






目录
1 页回收
1.1页回收概述
1.1.1页回收流程
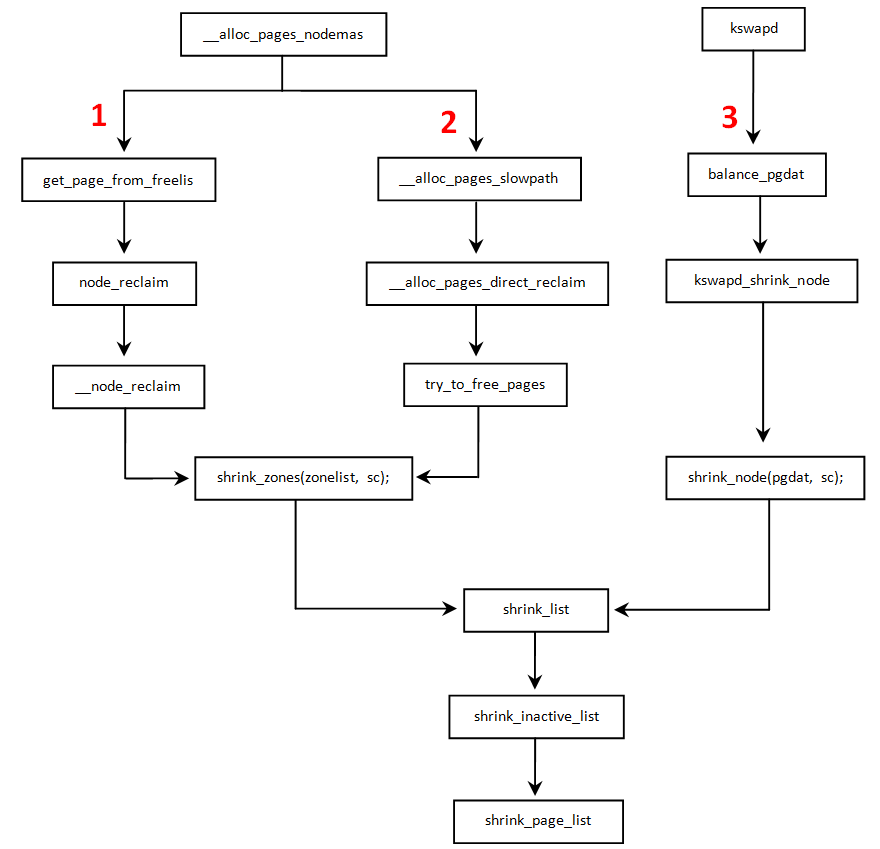
页回收分为三条路径:1)快速内存回收;2)直接内存回收;3)kswapd线程回收。
下面分别讲解这三条回收路线,在讲解具体逻辑之前先看一个结构体:
linux-4.12.3/mm/vmscan.c
struct scan_control {
unsigned long nr_to_reclaim; //需要回收的页数
gfp_t gfp_mask; //如果是申请内存过程中进行页回收,这里是内存分配使用的标致
int order; //内存分配时候指定的order
nodemask_t *nodemask; //指定允许进行页回收的内存节点
struct mem_cgroup *target_mem_cgroup; //如果是针对整个zone做也回收这里指向NULL
int priority; //优先级越低扫描的页数越多,默认优先级是12
enum zone_type reclaim_idx; //指定页回收的最大zone id
unsigned int may_writepage:1; //能否进行回写操作
unsigned int may_unmap:1; //能否进行unmap操作,清除映射了页的所有进程中对应的pte
unsigned int may_swap:1; //是否可以页交换
unsigned int compaction_ready:1; //是否需要内存压缩
unsigned long nr_scanned; //已经扫描的页数
unsigned long nr_reclaimed; //已经回收的页数
};1.1.2快速内存回收
在快速内存分配流程中如果没有分配到足够的页就尝试一次快速内存回收。
__alloc_pages---->__alloc_pages_nodemask---->get_page_from_freelist---->node_reclaim---->__node_reclaim
static int __node_reclaim(struct pglist_data *pgdat, gfp_t gfp_mask, unsigned int order)
{
const unsigned long nr_pages = 1 << order;
struct task_struct *p = current;
struct reclaim_state reclaim_state;
int classzone_idx = gfp_zone(gfp_mask);
unsigned int noreclaim_flag;
struct scan_control sc = {
.nr_to_reclaim = max(nr_pages, SWAP_CLUSTER_MAX), //最少回收32页
.gfp_mask = (gfp_mask = current_gfp_context(gfp_mask)),
.order = order,
.priority = NODE_RECLAIM_PRIORITY, //设置优先级为4
.may_writepage = !!(node_reclaim_mode & RECLAIM_WRITE), //“/proc/sys/vm/zone_reclaim_mode”
.may_unmap = !!(node_reclaim_mode & RECLAIM_UNMAP),
.may_swap = 1, //允许页交换
.reclaim_idx = classzone_idx,
};
……
/*pgdat->min_unmapped_pages 是“/proc/sys/vm/min_unmapped_ratio”乘上总的页数。页缓存中潜在可回收页数如果大于pgdat->min_unmapped_pages才做页回收*/
if (node_pagecache_reclaimable(pgdat) > pgdat->min_unmapped_pages) {
do {
shrink_node(pgdat, &sc); //根据sc控制进行页回收
} while (sc.nr_reclaimed < nr_pages && --sc.priority >= 0); //如果没有回收到足够的页就降低优先级尝试扫描更多的页
}
……
return sc.nr_reclaimed >= nr_pages; //返回是否回收到足够的页
