







cloudera impala 系列文章
1、cloudera impala的介绍、与hive的异同、两种部署方式以及内外部命令
2、cloudera impala sql语法与示例、impala的数据导入的4种方式、java api操作impala和综合示例比较hive与impala的查询速度
本文简单的介绍了impala的sql语法与使用示例,也介绍了impala导入数据的几种方式、java api操作impala,最后用一个综合示例简单的对比了impala和hive的查询速度。
本文依赖impala、sqoop、hive、hadoop环境好用。
本文分为4个部分,即impala的简单sql语法与示例、impala数据插入的四种方式、通过java api访问impapa和一个综合示例。
一、Impala sql语法
- 如果在hive窗口中插入数据或者新建的数据库或者数据库表,那么在impala当中是不可直接查询,需要执行invalidate metadata以通知元数据的更新
- 在impala-shell当中插入的数据,在impala当中是可以直接查询到的,不需要刷新数据库,其中使用的就是catalog这个服务的功能实现的,catalog是impala1.2版本之后增加的模块功能,主要作用就是同步impala之间的元数据
- 更新操作通知Catalog,Catalog通过广播的方式通知其它的Impalad进程。默认情况下Catalog是异步加载元数据的,因此查询可能需要等待元数据加载完成之后才能进行(第一次加载)
本文的示例是在cdh环境安装的impala,所以机器名称与上文中的机器名不同,但不影响使用与验证。
1、数据库操作示例
1)、创建数据库
CREATE DATABASE 语句用于在Impala中创建新数据库。
CREATE DATABASE IF NOT EXISTS database_name;
这里,IF NOT EXISTS是一个可选的子句。如果我们使用此子句,则只有在没有具有相同名称的现有数据库时,才会创建具有给定名称的数据库。
impala默认使用impala用户执行操作,会报权限不足问题,解决办法:
- 1、给HDFS指定文件夹授予权限
hadoop fs -chmod -R 777 hdfs://server-1:9000/user/hive
- 2、haoop 配置文件中hdfs-site.xml 中设置权限为false

上述两种方式都可以。
默认就会在hive的数仓路径下创建新的数据库名文件夹
/user/hive/warehouse/ittest.db
也可以在创建数据库的时候指定hdfs路径。需要注意该路径的权限。
hadoop fs -mkdir -p /input/impala
hadoop fs -chmod -R 777 /input/impala
create external table t3(id int ,name string ,age int )
row format delimited fields terminated by '\t'
location '/input/impala/external';
[server7:21000] test> show databases;
Query: show databases
+-----------------------------------------------------------------------------------------------+-------------------------------------------------+
| name | comment |
+-----------------------------------------------------------------------------------------------+-------------------------------------------------+
| _impala_builtins | System database for Impala builtin functions |
| cloudera_manager_metastore_canary_test_db_hive_hivemetastore_9d6beb1369433f8a2d12dd14fd802ce8 | Cloudera Manager Metastore Canary Test Database |
| default | Default Hive database |
| test | |
+-----------------------------------------------------------------------------------------------+-------------------------------------------------+
Fetched 4 row(s) in 0.04s
2)、删除数据库
Impala的DROP DATABASE语句用于从Impala中删除数据库。 在删除数据库之前,建议从中删除所有表。
如果使用级联删除,Impala会在删除指定数据库中的表之前删除它。
DROP database sample cascade;
2、表特定语句
1)、create table语句
CREATE TABLE语句用于在Impala中的所需数据库中创建新表。
需要指定表名字并定义其列和每列的数据类型。
impala支持的数据类型和hive类似,除了sql类型外,还支持java类型。
create table IF NOT EXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
);
CREATE TABLE IF NOT EXISTS my_db.student(name STRING, age INT, contact INT );
默认建表的数据存储路径跟hive一致。也可以在建表的时候通过location指定具体路径,需要注意hdfs权限问题。
2)、insert语句
Impala的INSERT语句有两个子句:into和overwrite。
into用于插入新记录数据,overwrite用于覆盖已有的记录。
insert into table_name (column1, column2, column3,...columnN)
values (value1, value2, value3,...valueN);
Insert into table_name values (value1, value2, value2);
这里,column1,column2,… columnN是要插入数据的表中的列的名称。还可以添加值而不指定列名,但是,需要确保值的顺序与表中的列的顺序相同。
示例:
create table employee (Id INT, name STRING, age INT,address STRING, salary BIGINT);
insert into employee VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 );
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
Insert into employee values (6, 'Komal', 22, 'MP', 32000 );
[server7:21000] test> select * from employee;
Query: select * from employee
Query submitted at: 2022-11-08 13:23:18 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=f84adae242c9f6af:a43bb90900000000
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 2 | Khilan | 25 | Delhi | 15000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.85s
overwrite覆盖子句覆盖表当中全部记录。 覆盖的记录将从表中永久删除。
Insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 );
[server7:21000] test> Insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 );
Query: Insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 )
Query submitted at: 2022-11-08 13:24:04 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=f44bb549f202b8ed:7c0a193800000000
Modified 1 row(s) in 0.24s
[server7:21000] test> select * from employee;
Query: select * from employee
Query submitted at: 2022-11-08 13:25:08 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=7c423d231e0a32a9:f9650b7600000000
+----+------+-----+----------------+--------+
| id | name | age | address | salary |
+----+------+-----+----------------+--------+
| 1 | Ram | 26 | Vishakhapatnam | 37000 |
+----+------+-----+----------------+--------+
3)、select语句
Impala SELECT语句用于从数据库中的一个或多个表中提取数据。 此查询以表的形式返回数据。
create table employee (Id INT, name STRING, age INT,address STRING, salary BIGINT);
insert into employee VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 );
