









东方财富网的研究报告数据,是进行数据分析以及做量化策略的重要数据来源,本文将用Python实现一个批量获取研报发布数据的网络爬虫,实现步骤如下:
首先打开个股研报发布网址:个股研报
此时网站会弹出一个图片

该图片为遮罩层,会阻止爬虫抓取数据,所以需要先关闭该图片,分析网页源码结构,找到关闭该图片的网页源码
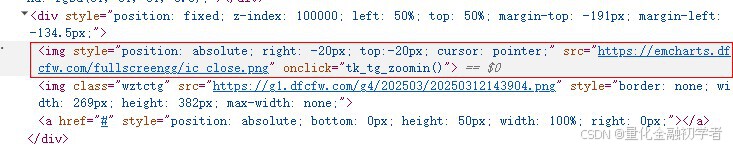
用Python代码实现关闭图片过程:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# 配置
driver_path = 'chromedriver.exe' #注意此处要把chromedriver.exe所在的文件夹路径补全
service = Service(driver_path)
options = webdriver.ChromeOptions()
# options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.198 Safari/537.36")
# options.add_argument('--disable-blink-features=AutomationControlled') # 绕过浏览器的自动化检测
driver = webdriver.Chrome(service=service, options=options)
# 目标 URL
driver.get("https://data.eastmoney.com/report/stock.jshtml")
try:
# 等待关闭按钮出现并可点击
close_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "img[src='https://emcharts.dfcfw.com/fullscreengg/ic_close.png']"))
)
# 点击关闭按钮
close_button.click()
print("成功关闭遮罩层")
except Exception as e:
print(f"关闭遮罩层时出错: {e}")接下来展示研报发布内容,以及对应的网页源码
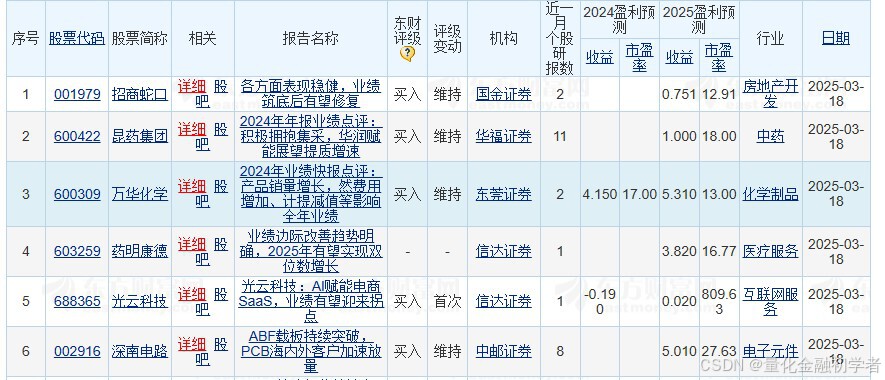
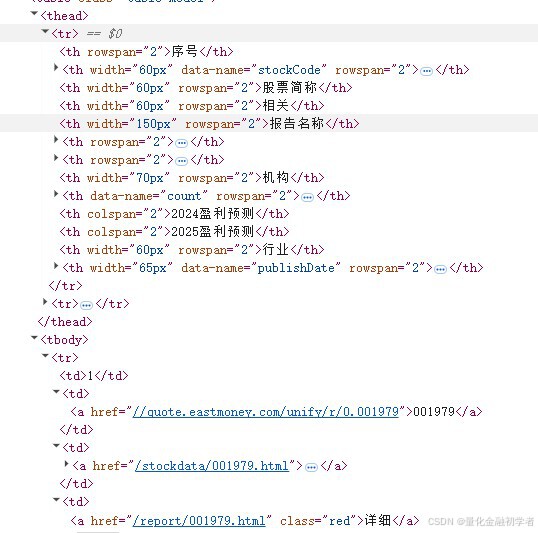
以下用Python代码实现获取研报发布内容
# 存储数据的字典
data = {
'序号': [],
'股票代码': [],
'股票名称': [],
'详细链接': [],
'报告标题': [],
'评级': [],
'评级变动': [],
'机构名称': [],
'近一月个股研报数': [],
'2024盈利预测收益': [],
'2024盈利预测市盈率': [],
'2025盈利预测收益': [],
'2025盈利预测市盈率': [],
'行业': [],
'日期': []
}
# 设置要爬取的页数
pages_to_crawl = 100
# 爬取指定页数的数据
for page in range(pages_to_crawl):
try:
# 等待表格加载完成(至少有一行数据)
WebDriverWait(driver, 60).until(
EC.presence_of_element_located((By.XPATH, "//div[@id='stock_table']"))
)
# 提取数据
rows = driver.find_elements(By.XPATH, "//div[@id='stock_table']//tbody/tr")
for row in rows:
try:
# 序号
serial = row.find_element(By.XPATH, "./td[1]").text.strip()