}1.1.3 直接内存回收
如果快速内存分配中没有分配到足够的内存将走慢速分配流程,如果仍然没有可用内存将做直接内存回收
__alloc_pages---->__alloc_pages_nodemask---->__alloc_pages_slowpath---->__alloc_pages_direct_reclaim---->__perform_reclaim---->try_to_free_pages
unsigned long try_to_free_pages(struct zonelist *zonelist, int order,
gfp_t gfp_mask, nodemask_t *nodemask)
{
unsigned long nr_reclaimed;
struct scan_control sc = {
.nr_to_reclaim = SWAP_CLUSTER_MAX, //回收32页
.gfp_mask = (gfp_mask = current_gfp_context(gfp_mask)),
.reclaim_idx = gfp_zone(gfp_mask),
.order = order,
.nodemask = nodemask,
.priority = DEF_PRIORITY, //优先级为12
.may_writepage = !laptop_mode, //如果是掌上电脑,就允许回收过程中回写
.may_unmap = 1, //允许unmap页
.may_swap = 1,//允许进行页交换
};
nr_reclaimed = do_try_to_free_pages(zonelist, &sc);
return nr_reclaimed;
}
static unsigned long do_try_to_free_pages(struct zonelist *zonelist,
struct scan_control *sc)
{
int initial_priority = sc->priority;
pg_data_t *last_pgdat;
struct zoneref *z;
struct zone *zone;
retry:
do {
sc->nr_scanned = 0;
shrink_zones(zonelist, sc); //按照sc中的控制设置做内存回收
if (sc->nr_reclaimed >= sc->nr_to_reclaim) //如果回收到足够的页就返回
break;
if (sc->compaction_ready)
break;
if (sc->priority < DEF_PRIORITY - 2)
sc->may_writepage = 1; //如果没有回收到足够的页,而且优先级也已经降到比较低了,就允许回收过程中回写
} while (--sc->priority >= 0); //降低优先级尝试扫描更多的页
......
if (sc->nr_reclaimed)
return sc->nr_reclaimed; //返回回收到的页数
......
return 0;
}1.1.4 kswapd线程回收
内核线程kswapd会定期扫描或者在需要的时候被唤醒,起具体逻辑后面细讲,这里列出部分代码:
kswapd ---->balance_pgdat
static int balance_pgdat(pg_data_t *pgdat, int order, int classzone_idx)
{
int i;
unsigned long nr_soft_reclaimed;
unsigned long nr_soft_scanned;
struct zone *zone;
struct scan_control sc = {
.gfp_mask = GFP_KERNEL,
.order = order,
.priority = DEF_PRIORITY, //优先级为12
.may_writepage = !laptop_mode,
.may_unmap = 1, //允许unmap 页,也就是允许扫描映射了的页
.may_swap = 1, //允许也交换
};
do {
unsigned long nr_reclaimed = sc.nr_reclaimed;
bool raise_priority = true;
sc.reclaim_idx = classzone_idx;
......
