







 本文深入讲解Kafka中的分区和副本机制,包括生产者写入策略、消费者组再均衡机制及分区分配策略等内容,并对比了高级API与低级API的区别。
本文深入讲解Kafka中的分区和副本机制,包括生产者写入策略、消费者组再均衡机制及分区分配策略等内容,并对比了高级API与低级API的区别。
Apache Kafka系列文章
1、kafka(2.12-3.0.0)介绍、部署及验证、基准测试
2、java调用kafka api
3、kafka重要概念介紹及示例
4、kafka分区、副本介绍及示例
5、kafka监控工具Kafka-Eagle介绍及使用
文章目录
本文主要介绍分区与副本机制、高级api使用示例手动消费分区数据等。
本文前提是kafka环境可用。
本文分为2个部分,即分区与副本机制、高级API与低级API。
一、分区和副本
1、生产者分区写入策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中
1、轮询分区策略
2、随机分区策略
3、按key分区分配策略
4、自定义分区策略
1)、轮询策略
默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
2)、随机策略
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。但后续轮询策略表现更佳,所以基本上很少会使用随机策略。
3)、按key分配策略
按key分配策略,有可能会出现「数据倾斜」,例如:某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区。
4)、乱序问题
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
5)、自定义分区策略
下例是实现自定义分区的代码
import java.util.Map;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.Cluster;
/**
* @author alanchan
*
*/
public class KeyWithRandomPartitioner implements Partitioner {
private Random r;
public final static String TOPIC_NAME = "test_partition";
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "server1:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//设置kafka分区规则