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
Insert into employee values (6, 'Komal', 22, 'MP', 32000 );
create table emp_add(Id INT,address STRING);
insert into emp_add VALUES (1, 'shanghai');
insert into emp_add values (2, 'beijing');
Insert into emp_add values (3, 'new york');
--------------impala 查询 0.96s
[server7:21000] test> select e.*,a.address from employee e join emp_add a on e.Id = a.Id;
Query: select e.*,a.address from employee e join emp_add a on e.Id = a.Id
Query submitted at: 2022-11-08 13:35:31 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=9448e84ede2fd9d6:e4e1fc5b00000000
+----+---------+-----+-----------+--------+----------+
| id | name | age | address | salary | address |
+----+---------+-----+-----------+--------+----------+
| 3 | kaushik | 23 | Kota | 30000 | new york |
| 2 | Khilan | 25 | Delhi | 15000 | beijing |
| 1 | Ramesh | 32 | Ahmedabad | 20000 | shanghai |
+----+---------+-----+-----------+--------+----------+
Fetched 3 row(s) in 0.96s
---------------------hive 查询 32.5秒
0: jdbc:hive2://server8:10000> select e.*,a.address from employee e join emp_add a on e.Id = a.Id;
INFO : Compiling command(queryId=hive_20221108133409_d068b90e-76c7-48ea-8776-7739d5a60ae7): select e.*,a.address from employee e join emp_add a on e.Id = a.Id
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:e.id, type:int, comment:null), FieldSchema(name:e.name, type:string, comment:null), FieldSchema(name:e.age, type:int, comment:null), FieldSchema(name:e.address, type:string, comment:null), FieldSchema(name:e.salary, type:bigint, comment:null), FieldSchema(name:a.address, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20221108133409_d068b90e-76c7-48ea-8776-7739d5a60ae7); Time taken: 0.228 seconds
INFO : Executing command(queryId=hive_20221108133409_d068b90e-76c7-48ea-8776-7739d5a60ae7): select e.*,a.address from employee e join emp_add a on e.Id = a.Id
WARN :
INFO : Query ID = hive_20221108133409_d068b90e-76c7-48ea-8776-7739d5a60ae7
INFO : Total jobs = 1
INFO : Starting task [Stage-4:MAPREDLOCAL] in serial mode
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-3:MAPRED] in serial mode
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1667806921128_0006
INFO : Executing with tokens: []
INFO : The url to track the job: http://server8:8088/proxy/application_1667806921128_0006/
INFO : Starting Job = job_1667806921128_0006, Tracking URL = http://server8:8088/proxy/application_1667806921128_0006/
INFO : Kill Command = /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop/bin/hadoop job -kill job_1667806921128_0006
INFO : Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
INFO : 2022-11-08 13:34:31,437 Stage-3 map = 0%, reduce = 0%
INFO : 2022-11-08 13:34:38,800 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 3.56 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 560 msec
INFO : Ended Job = job_1667806921128_0006
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-3: Map: 1 Cumulative CPU: 3.56 sec HDFS Read: 7354 HDFS Write: 225 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 3 seconds 560 msec
INFO : Completed executing command(queryId=hive_20221108133409_d068b90e-76c7-48ea-8776-7739d5a60ae7); Time taken: 31.918 seconds
INFO : OK
+-------+----------+--------+------------+-----------+------------+
| e.id | e.name | e.age | e.address | e.salary | a.address |
+-------+----------+--------+------------+-----------+------------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 | shanghai |
| 3 | kaushik | 23 | Kota | 30000 | new york |
| 2 | Khilan | 25 | Delhi | 15000 | beijing |
+-------+----------+--------+------------+-----------+------------+
3 rows selected (32.497 seconds)
--------------------hue hive查询 29.4秒
INFO : Compiling command(queryId=hive_20221108133429_a446dfa0-5801-447a-bdfc-cc775c76d014): select e.*,a.address from employee e join emp_add a on e.Id = a.Id
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:e.id, type:int, comment:null), FieldSchema(name:e.name, type:string, comment:null), FieldSchema(name:e.age, type:int, comment:null), FieldSchema(name:e.address, type:string, comment:null), FieldSchema(name:e.salary, type:bigint, comment:null), FieldSchema(name:a.address, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20221108133429_a446dfa0-5801-447a-bdfc-cc775c76d014); Time taken: 0.097 seconds
INFO : Executing command(queryId=hive_20221108133429_a446dfa0-5801-447a-bdfc-cc775c76d014): select e.*,a.address from employee e join emp_add a on e.Id = a.Id
WARN :
INFO : Query ID = hive_20221108133429_a446dfa0-5801-447a-bdfc-cc775c76d014
INFO : Total jobs = 1