if (kswapd_shrink_node(pgdat, &sc)) //页回收
raise_priority = false;
......
nr_reclaimed = sc.nr_reclaimed - nr_reclaimed;
if (raise_priority || !nr_reclaimed)
sc.priority--; //降低优先级尝试扫描更多的页
} while (sc.priority >= 1);
......
out:
return sc.order;
}1.2 kswapd
开机过程中将会为每个内存节点创建一个内存回收线程,其线程处理函数kswapd:
kswapd_init ----> kswapd_run ----> kswapd
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int classzone_idx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
struct reclaim_state reclaim_state = {
.reclaimed_slab = 0,
};
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
current->reclaim_state = &reclaim_state;
/*设置三个标志分配表示:内存回收过程中可能有内存分配,如果发生内存分配的情况将忽略掉所有限制条件尽最大可能尝试内存分配;当前进程也可能将交换页写入交换分区;当前进程是内存回收进程*/
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;
pgdat->kswapd_order = 0;
pgdat->kswapd_classzone_idx = MAX_NR_ZONES;
for ( ; ; ) {
bool ret;
//在缓存回收线程函数wakeup_kswapd中设置pgdat->kswapd_order
alloc_order = reclaim_order = pgdat->kswapd_order;
classzone_idx = kswapd_classzone_idx(pgdat, classzone_idx);
kswapd_try_sleep:
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
classzone_idx); //检查是否还有充足的内存(大于水印值),如果还有就进入睡眠
alloc_order = reclaim_order = pgdat->kswapd_order;
classzone_idx = kswapd_classzone_idx(pgdat, 0);
pgdat->kswapd_order = 0;
pgdat->kswapd_classzone_idx = MAX_NR_ZONES; //扫描所有内存域
.......
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx); //尝试内存回收
if (reclaim_order < alloc_order)
goto kswapd_try_sleep;//如果没有回收到足够大的连续内存块就重新尝试回收
}
tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);
current->reclaim_state = NULL;
return 0;
}static int balance_pgdat(pg_data_t *pgdat, int order, int classzone_idx)
{
int i;
unsigned long nr_soft_reclaimed;
unsigned long nr_soft_scanned;
struct zone *zone;
struct scan_control sc = { //控制内存回收过程中的处理行为“1.1.1”节中有详细说明
.gfp_mask = GFP_KERNEL,
.order = order,//需要到回收order阶的连续内存
.priority = DEF_PRIORITY, //默认优先级控制扫描页数
.may_writepage = !laptop_mode,
.may_unmap = 1,//允许解除页到进程的映射
.may_swap = 1,//允许进行内存回收操作
};
count_vm_event(PAGEOUTRUN);
do {
unsigned long nr_reclaimed = sc.nr_reclaimed;
bool raise_priority = true;
sc.reclaim_idx = classzone_idx;
if (buffer_heads_over_limit) { //如果缓存太多就尝试从最高内存域开始做内存回收
for (i = MAX_NR_ZONES - 1; i >= 0; i--) {
zone = pgdat->node_zones + i;
if (!managed_zone(zone))//跳过空的内存域
continue;
sc.reclaim_idx = i;
break;
}
}
//判断是否需要回收,判断标准为看空闲页是否大于水印值而且存在sc.order阶的连续内存
if (pgdat_balanced(pgdat, sc.order, classzone_idx))
goto out;
//如果匿名页的inactive链表页太少,就尝试收缩active链表
age_active_anon(pgdat, &sc);
if (sc.priority < DEF_PRIORITY - 2) //如果优先级较高,就允许回写操作,以确保有更多可回收页
sc.may_writepage = 1;
sc.nr_scanned = 0;
nr_soft_scanned = 0;
nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(pgdat, sc.order,
sc.gfp_mask, &nr_soft_scanned);
sc.nr_reclaimed += nr_soft_reclaimed;
//回收内存页,如果扫描的页数大于需要回收的页数nr_to_reclaim,就返回true,尝试提高优先级扫描更多的页
if (kswapd_shrink_node(pgdat, &sc))
