







以下内容来自课堂笔记,简单整理了Data Science的Data Mining部分,内容较简单,主要是理解,考试用,概念区分用。

Data Mining Overview
- 数据挖掘定义:Data mining, also known as knowledge discovery in data (KDD), is the process of uncovering patterns and other valuable information from large data sets.也称为数据知识发现(KDD),是从大量数据中发现模式和其他有价值信息的过程。
- 人工智能的两种方法:
- "top-down“ or knowledge-driven AI: cognition = high-level phenomenon, independent of low-level details of implementation mechanism,强调对高层次现象的理解,而忽略实现机制的低层次细节
- "bottom-up“ or data-driven AI: 与前者相反,它从数据开始逐步构建决策机制,并在数学上进行建模
- 人工智能的定义
- by Marvin Lee Minsky, as “the construction of computer programs doing tasks, that are, for the moment, accomplished more satisfyingly by human beings because they require high level mental processes such as: learning. perceptual organization of memory and critical reasoning”.
- "artificial" side: usage of computers or sophisticated electronic processes计算机或复杂的电子流程; and the side “intelligence” associated with its goal to imitate(模仿) the (human) behavior目标是模仿(人类)行为.
- 机器学习定义Machine learning: is programming computers to optimize a performance criterion using example data or past experience.使用示例数据或过去的经验,对计算机进行编程,使其能够优化某一性能标准。
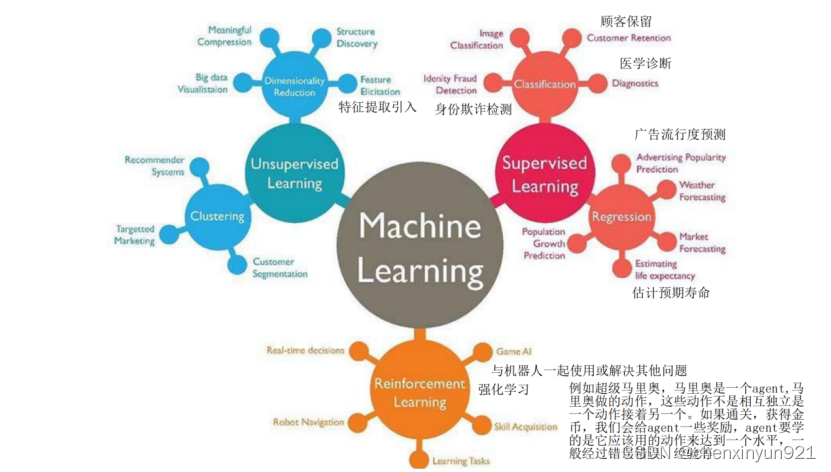