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, KeyWithRandomPartitioner.class.getName());
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-10消息到指定Topic test_partition
for (int i = 0; i < 10; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>(TOPIC_NAME, null, i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 5. 关闭生产者
producer.close();
}
@Override
public void configure(Map<String, ?> configs) {
r = new Random();
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// cluster.partitionCountForTopic 表示获取指定topic的分区数量
return r.nextInt(1000) % cluster.partitionCountForTopic(topic);
}
@Override
public void close() {
}
}
验证
1、创建topic
kafka-topics.sh --create --bootstrap-server server1:9092 --topic test_partition --partitions 3 --replication-factor 1
2、运行生产者程序,生成消息
3、通过客户端查看各个分区的数据记录数
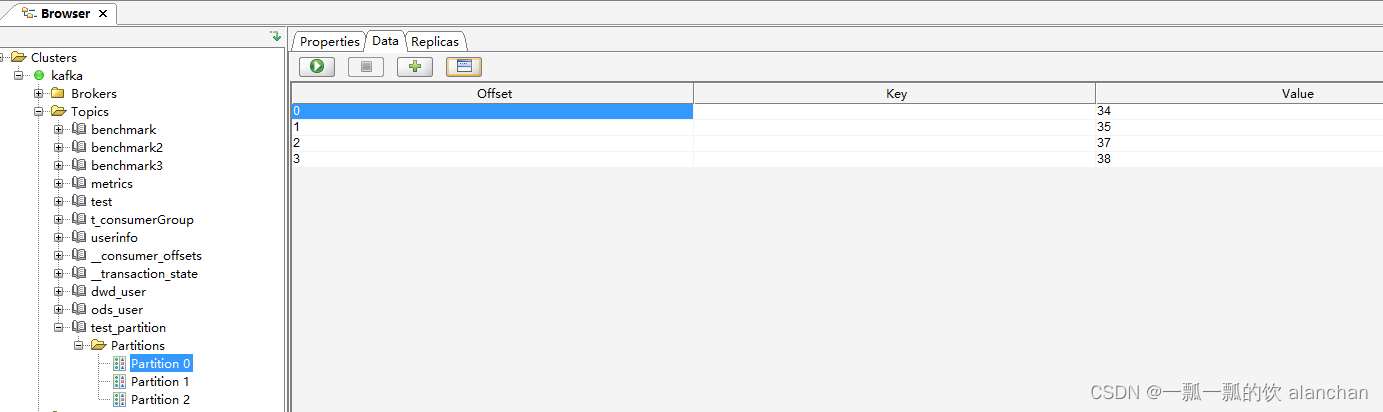
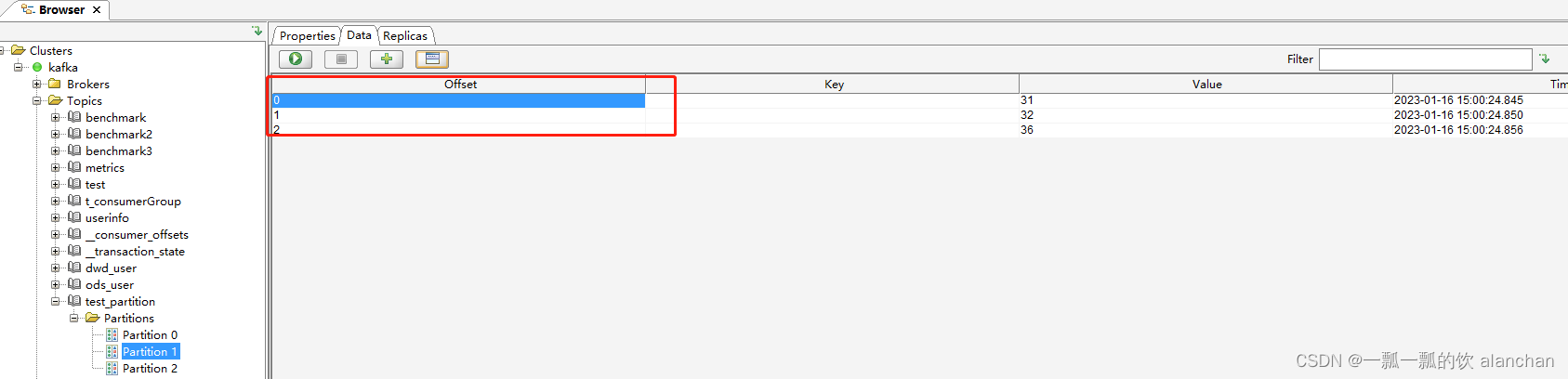
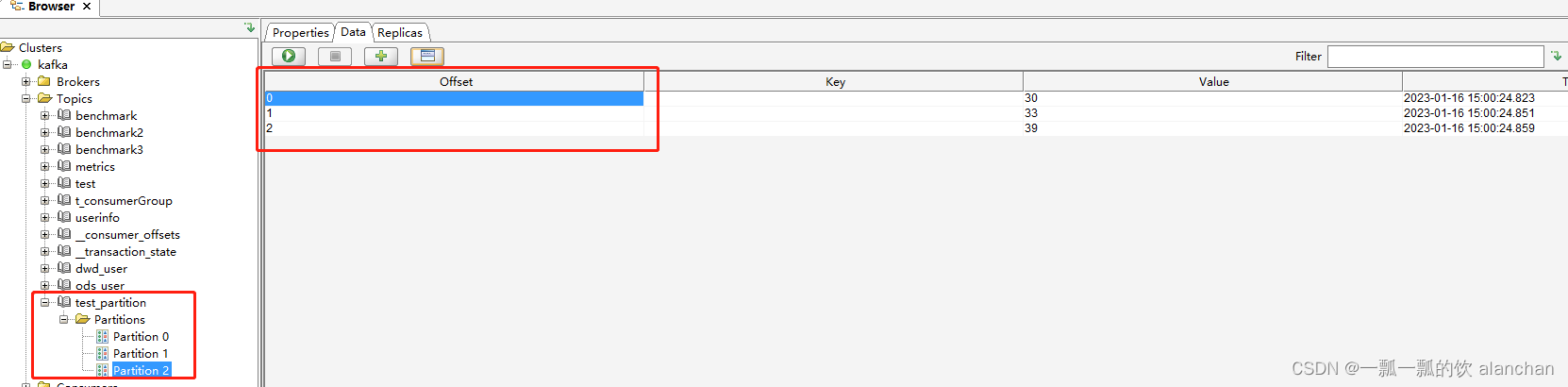
2、消费者组Rebalance机制
1)、Rebalance再均衡
Kafka中的Rebalance称之为再均衡,是Kafka中确保Consumer group下所有的consumer如何达成一致,分配订阅的topic的每个分区的机制。
Rebalance触发的时机有:
-
消费者组中consumer的个数发生变化
例如:有新的consumer加入到消费者组,或者是某个consumer停止了。 -
订阅的topic个数发生变化
消费者可以订阅多个主题,假设当前的消费者组订阅了三个主题,但有一个主题突然被删除了,此时也需要发生再均衡。 -