# 股票代码
stock_code = row.find_element(By.XPATH, "./td[2]/a").text.strip()
# 股票名称
stock_name = row.find_element(By.XPATH, "./td[3]/a/span").get_attribute("title")
# 详细链接
detail_url = row.find_element(By.XPATH, "./td[4]/a[1]").get_attribute("href")
# 报告标题
report_title = row.find_element(By.XPATH, "./td[5]/a").text.strip()
# 评级
rating = row.find_element(By.XPATH, "./td[6]").text.strip()
# 评级变动
rating_change = row.find_element(By.XPATH, "./td[7]").text.strip()
# 机构名称
institution = row.find_element(By.XPATH, "./td[8]/a").text.strip()
# 近一月个股研报数
research_count = row.find_element(By.XPATH, "./td[9]").text.strip()
# 2024盈利预测收益
predict_2024_eps = row.find_element(By.XPATH, "./td[10]").text.strip()
# 2024盈利预测市盈率
predict_2024_pe = row.find_element(By.XPATH, "./td[11]").text.strip()
# 2025盈利预测收益
predict_2025_eps = row.find_element(By.XPATH, "./td[12]").text.strip()
# 2025盈利预测市盈率
predict_2025_pe = row.find_element(By.XPATH, "./td[13]").text.strip()
# 行业
industry = row.find_element(By.XPATH, "./td[14]/a").text.strip()
# 日期
date = row.find_element(By.XPATH, "./td[15]").text.strip()
# 存入字典
data['序号'].append(serial)
data['股票代码'].append(stock_code)
data['股票名称'].append(stock_name)
data['详细链接'].append(detail_url)
data['报告标题'].append(report_title)
data['评级'].append(rating)
data['评级变动'].append(rating_change)
data['机构名称'].append(institution)
data['近一月个股研报数'].append(research_count)
data['2024盈利预测收益'].append(predict_2024_eps)
data['2024盈利预测市盈率'].append(predict_2024_pe)
data['2025盈利预测收益'].append(predict_2025_eps)
data['2025盈利预测市盈率'].append(predict_2025_pe)
data['行业'].append(industry)
data['日期'].append(date)
except Exception as e:
print(f"解析行时出错: {e}")
continue为了抓取更多数据,必须实现翻页功能,如下:

对应的网页源码如下:

用Python实现点击“下一页”实现翻页功能如下:
# 点击下一页
if page < pages_to_crawl - 1: # 最后一页不点击下一页
next_page_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//div[@class='pagerbox']/a[contains(text(), '下一页')]"))
)
next_page_button.click()
time.sleep(2) # 等待页面加载
最后把网页获取到的数据保存到report_data.xlsx文件
下面将完整代码奉上:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# 配置
driver_path = 'chromedriver.exe' #注意此处要把chromedriver.exe所在的文件夹路径补全
service = Service(driver_path)
options = webdriver.ChromeOptions()
# options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.198 Safari/537.36")
# options.add_argument('--disable-blink-features=AutomationControlled') # 绕过浏览器的自动化检测
driver = webdriver.Chrome(service=service, options=options)
# 目标 URL
driver.get("https://data.eastmoney.com/report/stock.jshtml")
try:
# 等待关闭按钮出现并可点击
close_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "img[src='https://emcharts.dfcfw.com/fullscreengg/ic_close.png']"))
)
# 点击关闭按钮
close_button.click()
print("成功关闭遮罩层")
except Exception as e:
print(f"关闭遮罩层时出错: {e}")
# 存储数据的字典
data = {
'序号': [],
'股票代码': [],
'股票名称': [],
'详细链接': [],
'报告标题': [],
'评级': [],
'评级变动': [],
'机构名称': [],
'近一月个股研报数': [],
'2024盈利预测收益': [],
'2024盈利预测市盈率': [],
'2025盈利预测收益': [],
'2025盈利预测市盈率': [],
'行业': [],
'日期': []
}
# 设置要爬取的页数
pages_to_crawl = 100
# 爬取指定页数的数据
for page in range(pages_to_crawl):
try:
# 等待表格加载完成(至少有一行数据)
WebDriverWait(driver, 60).until(
EC.presence_of_element_located((By.XPATH, "//div[@id='stock_table']"))
)
# 提取数据
rows = driver.find_elements(By.XPATH, "//div[@id='stock_table']//tbody/tr")
for row in rows:
try:
# 序号
serial = row.find_element(By.XPATH, "./td[1]").text.strip()
# 股票代码
stock_code = row.find_element(By.XPATH, "./td[2]/a").text.strip()
# 股票名称
stock_name = row.find_element(By.XPATH, "./td[3]/a/span").get_attribute("title")
# 详细链接
detail_url = row.find_element(By.XPATH, "./td[4]/a[1]").get_attribute("href")
# 报告标题
report_title = row.find_element(By.XPATH, "./td[5]/a").text.strip()
# 评级
rating = row.find_element(By.XPATH, "./td[6]").text.strip()
# 评级变动
rating_change = row.find_element(By.XPATH, "./td[7]").text.strip()
# 机构名称
institution = row.find_element(By.XPATH, "./td[8]/a").text.strip()
# 近一月个股研报数
research_count = row.find_element(By.XPATH, "./td[9]").text.strip()
# 2024盈利预测收益
predict_2024_eps = row.find_element(By.XPATH, "./td[10]").text.strip()
# 2024盈利预测市盈率
predict_2024_pe = row.find_element(By.XPATH, "./td[11]").text.strip()
# 2025盈利预测收益
predict_2025_eps = row.find_element(By.XPATH, "./td[12]").text.strip()
# 2025盈利预测市盈率
predict_2025_pe = row.find_element(By.XPATH, "./td[13]").text.strip()
# 行业
industry = row.find_element(By.XPATH, "./td[14]/a").text.strip()
# 日期
date = row.find_element(By.XPATH, "./td[15]").text.strip()
# 存入字典
data['序号'].append(serial)
data['股票代码'].append(stock_code)
data['股票名称'].append(stock_name)
data['详细链接'].append(detail_url)
data['报告标题'].append(report_title)
data['评级'].append(rating)
data['评级变动'].append(rating_change)
data['机构名称'].append(institution)
data['近一月个股研报数'].append(research_count)
data['2024盈利预测收益'].append(predict_2024_eps)
data['2024盈利预测市盈率'].append(predict_2024_pe)
data['2025盈利预测收益'].append(predict_2025_eps)
data['2025盈利预测市盈率'].append(predict_2025_pe)
data['行业'].append(industry)
data['日期'].append(date)
except Exception as e:
print(f"解析行时出错: {e}")
continue
# 点击下一页
if page < pages_to_crawl - 1: # 最后一页不点击下一页
next_page_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//div[@class='pagerbox']/a[contains(text(), '下一页')]"))
)
next_page_button.click()
time.sleep(2) # 等待页面加载
except Exception as e:
print(f"爬取第 {page + 1} 页时出错: {e}")
break
# 转换为 DataFrame
df = pd.DataFrame(data)
df.to_excel(r".\report_data.xlsx", index=False)
# 关闭浏览器
driver.quit()
















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









