










 本文是对Ryan P. Adams和David J. C. MacKay关于Bayesian Online Changepoint Detection论文的深入解读,主要针对公式推导进行补充和疑问探讨。作者补充了中间步骤以帮助理解,并质疑了公式中某些部分的独立性假设,特别是关于段落间分布参数的独立性和条件概率的表达。同时,文章指出原论文公式可能存在笔误,并提出了修正意见。
本文是对Ryan P. Adams和David J. C. MacKay关于Bayesian Online Changepoint Detection论文的深入解读,主要针对公式推导进行补充和疑问探讨。作者补充了中间步骤以帮助理解,并质疑了公式中某些部分的独立性假设,特别是关于段落间分布参数的独立性和条件概率的表达。同时,文章指出原论文公式可能存在笔误,并提出了修正意见。
1. 前言
本文是对以下论文的阅读笔记。
Ryan P. Adams, David J.C. MacKay, Bayesian Online Changepoint Detection, arXiv 0710.3742v1 (2007)
关于更基础的解说可以参见:
本文可以看作是以上博文的进一步补充,重点在于原文的公式推导的个人理解及一些补充。
2. 公式推导补充
原论文的公式推导有些跳跃,对于用于良好的数学和概率统计的功底的科班来说当然不是问题,对于本渣这样的山寨出身读起来确实头疼。相信也有对此有同感的人吧。以下追加了一些中间步骤,以及最后提出了一点疑问。公式编号与原论文一致。闲话少说,直接上(虽然优美但是确实万恶的)公式。。。
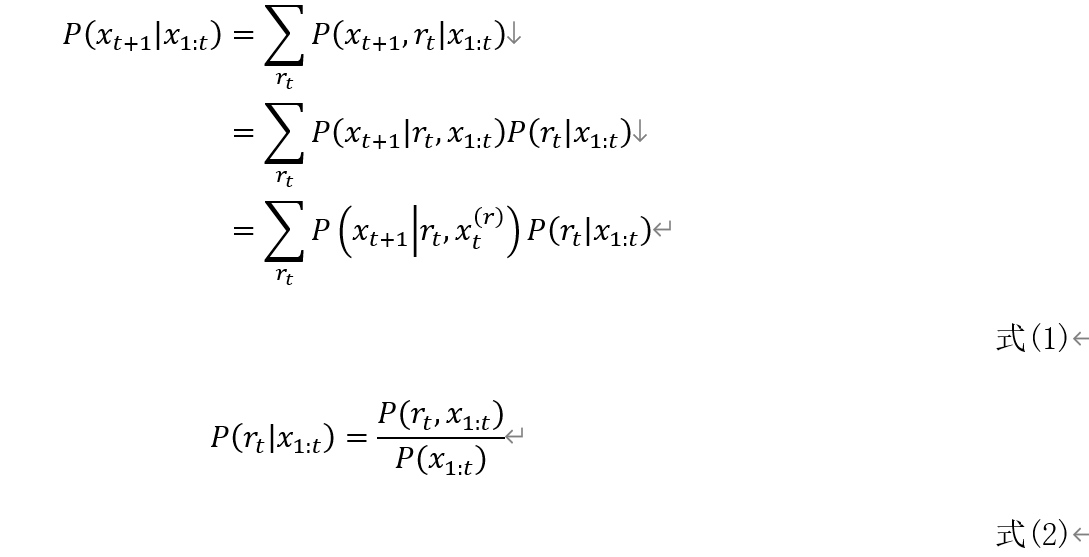
以上推导中,自然是指从时刻1到时刻t的样本序列。而
是指当前到达当前run-length
所对应的样本序列,即从上一个change-point开始到当前时刻为止的序列。即
,
表示上一个变化点发生的时刻。
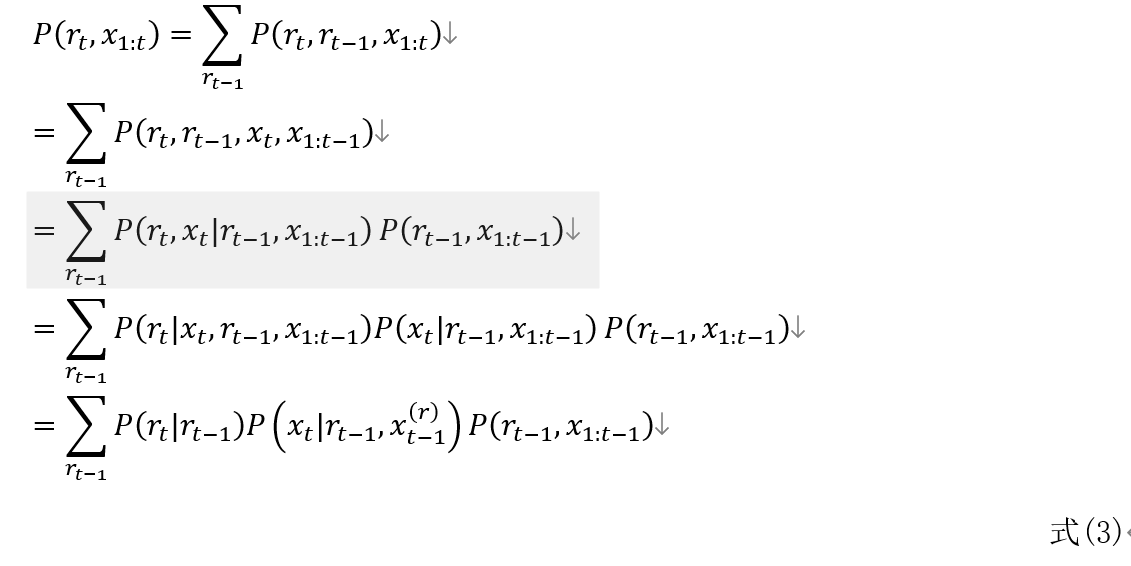