INFO : Starting task [Stage-4:MAPREDLOCAL] in serial mode
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-3:MAPRED] in serial mode
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1667806921128_0007
INFO : Executing with tokens: []
INFO : The url to track the job: http://server8:8088/proxy/application_1667806921128_0007/
INFO : Starting Job = job_1667806921128_0007, Tracking URL = http://server8:8088/proxy/application_1667806921128_0007/
INFO : Kill Command = /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop/bin/hadoop job -kill job_1667806921128_0007
INFO : Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
INFO : 2022-11-08 13:34:49,739 Stage-3 map = 0%, reduce = 0%
INFO : 2022-11-08 13:34:57,962 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 3.32 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 320 msec
INFO : Ended Job = job_1667806921128_0007
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-3: Map: 1 Cumulative CPU: 3.32 sec HDFS Read: 7403 HDFS Write: 225 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 3 seconds 320 msec
INFO : Completed executing command(queryId=hive_20221108133429_a446dfa0-5801-447a-bdfc-cc775c76d014); Time taken: 29.409 seconds
INFO : OK
4)、describe语句
Impala中的describe语句用于提供表的描述。 此语句的结果包含有关表的信息,例如列名称及其数据类型。
Describe table_name;
Describe employee;
[server7:21000] test> Describe employee;
Query: describe employee
+---------+--------+---------+
| name | type | comment |
+---------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
+---------+--------+---------+
Fetched 5 row(s) in 0.06s
# 此外,还可以使用hive的查询表元数据信息语句。
desc formatted table_name;
Describe formatted employee;
[server7:21000] test> Describe formatted employee;
Query: describe formatted employee
+------------------------------+------------------------------------------------------------+----------------------+
| name | type | comment |
+------------------------------+------------------------------------------------------------+----------------------+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | NULL |
| name | string | NULL |
| age | int | NULL |
| address | string | NULL |
| salary | bigint | NULL |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | test | NULL |
| OwnerType: | USER | NULL |
| Owner: | root | NULL |
| CreateTime: | Tue Nov 08 13:29:56 CST 2022 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://hadoopha/user/hive/warehouse/test.db/employee | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | transient_lastDdlTime | 1667885396 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | 0 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
+------------------------------+------------------------------------------------------------+----------------------+
Fetched 28 row(s) in 0.06s
5)、alter table
Impala中的Alter table语句用于对给定表执行更改。使用此语句,可以添加,删除或修改现有表中的列,也可以重命名它们。
-- 表重命名:
ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_name
-- 向表中添加列:
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
-- 从表中删除列:
ALTER TABLE name DROP [COLUMN] column_name
-- 更改列的名称和类型:
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE employee RENAME TO user;
[server7:21000] test> ALTER TABLE employee RENAME TO user;
Query: ALTER TABLE employee RENAME TO user
+--------------------------+
| summary |
+--------------------------+
| Renaming was successful. |
+--------------------------+
Fetched 1 row(s) in 0.15s
ALTER TABLE user ADD COLUMNS (address2 string )
[server7:21000] test> ALTER TABLE user ADD COLUMNS (address2 string );
Query: ALTER TABLE user ADD COLUMNS (address2 string )
+---------------------------------------------+
| summary |
+---------------------------------------------+
| New column(s) have been added to the table. |
+---------------------------------------------+
Fetched 1 row(s) in 0.12s
[server7:21000] test> select * from user ;
Query: select * from user
Query submitted at: 2022-11-08 13:53:46 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=b14301e64d05ad0e:50ab69200000000
+----+----------+-----+-----------+--------+----------+
| id | name | age | address | salary | address2 |
+----+----------+-----+-----------+--------+----------+
| 5 | Hardik | 27 | Bhopal | 40000 | NULL |
| 6 | Komal | 22 | MP | 32000 | NULL |
| 1 | Ramesh | 32 | Ahmedabad | 20000 | NULL |
| 2 | Khilan | 25 | Delhi | 15000 | NULL |
| 3 | kaushik | 23 | Kota | 30000 | NULL |
| 4 | Chaitali | 25 | Mumbai | 35000 | NULL |
+----+----------+-----+-----------+--------+----------+
Fetched 6 row(s) in 0.41s
ALTER TABLE user DROP address2;
[server7:21000] test> ALTER TABLE user DROP address2;
Query: ALTER TABLE user DROP address2