raise_priority = false;
nr_reclaimed = sc.nr_reclaimed - nr_reclaimed;//计算回收到的页数
if (raise_priority || !nr_reclaimed)
sc.priority--;
} while (sc.priority >= 1);//循环尝试内存回收直到pgdat_balanced判断为内存页充足为止
if (!sc.nr_reclaimed)
pgdat->kswapd_failures++;//如果没有回收到页统计回收失败次数
out:
return sc.order;
}
static bool kswapd_shrink_node(pg_data_t *pgdat,
struct scan_control *sc)
{
struct zone *zone;
int z;
sc->nr_to_reclaim = 0;
for (z = 0; z <= sc->reclaim_idx; z++) {
zone = pgdat->node_zones + z;
if (!managed_zone(zone))//跳过空的内存域
continue;
sc->nr_to_reclaim += max(high_wmark_pages(zone), SWAP_CLUSTER_MAX);//最多回收32页
}
shrink_node(pgdat, sc);//内存回收
//如果回收的页数已经大于2<< order, 就将忽略order值
if (sc->order && sc->nr_reclaimed >= compact_gap(sc->order))
sc-> order = 0;
//如果扫描的页大于需要回收的页就返回true,说明回收压力较大
return sc->nr_scanned >= sc->nr_to_reclaim;
}
static bool shrink_node(pg_data_t *pgdat, struct scan_control *sc)
{
struct reclaim_state *reclaim_state = current->reclaim_state;
unsigned long nr_reclaimed, nr_scanned;
bool reclaimable = false;
do {
struct mem_cgroup *root = sc->target_mem_cgroup;
struct mem_cgroup_reclaim_cookie reclaim = {
.pgdat = pgdat,
.priority = sc->priority,
};
unsigned long node_lru_pages = 0;
struct mem_cgroup *memcg;
//保存已经回收的页和已经扫描的页
nr_reclaimed = sc->nr_reclaimed;
nr_scanned = sc->nr_scanned;
//如果是回收整个内存域memcg为空
memcg = mem_cgroup_iter(root, NULL, &reclaim);
do {
unsigned long lru_pages;
unsigned long reclaimed;
unsigned long scanned;
......
reclaimed = sc->nr_reclaimed;
scanned = sc->nr_scanned;
//尝试页回收返回lru中内存的大小保存在lru_pages中
shrink_node_memcg(pgdat, memcg, sc, &lru_pages);
node_lru_pages += lru_pages;
if (memcg)//这里memcg为空
shrink_slab(sc->gfp_mask, pgdat->node_id,
memcg, sc->nr_scanned - scanned,
lru_pages);
……
} while ((memcg = mem_cgroup_iter(root, memcg, &reclaim)));
if (global_reclaim(sc))//如果是对整个内存域进行回收,页尝试进行缓存收缩
shrink_slab(sc->gfp_mask, pgdat->node_id, NULL,
sc->nr_scanned - nr_scanned,
node_lru_pages);// (sc->nr_scanned - nr_scanned)/ node_lru_pages这个比例影响缓存回收的多少
if (reclaim_state) {
sc->nr_reclaimed += reclaim_state->reclaimed_slab;
reclaim_state->reclaimed_slab = 0;
}
if (sc->nr_reclaimed - nr_reclaimed)
reclaimable = true;
//判断是否可以通过压缩来满足获取sc->order阶连续页的要求
} while (should_continue_reclaim(pgdat, sc->nr_reclaimed - nr_reclaimed,
sc->nr_scanned - nr_scanned, sc));
return reclaimable;
}
static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *lru_pages)
{
struct lruvec *lruvec = mem_cgroup_lruvec(pgdat, memcg);
unsigned long nr[NR_LRU_LISTS];
unsigned long targets[NR_LRU_LISTS];
unsigned long nr_to_scan;
enum lru_list lru;
unsigned long nr_reclaimed = 0;
unsigned long nr_to_reclaim = sc->nr_to_reclaim;
struct blk_plug plug;
bool scan_adjusted;
//计算各个lru list上扫描的页数
get_scan_count(lruvec, memcg, sc, nr, lru_pages);
memcpy(targets, nr, sizeof(nr));//将扫描的页数保存到targets中