以上推导中隐含了以下两式:
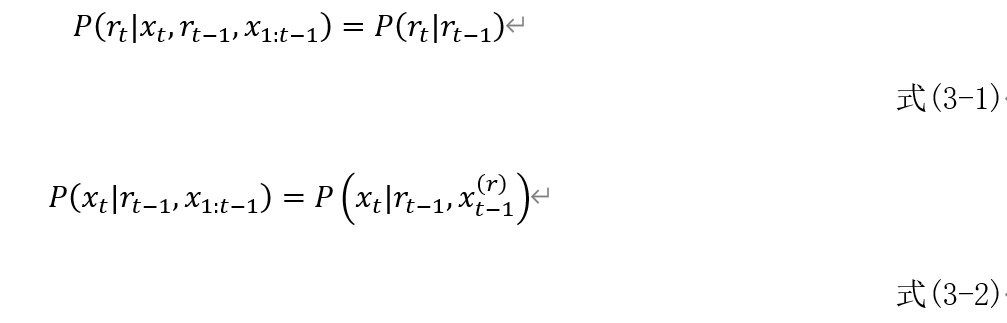
式(3-1)应该是指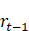 包含了决定
包含了决定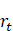 的概率所需要的所有的信息,与
的概率所需要的所有的信息,与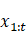 无关。但是为什么呢?与
无关。但是为什么呢?与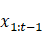 无关比较好理解,但是为什么连
无关比较好理解,但是为什么连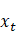 都无关呢?
都无关呢?
关于式(3-2),论文中给出的解释如下所示。

这个是不是因为segmentation/partition间的分布参数是独立的假设相关呢?

此外,原论文中式(3)是写成
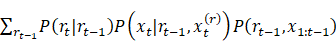
的,我觉得其中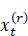 应该是
应该是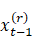 的笔误(参见上面的式(3))。
的笔误(参见上面的式(3))。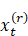 中已经包含了
中已经包含了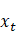 , 同时出现在条件概率的两侧,好像无法理解。
, 同时出现在条件概率的两侧,好像无法理解。
(持续更新中)


















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