+--------------------------+
| summary |
+--------------------------+
| Column has been dropped. |
+--------------------------+
Fetched 1 row(s) in 0.12s
[server7:21000] test> select * from user ;
Query: select * from user
Query submitted at: 2022-11-08 13:58:24 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=304a7cca4fc50e6f:e48d13e500000000
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.21s
ALTER TABLE user CHANGE salary salary double;
[server7:21000] test> ALTER TABLE user CHANGE salary salary double;
Query: ALTER TABLE user CHANGE salary salary double
+--------------------------+
| summary |
+--------------------------+
| Column has been altered. |
+--------------------------+
Fetched 1 row(s) in 0.11s
[server7:21000] test> select * from user order by id ;
Query: select * from user order by id
Query submitted at: 2022-11-08 14:00:04 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=d9495c09b7e64452:66710b7d00000000
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.53s
6)、delete、truncate table
Impala drop table语句用于删除Impala中的现有表。此语句还会删除内部表的底层HDFS文件。
注意:使用此命令时必须小心,因为删除表后,表中可用的所有信息也将永远丢失。
DROP table database_name.table_name;
Impala的Truncate Table语句用于从现有表中删除所有记录。保留表结构。
也可以使用DROP TABLE命令删除一个完整的表,但它会从数据库中删除完整的表结构,如果希望存储一些数据,将需要重新创建此表。
truncate table_name;
7)、view视图
视图仅仅是存储在数据库中具有关联名称的Impala查询语言的语句。 它是以预定义的SQL查询形式的表的组合。
视图可以包含表的所有行或选定的行。
Create View IF NOT EXISTS view_name as Select statement
Create View IF NOT EXISTS user_salary as Select id,name salary from user;
[server7:21000] test> Create View IF NOT EXISTS user_salary as Select id,name salary from user;
Query: Create View IF NOT EXISTS user_salary as Select id,name salary from user
+------------------------+
| summary |
+------------------------+
| View has been created. |
+------------------------+
Fetched 1 row(s) in 0.06s
[server7:21000] test> select * from user_salary;
Query: select * from user_salary
Query submitted at: 2022-11-08 14:03:08 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=ad41be5d26690069:5aa01eb200000000
+----+----------+
| id | salary |
+----+----------+
| 6 | Komal |
| 5 | Hardik |
| 4 | Chaitali |
| 3 | kaushik |
| 2 | Khilan |
| 1 | Ramesh |
+----+----------+
Fetched 6 row(s) in 5.39s
[server7:21000] test> select * from user_salary;
Query: select * from user_salary
Query submitted at: 2022-11-08 14:03:16 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=694fabc4e8331823:5dc2d71100000000
+----+----------+
| id | salary |
+----+----------+
| 5 | Hardik |
| 6 | Komal |
| 3 | kaushik |
| 4 | Chaitali |
| 2 | Khilan |
| 1 | Ramesh |
+----+----------+
Fetched 6 row(s) in 0.23s
-- 修改视图
ALTER VIEW database_name.view_name as select 子句
ALTER VIEW user_salary as select id ,name ,salary from user order by id ;
[server7:21000] test> ALTER VIEW user_salary as select id ,name ,salary from user order by id ;
Query: ALTER VIEW user_salary as select id ,name ,salary from user order by id
+------------------------+
| summary |
+------------------------+
| View has been altered. |
+------------------------+
Fetched 1 row(s) in 0.08s
[server7:21000] test> select * from user_salary;
Query: select * from user_salary
Query submitted at: 2022-11-08 14:05:58 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=7245cdd5ba036b69:fe228af00000000
+----+----------+--------+
| id | name | salary |
+----+----------+--------+
| 6 | Komal | 32000 |
| 5 | Hardik | 40000 |
| 3 | kaushik | 30000 |
| 4 | Chaitali | 35000 |
| 2 | Khilan | 15000 |
| 1 | Ramesh | 20000 |
+----+----------+--------+
WARNINGS: Ignoring ORDER BY clause without LIMIT or OFFSET: ORDER BY id ASC.
An ORDER BY appearing in a view, subquery, union operand, or an insert/ctas statement has no effect on the query result unless a LIMIT and/or OFFSET is used in conjunction with the ORDER BY.
Fetched 6 row(s) in 0.34s
[server7:21000] test> select * from user_salary limit 10 ;
Query: select * from user_salary limit 10
Query submitted at: 2022-11-08 14:07:02 (Coordinator: http://server7:25000)
Query progress can be monitored at: http://server7:25000/query_plan?query_id=a445fd6d6329af5b:361cbd7100000000
+----+----------+--------+
| id | name | salary |
+----+----------+--------+
| 1 | Ramesh | 20000 |
| 5 | Hardik | 40000 |
| 4 | Chaitali | 35000 |
| 6 | Komal | 32000 |
| 3 | kaushik | 30000 |
| 2 | Khilan | 15000 |
+----+----------+--------+
WARNINGS: Ignoring ORDER BY clause without LIMIT or OFFSET: ORDER BY id ASC.
An ORDER BY appearing in a view, subquery, union operand, or an insert/ctas statement has no effect on the query result unless a LIMIT and/or OFFSET is used in conjunction with the ORDER BY.