订阅的topic分区数发生变化
2)、Rebalance的不良影响
发生Rebalance时,consumer group下的所有consumer都会协调在一起共同参与,Kafka使用分配策略尽可能达到最公平的分配
Rebalance过程会对consumer group产生非常严重的影响,Rebalance的过程中所有的消费者都将停止工作,直到Rebalance完成
3、消费者分区分配策略
1)、Range范围分配策略
Range范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。
Rangle范围分配策略是针对每个Topic的。
- 配置
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RangeAssignor。 - 算法公式
n = 分区数量 / 消费者数量
m = 分区数量 % 消费者数量
前m个消费者消费n+1个
剩余消费者消费n个
2)、RoundRobin轮询策略
RoundRobinAssignor轮询策略是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者。
- 配置
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RoundRobinAssignor
3)、Stricky粘性分配策略
从Kafka 0.11.x开始,引入此类分配策略。主要目的:
- 分区分配尽可能均匀
- 在发生rebalance的时候,分区的分配尽可能与上一次分配保持相同
没有发生rebalance时,Striky粘性分配策略和RoundRobin分配策略类似。
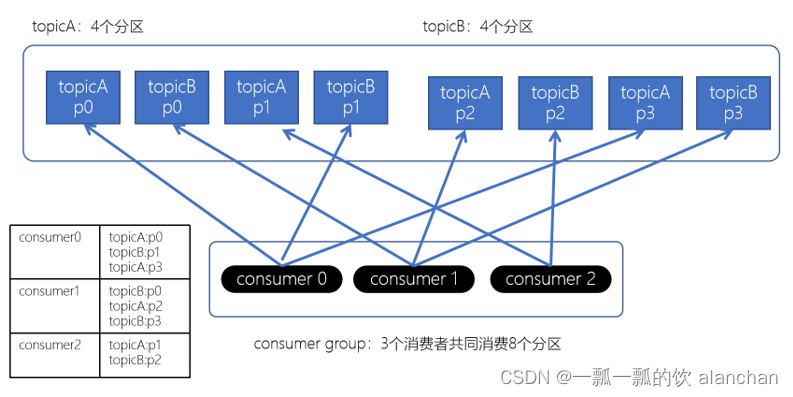
上面如果consumer2崩溃了,此时需要进行rebalance。如果是Range分配和轮询分配都会重新进行分配,例如:
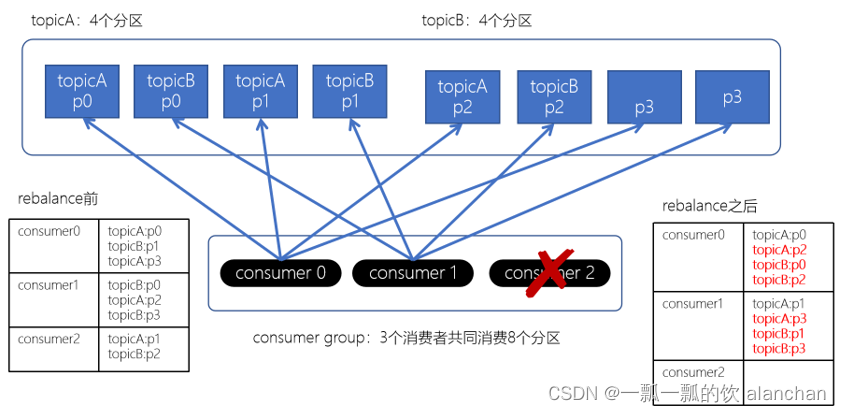
通过上图,我们发现,consumer0和consumer1原来消费的分区大多发生了改变。接下来我们再来看下粘性分配策略。
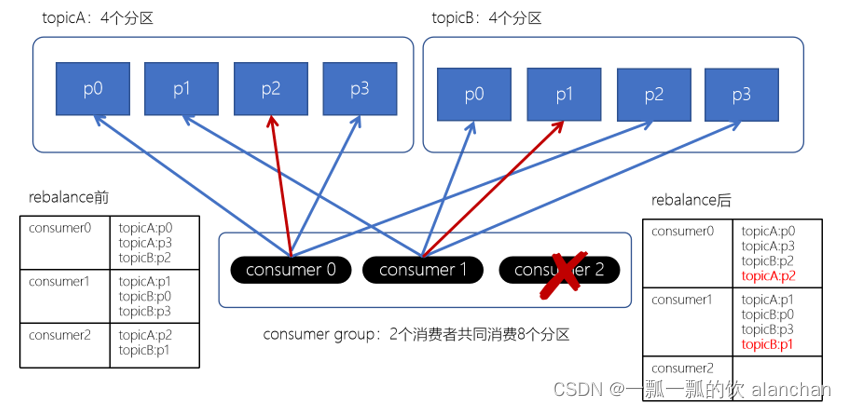
Striky粘性分配策略,保留rebalance之前的分配结果。只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。这样可以明显减少系统资源的浪费,例如:之前consumer0、consumer1之前正在消费某几个分区,但由于rebalance发生,导致consumer0、consumer1需要重新消费之前正在处理的分区,导致不必要的系统开销。(例如:某个事务正在进行就必须要取消了)