- Learning的意思:Learning general models from a data of particular examples.通过分析具体的数据示例,我们可以构建一种通用模型,使系统能够理解和适应新的数据。数据是廉价且丰富的,而知识则昂贵而稀缺
- Data Mining vs Machine Learning: Data mining looks for patterns that already exist in the data, while machine learning learns from past data to predict future outcomes.
- 有监督学习的2个主要问题分类和回归
- Regression: Output value is quantitative
- 在回归分析中,模型的任务是学习输入特征与连续输出之间的关系,以便对新的输入进行预测,对具体的数值的预测作为输出。
- 应用:如下都是预测出真实数字,例如方向盘的角度等Kinematics of a robot arm,Navigating a car: Angle of the steering wheel (CMU NavLab)
- Classification: Output value is categorical.
- 有预定义的类别:predefined list of possibilities,通常是事先确定的
- 目标是将输入数据分为预定义的类别之一: 模型的任务是通过学习输入数据与这些类别之间的关系,对新数据进行分类(goal is to predict a class label, which is a choice from a predefined list of possibilities), 多分类问题称为multiclass classification
- 例子:Credit scoring P24
- 也被称为模式识别Also known as Pattern recognition
- 监督式图像分割(Supervised Image Segmentation)是图像处理中的一个任务,它与图像分类有一些相似之处。为图像中的每个像素分配相应的标签或属于某个类别的概率,是图像分类的扩展,classify each pixel, trying descide which object it belongs to。
- Regression: Output value is quantitative
- 无监督学习的2个主要问题:降维和聚类
- 数据集转换的定义Unsupervised transformations: 无监督学习中的数据集转换指的是通过某些算法创建新的数据表示,相对于原始表示,这种新表示对于人类或其他机器学习算法更易于理解。create a new =representation of the data
- 数据集转换的一个例子:降维Dimensionality Reduction(可视化目的的二维降维,提取文档话题的文本文档集合主题提取Topic extraction on collections of text documents)
- 聚类Clustering
- 定义: partition data into distinct groups of similar items将数据划分为相似项的不同组
- 目标: points within a single cluster are very similar and points in different clusters are different.以一种方式划分数据,使得单个聚类内的点非常相似,而不同聚类之间的点差异很大
- 数据集转换的定义Unsupervised transformations: 无监督学习中的数据集转换指的是通过某些算法创建新的数据表示,相对于原始表示,这种新表示对于人类或其他机器学习算法更易于理解。create a new =representation of the data
- 强化学习
- Learning a policy: A sequence of outputs
- No supervised output but delayed reward
Data Similarity and Clustering
- Data Similarity: 当一个物体被表示为数据时,我们可以度量对象之间的相似性,或者说对象之间的差异程度。让我们假设将每个对象都表示为一个特征向量。然后,在由这些特征定义的空间中,两个对象距离越近,它们的相似性就越高。Eg.二维和多维度的 Euclidian Distance(P12)等。这单元有两个算法k-Means和Agglomerative Clustering
- k-Means Clustering
- 它试图找到代表数据的特定区域的集群中心
- 2个步骤交替进行,直到数据点不再改变其分配到的聚类
- The algorithm alternates between two steps: assigning each data point to the closest cluster center将每个数据点分配给离它最近的聚类中心
- and then setting each cluster center as the mean of the data points that are assigned to it.更新每个聚类中心的位置,使其成为分配给该聚类中心的所有数据点的平均值
- 具体例子P14
- declaring three data points randomly as cluster centers (“Initialization”)通过随机选择三个数据点作为聚类中心进行了初始化(“初始化”阶段)
- 迭代步骤开始:
- each data point is assigned to the cluster center it is closest to (“Assign Points”).
- Next, the cluster centers are updated to be the mean of the assigned points (“Recompute Centers”)
- repeated two more times
- Cluster centers and cluster boundaries found
- Picking number of cluster centers:使用不同的聚类个数运行,结果可能不同。有的可能导致没有办法做到最初要的聚类那样,使得单个聚类内的点非常相似,而不同聚类之间的点差异很大P32(5个聚类没有明显的界限)
- There is no ground truth, and consequently, the labels themselves have no a priori meaning.聚类标签只反映相似性,欸有真正的含义(不像分类那样有代表猫,狗等这种有先验的事实标签的)
- 不同的聚类数量定义,和初始化聚类中心的位置会造成输出的不同,如何比较选择更好的?损失函数
- Inertia(簇内平方和): Sum of squared distances from each data point to its center. Inertia值越小,表示聚类越紧凑,越好。
- Distortion(畸变): Weighted sum of squared distances from each data point to its center越小越好

- 失败情况:凸形状的限制,kmeans给聚类的直径相同重要(assumes that all directions are equally important for each clusterm, nonspherical clusters or more complex shapes)
- 优缺点
- 缺点:对初始聚类中心位置敏感,对簇形状的假设,需要预先指定簇的数量
- 优点:简单易实现,计算效率高,对于大规模数据集具有较好的可扩展性
- Agglomerative Clustering
- same principles: the algorithm starts by declaring each point its own cluster, and then merges the two most similar clusters until some stopping criterion is satisfied.
- 在scikit-learn中“most similar cluster” is measured的3种 linkage criteria: ward、average和complete:用于度量两个簇之间的相似性,从而确定合并的顺序
- 步骤
- 初始化:将每个数据点视它们自己为聚类中心
- 两个最近的聚类就merge组成bigger cluster
- 直到到达我们需要的几个类(eg.3个聚类就停止)
- 生成的结果叫hierarchical clustering
- 可视化层次聚类过程:
- 二维的,线来表示合并过程:无法用于具有超过两个特征的数据集
- “树状图”(dendrogram),它可以处理多维数据集:可以知道合并顺序(如何合并)和在合并时两个簇的距离,
- Agglomerative clustering still fails at separating complex shapes. agglomerative clustering仍然不能分离出复杂的形状。
Classification
- 这部分有2个算法kNN和决策树
- Classifying Iris Species:第一个应用
- supervised learning problem, three class classification problem.
- Shuffling the dataset: 为了测试集能够包含三种类别来测试,所以进行洗牌
- Splitting the dataset: 测试集和训练集
- k-Nearest Neighbors(KNN): k-最近邻算法进行分类的基本原理。该算法通过存储训练集中的数据点,然后在进行预测时找到距离新数据点最近的邻居,并使用这些邻居的标签进行预测。k-最近邻中的k表示我们可以考虑多个邻居来进行决策,例如,通过考虑最近的三个或五个邻居,并根据它们的多数类别进行最终的分类预测。当类别数为2时,通常选择K为奇数。当K=1时如下为算法步骤:假设P是需要预测的点
- 计算距离:首先,计算待预测点P与训练集中所有点的距离。不同的距离度量,如欧氏距离、汉明距离、曼哈顿距离和闵可夫斯基距离,用于衡量点与点之间的相似性。
- 寻找最近邻居: 找到距离P最近的k个点,这些点成为P的邻居。
- 为标签投票: 对这k个邻居进行投票,每个邻居为它所属类别进行投票。最后,待预测点P被分配到得票最多的类别,作为预测的结果。
- 决策树:
- 图显示了每朵花的花瓣宽度和长度,用颜色标注了不同的种类,可以构建一个决策树P30
- Overfitting: 模型在训练数据上表现得太好,以至于在处理新的、未见过的数据时表现不佳。(It seems like it gets every point correct.)
- 可视化部分:Decision tree has nonlinear boundary
- 生成决策树的算法步骤