//满足下面三个条件就尝试扫描所有可扫描的页数:1)回收整个内存域;2)当前进程不是回收进程;3)扫描优先级为默认优先级
scan_adjusted = (global_reclaim(sc) && !current_is_kswapd() &&
sc->priority == DEF_PRIORITY);
blk_start_plug(&plug);
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
for_each_evictable_lru(lru) {//遍历除了UNEVICTABLE之外的所有lru链表
if (nr[lru]) {
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);//扫描页数不多余32页
nr[lru] -= nr_to_scan;//更新统计
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, memcg, sc);//尝试lru收缩
}
}
cond_resched();
if (nr_reclaimed < nr_to_reclaim || scan_adjusted)
continue;//如果没有回收到指定数目的页就继续扫描
//计算剩下的还需要扫描的文件页和匿名页
nr_file = nr[LRU_INACTIVE_FILE] + nr[LRU_ACTIVE_FILE];
nr_anon = nr[LRU_INACTIVE_ANON] + nr[LRU_ACTIVE_ANON];
if (!nr_file || !nr_anon)//如果没有需要扫描的文件页或者匿名页就结束扫描
break;
if (nr_file > nr_anon) {
unsigned long scan_target = targets[LRU_INACTIVE_ANON] +
targets[LRU_ACTIVE_ANON] + 1;
lru = LRU_BASE;
percentage = nr_anon * 100 / scan_target; //计算匿名页占总的需要扫描页的比例
} else {
unsigned long scan_target = targets[LRU_INACTIVE_FILE] +
targets[LRU_ACTIVE_FILE] + 1;
lru = LRU_FILE;
percentage = nr_file * 100 / scan_target; //计算文件页占总的需要扫描页的比例
}
nr[lru] = 0;
nr[lru + LRU_ACTIVE] = 0;
//调整扫描的页数
lru = (lru == LRU_FILE) ? LRU_BASE : LRU_FILE;
nr_scanned = targets[lru] - nr[lru];
nr[lru] = targets[lru] * (100 - percentage) / 100;
nr[lru] -= min(nr[lru], nr_scanned);
lru += LRU_ACTIVE;
nr_scanned = targets[lru] - nr[lru];
nr[lru] = targets[lru] * (100 - percentage) / 100;
nr[lru] -= min(nr[lru], nr_scanned);
scan_adjusted = true;
}
blk_finish_plug(&plug);
sc->nr_reclaimed += nr_reclaimed; //统计已经回收的页数
if (inactive_list_is_low(lruvec, false, memcg, sc, true))
shrink_active_list(SWAP_CLUSTER_MAX, lruvec,//如果inactive中页太少就收缩active链表
sc, LRU_ACTIVE_ANON);
}
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
struct lruvec *lruvec, struct mem_cgroup *memcg,
struct scan_control *sc)
{
if (is_active_lru(lru)) {
if (inactive_list_is_low(lruvec, is_file_lru(lru),
memcg, sc, true))
shrink_active_list(nr_to_scan, lruvec, sc, lru); //收缩active链表,将其上的页取出部分挂到inactive中
return 0;
}
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);//页回收
}1.3页回收功能函数
1.3.1 计算扫描页
在叶匡回收之前先要根据sc->priority计算出需要扫描的页框个数,计算出每个lru链表需要扫描的页框数保存到nr[]数组中返回:
static void get_scan_count(struct lruvec *lruvec, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *nr,
unsigned long *lru_pages)
{
int swappiness = mem_cgroup_swappiness(memcg);
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
u64 fraction[2];
u64 denominator = 0; /* gcc */
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
unsigned long anon_prio, file_prio;
enum scan_balance scan_balance;
unsigned long anon, file;
unsigned long ap, fp;
enum lru_list lru;
//如果不允许交换或者没有交换空间就只扫描文件映射页,不扫描匿名映射页
if (!sc->may_swap || mem_cgroup_get_nr_swap_pages(memcg) <= 0) {
scan_balance = SCAN_FILE;
goto out;
}
// swappiness表示页交换的积极程度其值为0~100,如果为0表示不做页交换