4、副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的。
1)、producer的ACKs参数
对副本关系较大的就是producer配置的acks参数了,acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
- 配置
Properties props = new Properties();
props.put("acks", "all");
- acks配置为0
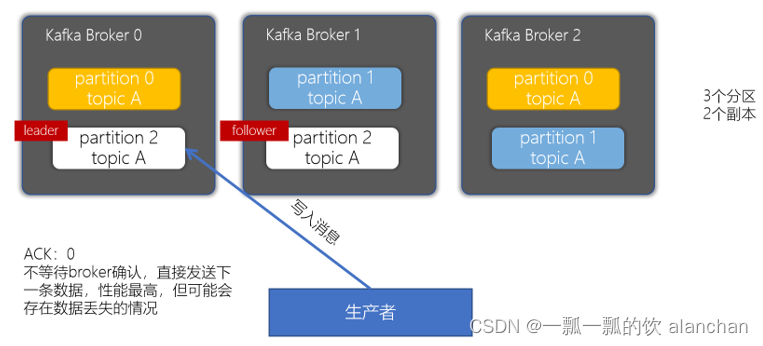
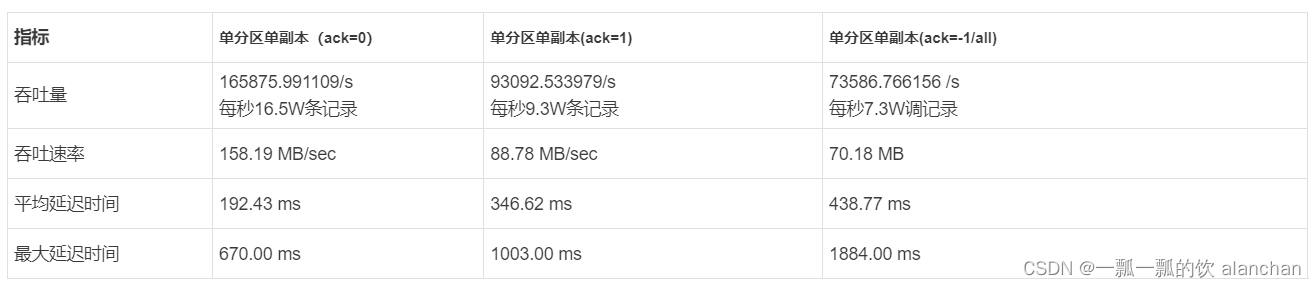
ACK为0,基准测试
kafka-producer-perf-test.sh
--topic benchmark
--num-records 5000000
--throughput -1
--record-size 1000
--producer-props
bootstrap.servers=serv1:9092,serv2:9092,serv3:9092
acks=0
测试结果
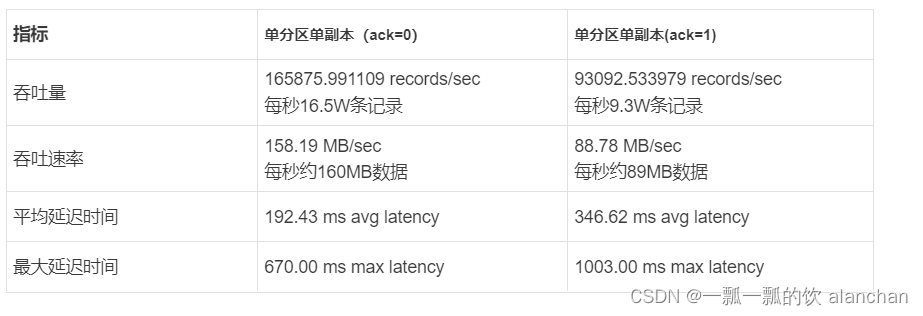
- acks配置为1
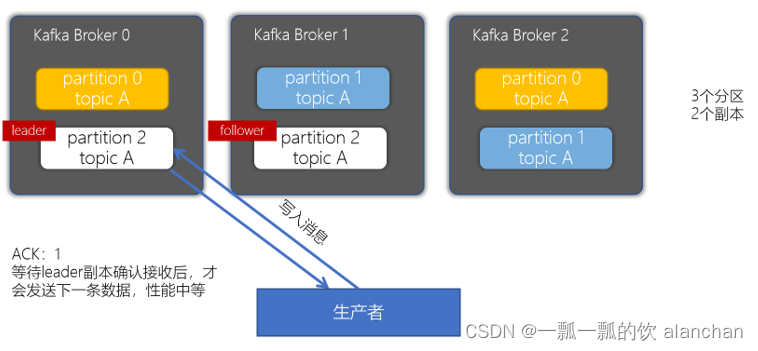
当生产者的ACK配置为1时,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
- acks配置为-1或者all
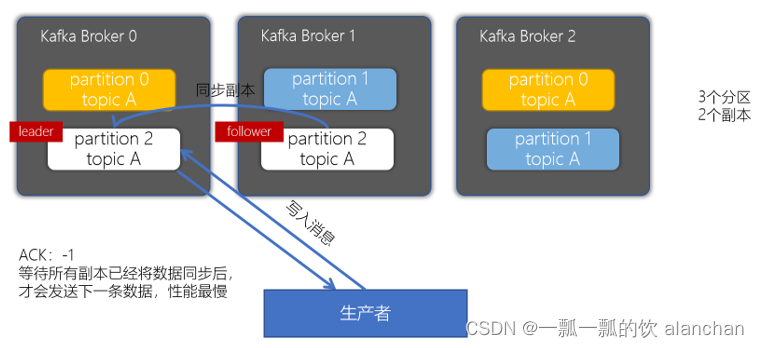
kafka-producer-perf-test.sh
--topic benchmark
--num-records 5000000
--throughput -1
--record-size 1000
--producer-props
bootstrap.servers=serv1:9092,serv2:9092,serv3:9092
acks=all
二、高级(High Level)API与低级(Low Level)API
1、高级API
/**
* 消费者程序:从test主题中消费数据
*/
public class _2ConsumerTest {
public static void main(String[] args) {
// 1. 创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "serv1:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2. 创建Kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
