_man_func(arr, func):
return [func(e) for e in arr]
def main():
a = 10
b = 20
add_func = lambda a, b: a + b
print(type(add_func))
print(add_func(6, 7))
print((lambda x: x * x)(3))
print(loop_man_func([i for i in range(10)], lambda x : x * x + 3))
if __name__ == "__main__":
main()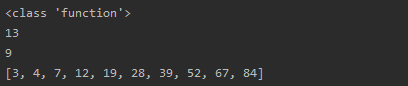
分析:
![]()
lambda expression 返回一个 function。
![]()
类似js,可以调用一个以匿名函数声明但被绑定到一个变量的函数。
![]()
类似js,可以使用IIFE(immediate invoke function expression)技术。
![]()
lambda表达式可以作为一个参数被传入高阶函数中。
下面来分析如何讲lc和lambda结合使用。
3.2 将lc和lambda混在一起[易错]
# Mix lc with lambda
lucky_num = 7
func_list = [lambda x : x + e for e in range(22) if e % lucky_num == 0]
result_list = [func(lucky_num) for func in func_list]
print(result_list)有了上面的学习的知识,你可能会认为这里的输出为 [7, 14, 21, 28]。
但是,这里的输出其实为:
![]()
lc和lambda混在一起很容易逻辑错误的代码,这是因为python内部的内存管理机制——延迟绑定,下面分析原因。
在我们的设想中,e的值应该为0, 7, 14, 21,上面代码的等效代码为:
lucky_num = 7
def anonymous_func():
re_list = []
for e in range(22):
if e % lucky_num == 0:
def func(x):
return x + e
re_list.append(func)
return re_list
func_list = anonymous_func()
result_list = [func(lucky_num) for func in func_list]
print(result_list)可以发现,被压缩为一行的代码:
func_list = [(lambda x : x + e) for e in range(22) if e % lucky_num == 0]其实是这段代码的简写:
def anonymous_func():
re_list = []
for e in range(22):
if e % lucky_num == 0:
def func(x):
return x + e
re_list.append(func)
return re_list
func_list = anonymous_func()那么在anonymous_func函数被调用之后,这个函数返回了一个函数指针列表(这与C++是不同的,C++中不允许函数指针数组的出现),即这里涉及到了一个函数式编程中的一个核心问题——闭包(closure)。
在函数返回后,返回的内层函数仍然能够使用原来外层函数中的变量和函数,而且外层的变量和函数在返回的瞬间就会“凝固”,举个例子:
import random
def outer_func():
rand_num = random.randint(1, 100)
def inner_func():
return rand_num
return inner_func
def main():
rand_gen_func = outer_func()
for i in range(10):
print(rand_gen_func(), end = " ")
if __name__ == "__main__":
main()每次运行,输出的10个结果都是一样的(不同次可能不一样),而不会因为因为10次调用而得到10个不同的随机数:

在Python3中,闭包中返回的内层调用外层参数和函数的时候有“动态加载”的特性,也就是,非内部函数本身成员,仅当在内层函数被调用的时候,Python解释器才会去闭包中寻找“凝固的数据”,实现调用。
所以,将数据移入成为内层函数的参数就可以解决这个问题:
lucky_num = 7
def anonymous_func():
re_list = []
for e in range(22):
if e % lucky_num == 0:
def func(x, inner_e=e):
return x + inner_e
re_list.append(func)
return re_list
func_list = anonymous_func()
result_list = [func(lucky_num) for func in func_list]
print(result_list)由于这里指定了默认参数,所以python必须为内层的每一个函数空间保存一份对应的默认参数,最后的结果和预期一致:

3.3 解决lambda的延迟绑定问题
lucky_num = 7
func_list = [(lambda x, inner_e=e : x + inner_e) for e in range(22) if e % lucky_num == 0]
result_list = [func(lucky_num) for func in func_list]
print(result_list)
4. 再看开头的代码
4.1 补充:sort 与 sorted 区别
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
值得主义的是,查询发现一些sorted中的cmp参数已经在python3.8中废弃,即未来版本都只能使用指定key实现。
更多文档信息:参考资料
4.2 代码分析
f = list(zip(prob, labels))
rank = [values2 for values1, values2 in sorted(f, key=lambda x:x[0])]zip的理解:参考资料
对于prob和labels题目中已经有说明:

具体的数据为:
prob:
np.array([0.1, 0.4, 0.3, 0.8])labels:
np.array([0, 0, 1, 1])那么使用zip打包并list序列化之后f为:
[(0.1, 0), (0.4, 0), (0.3, 1), (0.8, 1)]通过sorted方法的key关键字指定排序的key为x[0],即根据概率升序排序,例如对于(0.1, 0)则取0.1在排序中进行比较。
这里不能直接写:key=x[0],会报错,只能按照上面这种方式书写。
【低版本python可写为sorted(f, cmp=lambda x,y:cmp(x[0],y[0]))】

这样就得到了按照概率排序的rank的值。
如果题目改为降序,则对reverse关键字声明为True即可:
rank = [values2 for values1,values2 in sorted(f, key=lambda x:x[0], reverse=True)]但是比较奇怪的是,我在排序时加上reverse之后再对结果进行reverse最终只能过一组数据:
rank = [values2 for values1,values2 in sorted(f, key=lambda x:x[0], reverse=True)]
rank = rank[::-1]测评结果:















 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