Fetched 6 row(s) in 0.14s
-- 删除视图
DROP VIEW database_name.view_name;
drop view user_salary;
[server7:21000] test> drop view user_salary;
Query: drop view user_salary
+------------------------+
| summary |
+------------------------+
| View has been dropped. |
+------------------------+
Fetched 1 row(s) in 0.06s
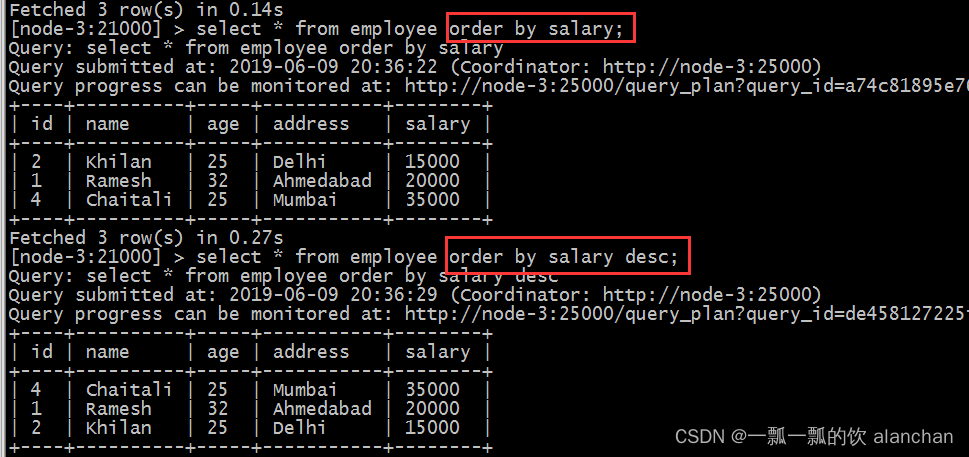
8)、order by子句
Impala ORDER BY子句用于根据一个或多个列以升序或降序对数据进行排序。
默认情况下,一些数据库按升序对查询结果进行排序。
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
可以使用关键字ASC或DESC分别按升序或降序排列表中的数据。
如果使用NULLS FIRST,表中的所有空值都排列在顶行;如果使用NULLS LAST,包含空值的行将最后排列。
9)、group by子句
Impala GROUP BY子句与SELECT语句协作使用,以将相同的数据排列到组中。
select data from table_name Group BY col_name;
10)、having子句
Impala中的Having子句允许您指定过滤哪些组结果显示在最终结果中的条件。
一般来说,Having子句与group by子句一起使用,它将条件放置在由GROUP BY子句创建的组上。
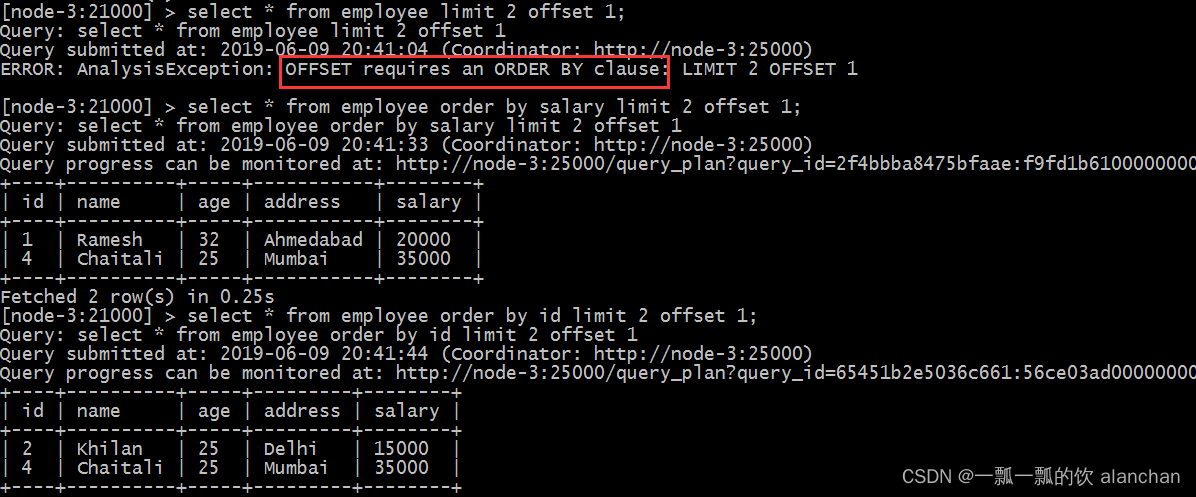
11)、limit、offset
Impala中的limit子句用于将结果集的行数限制为所需的数,即查询的结果集不包含超过指定限制的记录。
一般来说,select查询的resultset中的行从0开始。使用offset子句,可以决定从哪里考虑输出。
12)、with子句
如果查询太复杂,我们可以为复杂部分定义别名,并使用Impala的with子句将它们包含在查询中。
with x as (select 1), y as (select 2) (select * from x union y);
--使用with子句显示年龄大于25的员工和客户的记录。
with t1 as (select * from customers where age>25),
t2 as (select * from employee where age>25)
(select * from t1 union select * from t2);
13)、distinct
Impala中的distinct运算符用于通过删除重复值来获取唯一值。
select distinct columns… from table_name;
二、Impala数据导入方式
1、load data
- 创建一个表:
create table user(id int ,name string,age int )
row format delimited fields terminated by "\t";
准备数据user.txt并上传到hdfs的 /user/impala路径,内容如下图示例

- 加载数据
load data inpath '/user/impala/' into table user;
- 查询加载的数据
select * from user;
-- 如果查询不不到数据,那么需要刷新一遍数据表。
refresh user;
2、insert into values
这种方式非常类似于RDBMS的数据插入方式。
create table t_test2(id int,name string);
insert into table t_test2 values(1,”zhangsan”);
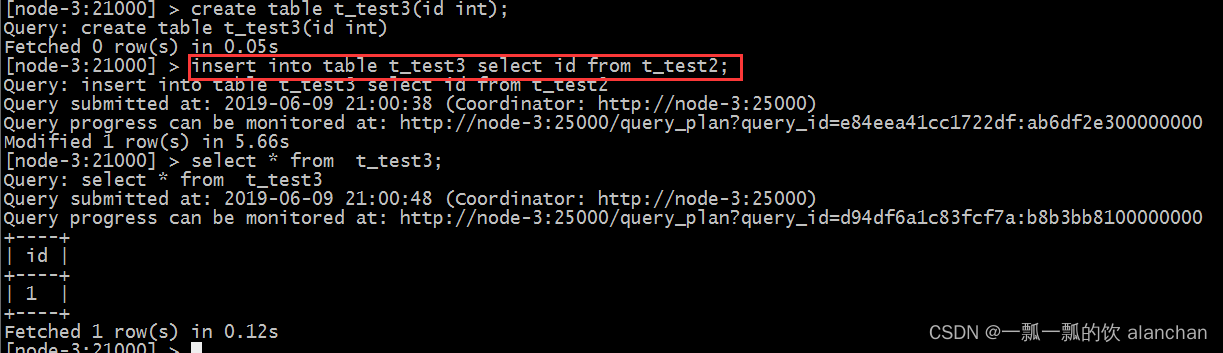
3、insert into select
插入一张表的数据来自于后面的select查询语句返回的结果。示例如下图
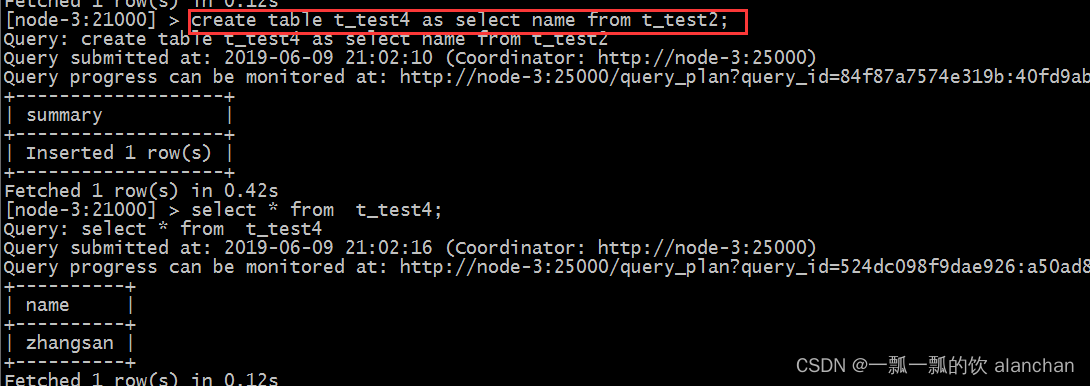
4、create as select
建表的字段个数、类型、数据来自于后续的select查询语句。示例如下图
三、Impala的java开发
使用impala来做数据库查询的情况,可以通过java代码来进行操作impala的查询。
1、下载impala jdbc依赖
下载路径:https://www.cloudera.com/downloads/connectors/impala/jdbc/2-5-28.html
没有maven库可用,需要将下载的lib文件手动加入到工程的lib中
2、java api示例
public static void test(){
Connection con = null;
ResultSet rs = null;
PreparedStatement ps = null;
String JDBC_DRIVER = "com.cloudera.impala.jdbc41.Driver";
String CONNECTION_URL = "jdbc:impala://server6:21050";