consumer.subscribe(Arrays.asList("test"));
// 4. 使用一个while循环,不断从Kafka的topic中拉取消息
while (true) {
// 定义100毫秒超时
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
- 上面是之前编写的代码,消费Kafka的消息很容易实现,写起来比较简单
- 不需要执行去管理offset,直接通过ZK管理;也不需要管理分区、副本,由Kafka统一管理
- 消费者会自动根据上一次在ZK中保存的offset去接着获取数据
- 在ZK中,不同的消费者组(group)同一个topic记录不同的offset,这样不同程序读取同一个topic,不会受offset的影响
- 高级API的缺点
不能控制offset,例如:想从指定的位置读取
不能细化控制分区、副本、ZK等
2、低级API
通过使用低级API,我们可以自己来控制offset,想从哪儿读,就可以从哪儿读。而且,可以自己控制连接分区,对分区自定义负载均衡。而且,之前offset是自动保存在ZK中,使用低级API,我们可以将offset不一定要使用ZK存储,我们可以自己来存储offset。例如:存储在文件、MySQL、或者内存中。但是低级API,比较复杂,需要执行控制offset,连接到哪个分区,并找到分区的leader。
3、手动消费分区数据
Kafka根据消费组中的消费者动态地为topic分配要消费的分区。有时需要指定要消费的分区,例如:
- 如果某个程序将某个指定分区的数据保存到外部存储中,例如:Redis、MySQL,那么保存数据的时候,只需要消费该指定的分区数据即可
- 如果某个程序是高可用的,在程序出现故障时将自动重启(例如:Flink、Spark程序)。这种情况下,程序将从指定的分区重新开始消费数据。
手动消费分区中的数据不再使用之前的 subscribe 方法订阅主题,而使用assign方法指定想要消费的数据
String topic = "test";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
一旦指定了分区,就可以就像前面的示例一样,在循环中调用「poll」方法消费消息
说明
1、当手动管理消费分区时,即使GroupID是一样的,Kafka的组协调器都将不再起作用
2、如果消费者失败,也将不再自动进行分区重新分配



















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











