






分布式系统中,有一些需要使用全局唯一 ID 的场景,这种时候为了防止 ID 冲突可以使用 36 位的 UUID,但是 UUID 有一些缺点,首先他相对比较长,另外 UUID 一般是无序的。
有些时候我们希望能使用一种简单些的 ID,并且希望 ID 能够按照时间有序生成。
什么是雪花算法
雪花算法(SnowFlake)是 Twitter 开源的分布式 ID 生成算法。
Twitter 雪花算法生成后是一个 64bit 的 long 型的数值,组成部分引入了时间戳,基本保持了自增。
SnowFlake 算法的优点:
- 高性能高可用:生成时不依赖于数据库,完全在内存中生成。
- 高吞吐:每秒钟能生成数百万的自增 ID。
- ID 自增:存入数据库中,索引效率高(涉及到MySQL主键优化的页分裂问题)。
SnowFlake 算法的缺点:
依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成 ID 冲突或者重复。
1. 雪花算法组成
snowflake 结构如下图所示:

包含四个组成部分:
- 不使用:1bit,最高位是符号位,0 表示正,1 表示负,固定为 0。
- 时间戳:41bit,毫秒级的时间戳(41 位的长度可以使用 69 年)。
- 标识位:5bit 数据中心 ID,5bit 工作机器 ID,两个标识位组合起来最多可以支持部署 1024 个节点。
-
序列号:12bit 递增序列号,表示节点毫秒内生成重复,通过序列号表示唯一,12bit 每毫秒可产生 4096 个 ID。通过序列号 1 毫秒可以产生 4096 个不重复 ID,则 1 秒可以生成 4096 * 1000 = 409w ID。
默认的雪花算法是 64 bit,具体的长度可以自行配置。如果希望运行更久,增加时间戳的位数;如果需要支持更多节点部署,增加标识位长度;如果并发很高,增加序列号位数。
总结:雪花算法并不是一成不变的,可以根据系统内具体场景进行定制。
2. 雪花算法适用场景
因为雪花算法有序自增,保障了 MySQL 中 B+ Tree 索引结构插入高性能。
所以,日常业务使用中,雪花算法更多是被应用在数据库的主键 ID 和业务关联主键。
雪花算法生成 ID 重复问题
假设:一个订单微服务,通过雪花算法生成 ID,共部署三个节点,标识位一致。
此时有 200 并发,均匀散布三个节点,三个节点同一毫秒同一序列号下生成 ID,那么就会产生重复 ID。
通过上述假设场景,可以知道雪花算法生成 ID 冲突存在一定的前提条件:
- 服务通过集群的方式部署,其中部分机器标识位一致。
- 业务存在一定的并发量,没有并发量无法触发重复问题。
- 生成 ID 的时机:同一毫秒下的序列号一致。
如果能保证标识位不重复,那么雪花 ID 也不会重复。
通过上面的案例,知道了 ID 重复的必要条件。如果要避免服务内产生重复的 ID,那么就需要从标识位上动文章。
动态分配标识符实现分布式雪花算法ID
通过将标识位存放在 Redis、Zookeeper、MySQL 等中间件,在服务启动的时候去请求标识位,请求后标识位更新为下一个可用的。
通过存放标识位,延伸出一个问题:雪花算法的 ID 是 服务内唯一还是全局唯一。
以 Redis 举例,如果要做服务内唯一,存放标识位的 Redis 节点使用自己项目内的就可以;如果是全局唯一,所有使用雪花算法的应用,要用同一个 Redis 节点。
两者的区别仅是 不同的服务间是否公用 Redis。如果没有全局唯一的需求,最好使 ID 服务内唯一,因为这样可以避免单点问题。
服务的节点数超过 1024,则需要做额外的扩展;可以扩展 10 bit 标识位,或者选择开源分布式 ID 框架。
动态分配实现方案
Redis 存储一个 Hash 结构 Key,包含两个键值对:dataCenterId 和 workerId。