- 选择最佳的特征和分割值是关键的决策:等价于在图上画水平线和垂直线Low entropy means more predictable. High entropy means more unpredictable
-
可以用节点熵来解决:用于衡量节点纯度或不纯度的指标之一,一个节点越“纯”,意味着它包含的样本越趋向于属于同一类别。只包含一种类型的节点被称为“纯”节点。节点熵越高,表示节点内部样本的混杂度越大,不同类别的样本混合程度越高,纯度越低。在构建决策树时,我们的目标是选择那些能够降低子节点熵(增加纯度)的特征和分割值,以便于更好地对样本进行分类。


-
我们可以使用加权熵作为一个损失函数来帮助我们决定采取哪个分割(Defining a Best Feature)。使用刚刚那个熵可以计算出加权熵,分别对不同特征算加权熵,选择小的那个更好。


-
生成决策树的步骤可以多加一步:Pick the best feature x and split value β such that the loss of the resulting split is minimized

-
Regression and Model Fitting
- 定义:The goal of regression is to predict the value of one or more continuous target variables t given the value of a D-dimensional vector x of input variables. Regression is similar to classification: you have a number of input features, and you want to predict an output feature. In classification, this output feature is either binary or categorical. With regression, it is a real‐valued number. output as a linear combination of the inputs.
- 需要回归,就要找到X和Y的映射公式
- least squares(可以线性的拟合):回归中的标准拟合方法被称为最小二乘法。
- 最小二乘法(可以线性的拟合)
- 最小二乘法原理:选择使得“惩罚函数”最小化的 m 和 b 的值,该函数通过所有点的误差项进行累加。通过最小化所有数据点的观测值与模型预测值之间的差异的平方和来拟合模型。
- 第一种惩罚函数,使用残差平方和最小确定直线的位置。其中 yi是实际观测值,mxi+b 是对应的模型预测值,m 和 b 是模型的参数。这个函数对于异常值非常敏感,因为它对每个观测值的差异都进行平方,并且较大的差异会被放大。如下:

- 第二种方式,因为前一种对outlier敏感,所以使用绝对值的方式。称为L1 regression。L1回归是误差的绝对值之和。相比于最小二乘法,L1回归对异常值的影响较小,但它对于小的偏离期望值的误差会施加更大的惩罚。并且L1回归在实现上相对复杂,但在处理可能存在异常值的数据时,它可能是一个更为鲁棒的选择。

- 拟合非线性曲线
- 一些模型:
- 增长模型:Exponential growth,Logistic growth,
- 衰减:Exponential decay to some baseline
- 模拟非线性回归的过程步骤
- 获取模拟的数据:通过计算函数 sin(2πx) 的相应值,添加了一个具有高斯分布的小水平随机噪声而得到的
- 使用多项式来拟合:因为是非线性,所以使用了多项式
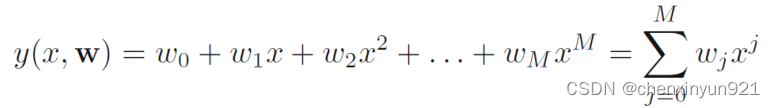
- 误差函数(error function):还是像之前线性一样,使用了误差函数。将预测和实际的标签信息进行比较,最小化这个误差函数来拟合

-
但是我们发现,最小化误差函数会产生过拟合,所以我们引出the root-mean-square (RMS) error,同时评估训练集和测试集来防止过拟合

- 一些模型:
- 限制决策树的复杂度
- Don’t allow fully grown trees: 构建的“完全生长”的决策树存在过拟合的风险,一个避免过拟合的想法
- 防止树生长的方式
- Set one or more special rules
- Pruning: 先充分生长,再剪去不用的部分,eg.使用验证集P56
- 随机森林(防止过拟合)
- 思路:多个决策树,每个决策树模型都对给定的输入x/y进行预测,最后的决策是由所有模型的“投票”结果决定的。
- 只有一个训练集,如何使用一个训练集构建多棵树:Bagging(Bootstrap AGGregatING),基本流程如下:
- 给定包含m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现,初始训练集中约有63.2%的样本出现在来样集中.
- 照这样,我们可采样出T 个含m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器使用简单投票法结合.
- 但是Bagging通常不能足够降低模型的方差,决策树之间经常看起来非常相似。