try
{
Class.forName(JDBC_DRIVER);
con = (Connection) DriverManager.getConnection(CONNECTION_URL);
ps = con.prepareStatement("select * from test.employee;");
rs = ps.executeQuery();
while (rs.next())
{
System.out.println(rs.getString(1));
System.out.println(rs.getString(2));
System.out.println(rs.getString(3));
}
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try {
rs.close();
ps.close();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
test();
}
四、综合应用案例
其中用到了sqoop、hive和impala,当然其中的基础hadoop肯定用到了
实现2张千万(1260万)级别的表的数据按照id进行join操作,查看其运行时间
总结:
1、将mysql中1260万条数据导入hive中,大概耗时1分钟
2、将hive中1260万条数据复制到hive中,大概耗时1分钟
3、在impala中将两张表按照id进行join,并显示10条,耗时11.3秒
4、在hive中将两张表按照id进行join,并显示10条,耗时97.6秒
5、在impala中,按照user_name='alan816662’查询,耗时1.3s select * from dx_user where user_name = ‘alan816662’ ;
6、在hive中,按照user_name='alan816662’查询,耗时25.2s select * from dx_user where user_name = ‘alan816662’ ;
7、在mysql中,按照user_name='alan816662’查询,耗时6s select * from dx_user where user_name = ‘alan816662’ ;
1、通过sqoop将表直接导入到hive中,dx_user;
- 导入速度还是比较快的,大概在1分钟左右
sqoop import --connect jdbc:mysql://192.168.10.44:3306/test --username root --password rootroot \
--table dx_user \
--hive-import \
--m 1 \
--hive-database test;
[root@server7 lib]# sqoop import --connect jdbc:mysql://192.168.10.44:3306/test --username root --password rootroot \
> --table dx_user \
> --hive-import \
> --m 1 \
> --hive-database test;
2、在impala中,通过create table 创建users表,并插入数据
create table users as select * from dx_user;
[server6:21000] test> create table users as select * from dx_user;
Query: create table users as select * from dx_user
Query submitted at: 2022-11-08 17:27:41 (Coordinator: http://server6:25000)
Query progress can be monitored at: http://server6:25000/query_plan?query_id=b645f9005742c571:856523dd00000000
+--------------------------+
| summary |
+--------------------------+
| Inserted 12606948 row(s) |
+--------------------------+
Fetched 1 row(s) in 73.71s
3、在impala中对dx_user、users进行join 11.3s
select u.* from dx_user u join users us on u.id = us.id limit 10;
[server6:21000] test> select u.* from dx_user u join users us on u.id = us.id limit 10;
Query: select u.* from dx_user u join users us on u.id = us.id limit 10
Query submitted at: 2022-11-08 17:33:36 (Coordinator: http://server6:25000)
Query progress can be monitored at: http://server6:25000/query_plan?query_id=834879fce9994e47:f370cb1900000000