在应用启动时,通过 Lua 脚本去 Redis 获取标识位。dataCenterId 和 workerId 的获取与自增在 Lua 脚本中完成,调用返回后就是可用的标示位。
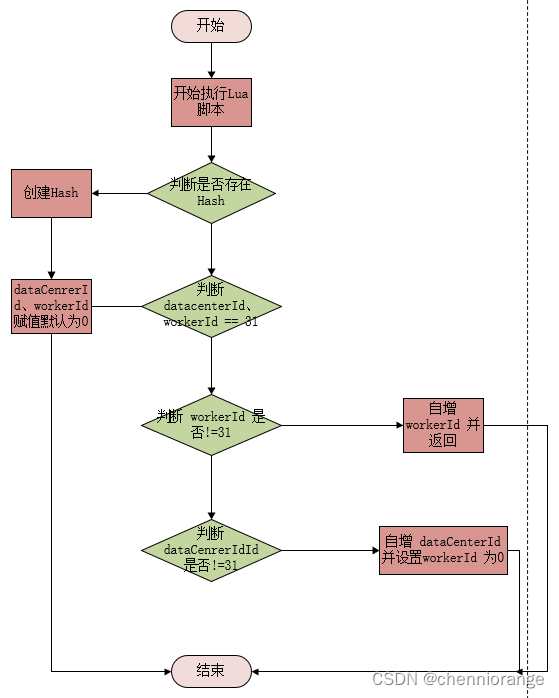
具体 Lua 脚本逻辑如下:
- 第一个服务节点在获取时,Redis 可能是没有 snowflake_work_id_key 这个 Hash 的,应该先判断 Hash 是否存在,不存在初始化 Hash,dataCenterId、workerId 初始化为 0。
- 如果 Hash 已存在,判断 dataCenterId、workerId 是否等于最大值 31,满足条件初始化 dataCenterId、workerId 设置为 0 返回。
- dataCenterId 和 workerId 的排列组合一共是 1024,在进行分配时,先分配 workerId。
- 判断 workerId 是否 != 31,条件成立对 workerId 自增,并返回;如果 workerId = 31,自增 dataCenterId 并将 workerId 设置为 0。
dataCenterId、workerId 是一直向下推进的,总体形成一个环状。通过 Lua 脚本的原子性,保证 1024 节点下的雪花算法生成不重复。如果标识位等于 1024,则从头开始继续循环推进。