- 随机森林的样本选择:m = sqrt(p), 选择m个,是p的平方根个,p是特征的总数
- 算法流程如下

- 优点

-
逻辑回归树
Evaluation
- 需要洗牌:确保测试集是打乱的,且包含了各种类别而不是只有一个
- -> The accuracy metric computes how many times a model made a correct prediction across the entire dataset. This can be a reliable metric only if the dataset is class-balanced; that is, each class of the dataset has the same number of samples.
- 混淆矩阵:对类不平衡问题有效
- TNR: Specificity(特异度)也被称为真负率(TNR)。特异度评估我们在所有真实负例中正确识别为假的案例有多少。另一种思考特异度的方式是分类器是否在我们希望它发出警告的特定情况下发出了警告。特异度直观地表示分类器找到所有负样本的能力。特异度的目标是最小化假阳性。只要分类器识别出所有的负例,特异度就会是1.0,即使存在假阴性(假阴性(False Negative)是指实际为正例的样本被错误地预测为负例的情况)。TF是预测的(真假),NP是本身是什么(负例正例真实是什么样的)

- Precision
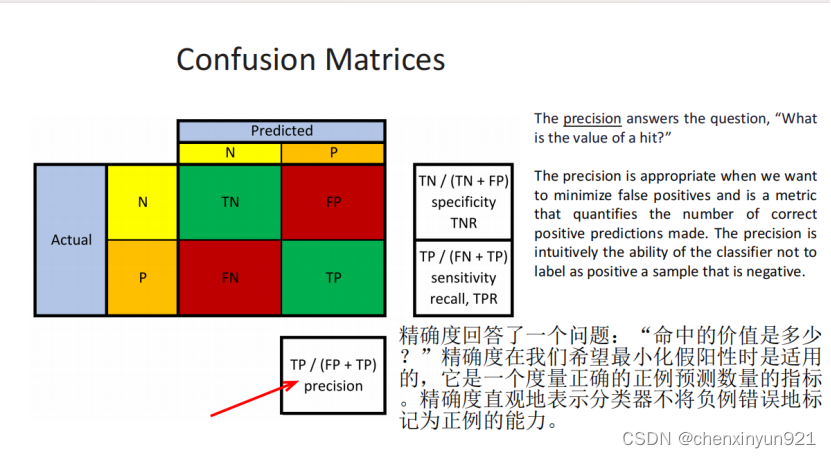
- Recall

-
F1 score
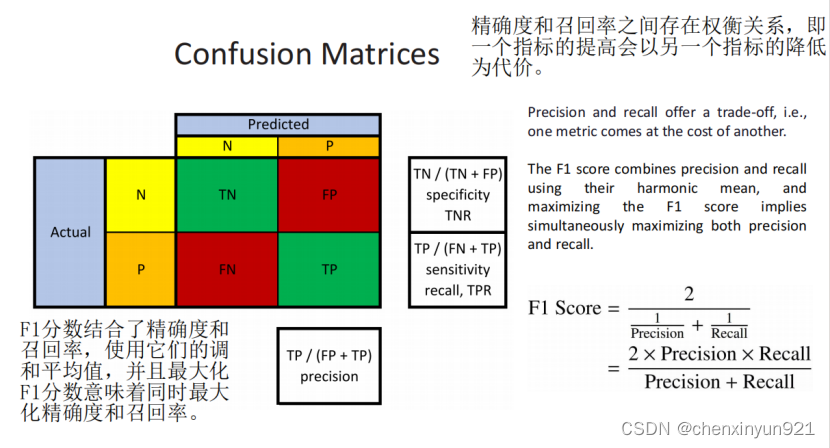
- TNR: Specificity(特异度)也被称为真负率(TNR)。特异度评估我们在所有真实负例中正确识别为假的案例有多少。另一种思考特异度的方式是分类器是否在我们希望它发出警告的特定情况下发出了警告。特异度直观地表示分类器找到所有负样本的能力。特异度的目标是最小化假阳性。只要分类器识别出所有的负例,特异度就会是1.0,即使存在假阴性(假阴性(False Negative)是指实际为正例的样本被错误地预测为负例的情况)。TF是预测的(真假),NP是本身是什么(负例正例真实是什么样的)
- 决策树过拟合的四种方法
- K-fold
- Pruning
- Set one or more special rules
- 随机森林















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