+-----------+------------+-----------+-------------+-----------------------+-----------------------+
| id | user_name | pass_word | phone | email | create_day |
+-----------+------------+-----------+-------------+-----------------------+-----------------------+
| 194771083 | alan816662 | 678425 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 194771168 | alan821590 | 350443 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 194771522 | alan421972 | 405125 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 194772683 | alan340515 | 355354 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 194772716 | alan227440 | 434742 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 194773516 | alan568275 | 407620 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 194774174 | alan359571 | 624075 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 194775609 | alan752851 | 670004 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 194778050 | alan29298 | 525850 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 194778465 | alan351513 | 148031 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+-----------+------------+-----------+-------------+-----------------------+-----------------------+
Fetched 10 row(s) in 11.34s
4、在hive中对dx_user、users进行join 97.6s
0: jdbc:hive2://server8:10000> select u.* from dx_user u join users us on u.id = us.id limit 10;
INFO : Compiling command(queryId=hive_20221108173507_9a00773e-44b6-41a5-8183-20fb26cac837): select u.* from dx_user u join users us on u.id = us.id limit 10
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:u.id, type:int, comment:null), FieldSchema(name:u.user_name, type:string, comment:null), FieldSchema(name:u.pass_word, type:string, comment:null), FieldSchema(name:u.phone, type:string, comment:null), FieldSchema(name:u.email, type:string, comment:null), FieldSchema(name:u.create_day, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20221108173507_9a00773e-44b6-41a5-8183-20fb26cac837); Time taken: 0.167 seconds
INFO : Executing command(queryId=hive_20221108173507_9a00773e-44b6-41a5-8183-20fb26cac837): select u.* from dx_user u join users us on u.id = us.id limit 10
WARN :
INFO : Query ID = hive_20221108173507_9a00773e-44b6-41a5-8183-20fb26cac837
INFO : Total jobs = 1
INFO : Starting task [Stage-5:CONDITIONAL] in serial mode
INFO : Stage-1 is selected by condition resolver.