示例实现:
1、雪花算法生成器
1)定义雪花算法获取机器 ID 模板抽象类。
采用模板方法模式,获取 Redis 或者随机数提供的机器 ID。
/**
* 模板抽象类,后面会有两个实现类
**/
@Slf4j
public abstract class AbstractWorkIdChooseTemplate {
/**
* 是否使用 {@link SystemClock} 获取当前时间戳
*/
@Value("${framework.distributed.id.snowflake.is-use-system-clock:false}")
private boolean isUseSystemClock;
/**
* 根据自定义策略获取 WorkId 生成器
*
* @return
*/
protected abstract WorkIdWrapper chooseWorkId();
/**
* 选择 WorkId 并初始化雪花
*/
public void chooseAndInit() {
// 模板方法模式: 通过抽象方法获取 WorkId 包装器创建雪花算法
WorkIdWrapper workIdWrapper = chooseWorkId();
// 拿到workId
long workId = workIdWrapper.getWorkId();
// 拿到dataCenterId
long dataCenterId = workIdWrapper.getDataCenterId();
Snowflake snowflake = new Snowflake(workId, dataCenterId, isUseSystemClock);
log.info("Snowflake type: {}, workId: {}, dataCenterId: {}", this.getClass().getSimpleName(), workId, dataCenterId);
SnowflakeIdUtil.initSnowflake(snowflake);
}
}下面提供了两个模板实现类来获取workId
2)通过Redis获取机器 ID 处理器。
/**
* 使用 Redis 获取雪花 WorkId
*/
@Slf4j
public class LocalRedisWorkIdChoose extends AbstractWorkIdChooseTemplate implements InitializingBean {
private RedisTemplate stringRedisTemplate;
public LocalRedisWorkIdChoose() {
this.stringRedisTemplate = ApplicationContextHolder.getBean(StringRedisTemplate.class);
}
@Override
public WorkIdWrapper chooseWorkId() {
// 执行lua脚本,准备拿取下一个标识位
DefaultRedisScript redisScript = new DefaultRedisScript();
// lua脚本源
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/chooseWorkIdLua.lua")));
List<Long> luaResultList = null;
try {
// 脚本返回值
redisScript.setResultType(List.class);
// lua脚本执行结果
luaResultList = (ArrayList) this.stringRedisTemplate.execute(redisScript, null);
} catch (Exception ex) {
log.error("Redis Lua 脚本获取 WorkId 失败", ex);
}
// lua返回值非空则正常返回一个WorkIdWrapper对象(分别为workId和dataCenterId),否则返回一个根据随机数取得的雪花算法ID
return CollUtil.isNotEmpty(luaResultList) ? new WorkIdWrapper(luaResultList.get(0), luaResultList.get(1)) : new RandomWorkIdChoose().chooseWorkId();
}
@Override
public void afterPropertiesSet() throws Exception {
chooseAndInit();
}
}通过Redis获取雪花workId这里,利用Lua脚本来保证原子性。
脚本返回的 resultWorkId, resultDataCenterId 就是雪花算法组成本分的机器 ID 标识部分。
local hashKey = 'snowflake_work_id_key'
local dataCenterIdKey = 'dataCenterId'
local workIdKey = 'workId'
-- 判断redis中是否存在hashKey,如果不存在就说明分布式雪花算法Id还没有开启的,我们就开启一下
if (redis.call('exists', hashKey) == 0) then
-- 创建hashKey
redis.call('hincrby', hashKey, dataCenterIdKey, 0)
redis.call('hincrby', hashKey, workIdKey, 0)
-- 直接退出
return { 0, 0 }
end
-- 如果hashKey存在,则取出上一次的标识位(workId + dataCenterId)
local dataCenterId = tonumber(redis.call('hget', hashKey, dataCenterIdKey))
local workId = tonumber(redis.call('hget', hashKey, workIdKey))
local max = 31
local resultWorkId = 0
local resultDataCenterId = 0
-- 判断dataCenterId、workerId 是否达到上限了
if (dataCenterId == max and workId == max) then
-- 达到上限了则赋值默认为0
redis.call('hset', hashKey, dataCenterIdKey, '0')
redis.call('hset', hashKey, workIdKey, '0')
-- 否则判断workId是否 没有 达到上限
elseif (workId ~= max) then
-- workId自增
resultWorkId = redis.call('hincrby', hashKey, workIdKey, 1)
resultDataCenterId = dataCenterId
-- 判断dataCenterId是否 没有 达到上限
elseif (dataCenterId ~= max) then
-- 自增dataCenterId并设置workerId为0
resultWorkId = 0
resultDataCenterId = redis.call('hincrby', hashKey, dataCenterIdKey, 1)
redis.call('hset', hashKey, workIdKey, '0')
end
return { resultWorkId, resultDataCenterId }
3)通过随机数获取雪花WorkId
/**
* 使用随机数获取雪花 WorkId
*/
@Slf4j
public class RandomWorkIdChoose extends AbstractWorkIdChooseTemplate implements InitializingBean {
@Override
protected WorkIdWrapper chooseWorkId() {
int start = 0, end = 31;
return new WorkIdWrapper(getRandom(start, end), getRandom(start, end));
}
@Override
public void afterPropertiesSet() throws Exception {
chooseAndInit();
}
private static long getRandom(int start, int end) {
long random = (long) (Math.random() * (end - start + 1) + start);
return random;
}
}
2、雪花算法工具类
对象属性 SNOWFLAKE 是在 AbstractWorkIdChooseTemplate 获取到机器 ID 标识位后初始化的。
/**
* 分布式雪花 ID 生成器
*/
public final class SnowflakeIdUtil {
/**
* 雪花算法对象
*/
private static Snowflake SNOWFLAKE;
/**
* 初始化雪花算法
*/
public static void initSnowflake(Snowflake snowflake) {
SnowflakeIdUtil.SNOWFLAKE = snowflake;
}
/**
* 获取雪花算法实例
*/
public static Snowflake getInstance() {
return SNOWFLAKE;
}
/**
* 获取雪花算法下一个 ID
*/
public static long nextId() {
return SNOWFLAKE.nextId();
}
/**
* 获取雪花算法下一个字符串类型 ID
*/
public static String nextIdStr() {
return Long.toString(nextId());
}
/**
* 解析雪花算法生成的 ID 为对象
*/
public static SnowflakeIdInfo parseSnowflakeId(String snowflakeId) {
return SNOWFLAKE.parseSnowflakeId(Long.parseLong(snowflakeId));
}
/**
* 解析雪花算法生成的 ID 为对象
*/
public static SnowflakeIdInfo parseSnowflakeId(long snowflakeId) {
return SNOWFLAKE.parseSnowflakeId(snowflakeId);
}
/**
* 根据 {@param serviceId} 生成雪花算法 ID
*/
public static long nextIdByService(String serviceId) {
return IdGeneratorManager.getDefaultServiceIdGenerator().nextId(Long.parseLong(serviceId));
}
/**
* 根据 {@param serviceId} 生成字符串类型雪花算法 ID
*/
public static String nextIdStrByService(String serviceId) {
return IdGeneratorManager.getDefaultServiceIdGenerator().nextIdStr(Long.parseLong(serviceId));
}
/**
* 根据 {@param serviceId} 生成字符串类型雪花算法 ID
*/
public static String nextIdStrByService(String resource, long serviceId) {
return IdGeneratorManager.getIdGenerator(resource).nextIdStr(serviceId);
}
/**
* 根据 {@param serviceId} 生成字符串类型雪花算法 ID
*/
public static String nextIdStrByService(String resource, String serviceId) {
return IdGeneratorManager.getIdGenerator(resource).nextIdStr(serviceId);
}
/**
* 解析雪花算法生成的 ID 为对象
*/
public static SnowflakeIdInfo parseSnowflakeServiceId(String snowflakeId) {
return IdGeneratorManager.getDefaultServiceIdGenerator().parseSnowflakeId(Long.parseLong(snowflakeId));
}
/**
* 解析雪花算法生成的 ID 为对象
*/
public static SnowflakeIdInfo parseSnowflakeServiceId(String resource, String snowflakeId) {
return IdGeneratorManager.getIdGenerator(resource).parseSnowflakeId(Long.parseLong(snowflakeId));
}
}














 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









