






导入相关包
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
创建数据
X = np.arange(1,20) # 创建X数据
def fun(x,a,b):
return a*x + b
y = fun(X,3,2) # 创建 y = 3*x+2
np.random.seed(2) # 控制每次随机误差数据相同
y_noise =np.random.normal(1,0.5,19) #生成正态分布数据(1,0.5,19)数据大小在1左右,sigma = 0.5 ,19个数据
y = fun(X,3,2)+y_noise #加入误差数据
数据准备
data = {
'X' : X,
'y' : y
}
data = pd.DataFrame(data)
使用OLS来预测数据
X1 = sm.add_constant(X) #增加常数
est = sm.OLS(y,X).fit()
est.summary()

参数解析请参照:
https://blog.csdn.net/weixin_39677419/article/details/110830152
这里就关注:
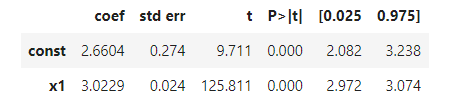
这个x1就相当于y=a*x +b 中的参数 a,const 相当于常数b
绘制图形
fig = plt.figure(figsize=(15,10))
sm.graphics.plot_regress_exog(est,'x1',fig=fig)
意思是针对一个回归模型绘制回归结果。

左上图:表示预测值跟真实值之间的差值
右上图:表示x1的残差图。X坐标为x1的值,Y坐标表示x1对应的残差值,也就是左上图中蓝点跟黄点之间的距离差。
点离中间的直线越近表示模型更加有效
左下图:显示的是考虑新增其他自变量时,X与y之间的关系。
右下图:显示的是左下图图像的延申,反映了考虑新增其他自变量后反应两者关系的直线将如何变化。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









