






[飞桨机器学习]梯度下降求解SVM
一、损失函数定义
我们令:
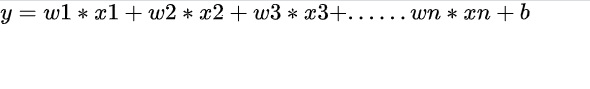
这是一个简单的线性回归的形式,此时我们来定义损失函数:
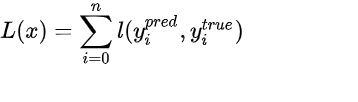
可以看到,这是一个通用的损失函数的形式,当损失函数l为二元交叉熵的时候,上面的L(x)表示的就是逻辑回归的损失函数,当损失函数l为mse的时候,上面的L(x)表示的就是线性回归的损失函数,当l为hinge loss的时候,上面的L(x)表示的就是线性svm的损失函数。
此时我们令 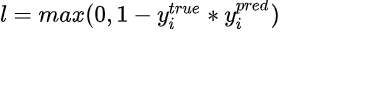
,其中 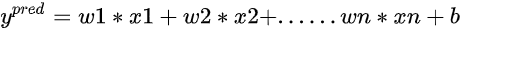
为了简单起见我们令 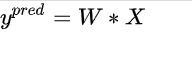
那么这个时候我们就可以得到线性svm的损失函数了:
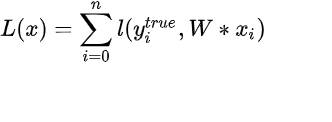
,L定义如上,这称之为硬间隔线性svm的损失函数;而加入正则项之后: 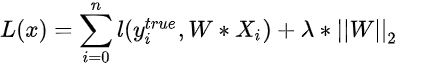
,这称之为软间隔线性svm的损失函数。进一步的我们把hinge loss的表达式带入,可得:
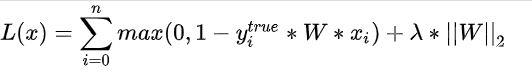
这就是线性svm的最终的损失函数,并且这也是一个是凸函数
对损失函数求梯度:
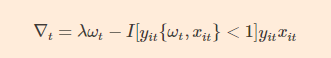
其中,I[yit{ωt,xit}<1]是指示函数,如果是真则值为1,反之为0 。
二、参数更新公式