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks not specified. Estimated from input data size: 32
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:8
INFO : Submitting tokens for job: job_1667806921128_0029
INFO : Executing with tokens: []
INFO : The url to track the job: http://server8:8088/proxy/application_1667806921128_0029/
INFO : Starting Job = job_1667806921128_0029, Tracking URL = http://server8:8088/proxy/application_1667806921128_0029/
INFO : Kill Command = /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop/bin/hadoop job -kill job_1667806921128_0029
INFO : Hadoop job information for Stage-1: number of mappers: 8; number of reducers: 32
INFO : 2022-11-08 17:35:21,629 Stage-1 map = 0%, reduce = 0%
INFO : 2022-11-08 17:35:39,044 Stage-1 map = 8%, reduce = 0%, Cumulative CPU 16.6 sec
INFO : 2022-11-08 17:35:40,065 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 84.91 sec
INFO : 2022-11-08 17:35:42,112 Stage-1 map = 38%, reduce = 0%, Cumulative CPU 88.26 sec
INFO : 2022-11-08 17:35:43,133 Stage-1 map = 42%, reduce = 0%, Cumulative CPU 92.41 sec
INFO : 2022-11-08 17:35:44,153 Stage-1 map = 46%, reduce = 0%, Cumulative CPU 97.14 sec
INFO : 2022-11-08 17:35:45,181 Stage-1 map = 63%, reduce = 0%, Cumulative CPU 108.92 sec
INFO : 2022-11-08 17:35:53,351 Stage-1 map = 75%, reduce = 0%, Cumulative CPU 118.54 sec
INFO : 2022-11-08 17:35:55,387 Stage-1 map = 88%, reduce = 0%, Cumulative CPU 132.31 sec
INFO : 2022-11-08 17:35:59,464 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 147.49 sec
INFO : 2022-11-08 17:36:03,669 Stage-1 map = 100%, reduce = 6%, Cumulative CPU 160.92 sec
INFO : 2022-11-08 17:36:04,693 Stage-1 map = 100%, reduce = 13%, Cumulative CPU 177.2 sec
INFO : 2022-11-08 17:36:07,845 Stage-1 map = 100%, reduce = 16%, Cumulative CPU 184.74 sec
INFO : 2022-11-08 17:36:08,883 Stage-1 map = 100%, reduce = 19%, Cumulative CPU 190.1 sec
INFO : 2022-11-08 17:36:12,015 Stage-1 map = 100%, reduce = 28%, Cumulative CPU 215.15 sec
INFO : 2022-11-08 17:36:15,091 Stage-1 map = 100%, reduce = 34%, Cumulative CPU 227.9 sec
INFO : 2022-11-08 17:36:19,314 Stage-1 map = 100%, reduce = 44%, Cumulative CPU 249.71 sec
INFO : 2022-11-08 17:36:21,366 Stage-1 map = 100%, reduce = 47%, Cumulative CPU 255.4 sec
INFO : 2022-11-08 17:36:22,385 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 262.19 sec
INFO : 2022-11-08 17:36:26,588 Stage-1 map = 100%, reduce = 63%, Cumulative CPU 289.58 sec
INFO : 2022-11-08 17:36:28,631 Stage-1 map = 100%, reduce = 66%, Cumulative CPU 296.3 sec
INFO : 2022-11-08 17:36:32,860 Stage-1 map = 100%, reduce = 75%, Cumulative CPU 315.67 sec
INFO : 2022-11-08 17:36:33,885 Stage-1 map = 100%, reduce = 78%, Cumulative CPU 322.59 sec
INFO : 2022-11-08 17:36:35,945 Stage-1 map = 100%, reduce = 81%, Cumulative CPU 329.1 sec
INFO : 2022-11-08 17:36:38,049 Stage-1 map = 100%, reduce = 84%, Cumulative CPU 334.52 sec
INFO : 2022-11-08 17:36:39,072 Stage-1 map = 100%, reduce = 88%, Cumulative CPU 340.77 sec
INFO : 2022-11-08 17:36:40,090 Stage-1 map = 100%, reduce = 94%, Cumulative CPU 354.81 sec
INFO : 2022-11-08 17:36:41,138 Stage-1 map = 100%, reduce = 97%, Cumulative CPU 361.19 sec
INFO : 2022-11-08 17:36:44,205 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 366.51 sec
INFO : MapReduce Total cumulative CPU time: 6 minutes 6 seconds 510 msec
INFO : Ended Job = job_1667806921128_0029
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 8 Reduce: 32 Cumulative CPU: 366.51 sec HDFS Read: 2112219819 HDFS Write: 33035 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 6 minutes 6 seconds 510 msec
INFO : Completed executing command(queryId=hive_20221108173507_9a00773e-44b6-41a5-8183-20fb26cac837); Time taken: 97.43 seconds
INFO : OK
+-----------+--------------+--------------+--------------+------------------------+------------------------+
| u.id | u.user_name | u.pass_word | u.phone | u.email | u.create_day |
+-----------+--------------+--------------+--------------+------------------------+------------------------+
| 90836928 | alan67100 | 471807 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 90837408 | alan348308 | 553402 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 90838848 | alan167429 | 473683 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 90843456 | alan567446 | 200171 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 90843552 | alan876331 | 267453 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 90843872 | alan387008 | 184127 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 90846048 | alan712188 | 214632 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 90846112 | alan371470 | 265403 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 90846240 | alan48741 | 161574 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 90848576 | alan167204 | 517801 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
+-----------+--------------+--------------+--------------+------------------------+------------------------+
10 rows selected (97.66 seconds)
以上,简单的介绍了impala的sql语法与使用示例,也介绍了impala导入数据的几种方式、java api操作impala,最后用一个综合示例简单的对比了impala和hive的查询速度。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