η
t
=
1
λ
t
\eta_t = \frac 1 {\lambda t}
ηt=λt1是变动步长,和学习率λ成反比,随着迭代次数t的增加而减少。联合
∇
t
=
λ
ω
t
−
I
[
y
i
t
{
ω
t
,
x
i
t
}
<
1
]
y
i
t
x
i
t
\nabla_t = \lambda \omega_t - I[y_{it} \{\omega_t,x_{it}\}<1] y_{it}x_{it}
∇t=λωt−I[yit{ωt,xit}<1]yitxit展开迭代式得:
ω
t
+
1
<
=
ω
t
−
η
t
[
λ
ω
t
−
I
[
y
i
t
{
ω
t
,
x
i
t
}
<
1
]
y
i
t
x
i
t
]
\omega_{t+1} <= {\omega_t}-\eta_t [\lambda \omega_t - I[y_{it} \{\omega_t,x_{it}\}<1] y_{it}x_{it} ]
ωt+1<=ωt−ηt[λωt−I[yit{ωt,xit}<1]yitxit]
进一步得:
ω
t
+
1
<
=
(
1
−
1
t
)
ω
t
+
η
t
I
[
y
i
t
{
ω
t
,
x
i
t
}
<
1
]
y
i
t
x
i
t
]
\omega_{t+1 } <= {(1-\frac1 t)\omega_t}+\eta_t I[y_{it} \{\omega_t,x_{it}\}<1] y_{it}x_{it} ]
ωt+1<=(1−t1)ωt+ηtI[yit{ωt,xit}<1]yitxit]
如果指示函数为真,则:
ω
t
+
1
<
=
(
1
−
1
t
)
ω
t
+
η
t
y
i
t
x
i
t
\omega_{t+1} <= {(1-\frac1 t)\omega_t}+\eta_t y_{it}x_{it}
ωt+1<=(1−t1)ωt+ηtyitxit
如果为假,则:
ω
t
+
1
<
=
(
1
−
1
t
)
ω
t
\omega_{t+1} <= {(1-\frac1 t)\omega_t}
ωt+1<=(1−t1)ωt
三、代码实现
import csv
import numpy as np
import matplotlib.pyplot as plt
import copy
from time import sleep
import random
import types
# 0PassengerId:乘客的ID 不重要
# 1Survived:乘客是否获救,Key:0=没获救,1=已获救
# 2Pclass:乘客船舱等级(1/2/3三个等级舱位)
# 3Name:乘客姓名 不重要
# 4Sex:性别
# 5Age:年龄
# 6SibSp:乘客在船上的兄弟姐妹/配偶数量
# 7Parch:乘客在船上的父母/孩子数量
# 8Ticket:船票号 不重要
# 9Fare:船票价
# 10Cabin:客舱号码 不重要
# 11Embarked:登船的港口 不重要
# 数据分析得: 年龄中位数28,缺失值补充为28。并且以25和31为界限分为三类
# sibsp&parch按照有无分为两类
# 生还共计342人。其中全体票价和生还票价均值均约为32。
# 生还者票价高于32的126人
# 死亡共计549人。其中票价低于32的464人
# 票价低于32共计680人,死亡率0.68
# 票价低于64的共计773人,死亡512人 选择以64为分界点
def loadDataset(filename):
with open(filename, 'r') as f:
lines = csv.reader(f)
data_set = list(lines)
if filename != 'titanic.csv':
for i in range(len(data_set)):
del (data_set[i][0])
# 整理数据
for i in range(len(data_set)):
del (data_set[i][0])
del (data_set[i][2])
data_set[i][4] += data_set[i][5]
del (data_set[i][5])
del (data_set[i][5])
del (data_set[i][6])
del (data_set[i][-1])
category = data_set[0]
del (data_set[0])
# 转换数据格式
for data in data_set:
data[0] = int(data[0])
data[1] = int(data[1])
if data[3] != '':
data[3] = float(data[3])
else:
data[3] = None
data[4] = float(data[4])
data[5] = float(data[5])
# 补全缺失值 转换记录方式 分类
for data in data_set:
if data[3] is None:
data[3] = 28
# male : 1, female : 0
if data[2] == 'male':
data[2] = 1
else:
data[2] = 0
# 经过测试,如果不将数据进行以下处理,分布会过于密集,处理后,数据的分布变得稀疏了
# age <25 为0, 25<=age<31为1,age>=31为2
if data[3] < 25:
data[3] = 0
elif data[3] >= 21 and data[3] < 60: # 但是测试得60分界准确率最高???!!!
data[3] = 1
else:
data[3] = 2
# sibsp&parcg以2为界限,小于为0,大于为1
if data[4] < 2:
data[4] = 0
else:
data[4] = 1
# fare以64为界限
if data[-1] < 64:
data[-1] = 0
else:
data[-1] = 1
return data_set, category
def split_data(data):
data_set = copy.deepcopy(data)
data_mat = []
label_mat = []
for i in range(len(data_set)):
if data_set[i][0] == 0:
data_set[i][0] = -1
label_mat.append(data_set[i][0])
del (data_set[i][0])
data_mat.append(data_set[i])
print(data_mat)
print(label_mat)
return data_mat, label_mat
def smo(data_mat_In, class_label, learning_rate, max_iter):
# 转化为numpy的mat存储
data_matrix = np.mat(data_mat_In)
data_x = np.concatenate((np.ones((data_matrix.shape[0], 1)), data_matrix), axis=1)
label_mat = np.mat(class_label).transpose()
# data_matrix = data_mat_In
# label_mat = class_label
m, n = np.shape(data_x)
# 初始化alpha,设为0
alphas = np.zeros((n, 1))
alphas_sum = [alphas]
# 初始化迭代次数
iter_num = 1
alpha_pairs_changed = 0
# 最多迭代max_iter次
while iter_num <= max_iter:
for i in range(m):
# 计算预测值
y = float(np.dot(data_x[i], alphas))
if 1-label_mat[i]*y >= 0:
alphas = (1.0 - 1.0 / iter_num) * alphas + learning_rate * (label_mat[i] * data_x[i]).T
else:
alphas = (1.0 - 1.0 / iter_num) * alphas
alphas_sum.append(alphas)
# 统计优化次数
alpha_pairs_changed += 1
# 打印统计信息
print("第%d次迭代 样本:%d , alpha优化次数:%d" % (iter_num, i, alpha_pairs_changed))
if abs(np.sum(alphas_sum[-1] - alphas_sum[-2])) < 1e-6:
break
iter_num += 1
return alphas
def prediction(test, w):
test = np.mat(test)
x = np.concatenate((np.ones((test.shape[0], 1)), test), axis=1)
result = []
for i in x:
if np.dot(i, alphas) > 0:
result.append(1)
else:
result.append(-1)
print(result)
return result
if __name__ == "__main__":
test_set, category = loadDataset('titanic_test.csv')
data_set, category = loadDataset('titanic_train.csv')
test_mat, test_label = split_data(test_set)
data_mat, label_mat = split_data(data_set)
alphas = smo(data_mat, list(label_mat), 0.01, 1000)
print(alphas)
result = prediction(test_mat, alphas)
count = 0
for i in range(len(result)):
if result[i] == test_label[i]:
count += 1
print(count)
print(count / len(result))
最终结果准确率为:75.7%
运行代码请点击:https://aistudio.baidu.com/aistudio/projectdetail/630151?shared=1















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