if (!global_reclaim(sc) && !swappiness) {
scan_balance = SCAN_FILE;
goto out;
}
if (!sc->priority && swappiness) {
scan_balance = SCAN_EQUAL;//扫描的页数等于lru中页总数的size >> sc->priority
goto out;
}
if (global_reclaim(sc)) {//如果是回收整个内存域
unsigned long pgdatfile;
unsigned long pgdatfree;
int z;
unsigned long total_high_wmark = 0;
pgdatfree = sum_zone_node_page_state(pgdat->node_id, NR_FREE_PAGES);
pgdatfile = node_page_state(pgdat, NR_ACTIVE_FILE) +
node_page_state(pgdat, NR_INACTIVE_FILE);
for (z = 0; z < MAX_NR_ZONES; z++) {
struct zone *zone = &pgdat->node_zones[z];
if (!managed_zone(zone))
continue;
total_high_wmark += high_wmark_pages(zone);
}
//如果空闲页和文件映射页总和都少于高水印值就只扫描匿名映射页
if (unlikely(pgdatfile + pgdatfree <= total_high_wmark)) {
scan_balance = SCAN_ANON;
goto out;
}
}
//如果inactive list中页太少就只扫描文件映射页
if (!inactive_list_is_low(lruvec, true, memcg, sc, false) &&
lruvec_lru_size(lruvec, LRU_INACTIVE_FILE, sc->reclaim_idx) >> sc->priority) {
scan_balance = SCAN_FILE;
goto out;
}
//如果前面的条件都不满足就按比例扫描各个list中的页
scan_balance = SCAN_FRACT;
//扫描匿名页的比例
anon_prio = swappiness;
file_prio = 200 - anon_prio; //计算扫描文件页的比例
//计算匿名页数
anon = lruvec_lru_size(lruvec, LRU_ACTIVE_ANON, MAX_NR_ZONES) +
lruvec_lru_size(lruvec, LRU_INACTIVE_ANON, MAX_NR_ZONES);
file = lruvec_lru_size(lruvec, LRU_ACTIVE_FILE, MAX_NR_ZONES) +
lruvec_lru_size(lruvec, LRU_INACTIVE_FILE, MAX_NR_ZONES);//计算文件页数
spin_lock_irq(&pgdat->lru_lock);
......
//计算匿名页和文件页各自所占的比例,假设recent_scanned和recent_rotated为0,比例是swappiness:200 - anon_prio
ap = anon_prio * (reclaim_stat->recent_scanned[0] + 1);
ap /= reclaim_stat->recent_rotated[0] + 1;
fp = file_prio * (reclaim_stat->recent_scanned[1] + 1);
fp /= reclaim_stat->recent_rotated[1] + 1;
spin_unlock_irq(&pgdat->lru_lock);
fraction[0] = ap;
fraction[1] = fp;
denominator = ap + fp + 1; //计算前述比例的分母
out:
*lru_pages = 0;
for_each_evictable_lru(lru) {
int file = is_file_lru(lru);
unsigned long size;
unsigned long scan;
size = lruvec_lru_size(lruvec, lru, sc->reclaim_idx); //计算当前lru list中的页数
scan = size >> sc->priority; //根据优先级计算需要扫描的页数
if (!scan && !mem_cgroup_online(memcg))
scan = min(size, SWAP_CLUSTER_MAX); //最少扫描32页
switch (scan_balance) {
case SCAN_EQUAL:
break;
case SCAN_FRACT:
scan = div64_u64(scan * fraction[file],
denominator); //计算扫描页数的比例
break;
case SCAN_FILE:
case SCAN_ANON:
if ((scan_balance == SCAN_FILE) != file) {
size = 0;
scan = 0;
}
break;
default:
BUG();
}
*lru_pages += size;
nr[lru] = scan;//保存需要扫描的页数
}
}1.3.2 隔离LRU页
函数isolate_lru_pages用于隔离指定lru中的页,然后通过链表头dst返回
static unsigned long isolate_lru_pages(unsigned long nr_to_scan,
struct lruvec *lruvec, struct list_head *dst,
unsigned long *nr_scanned, struct scan_control *sc,
isolate_mode_t mode, enum lru_list lru)
{
struct list_head *src = &lruvec->lists[lru];
unsigned long nr_taken = 0;
unsigned long nr_zone_taken[MAX_NR_ZONES] = { 0 };
unsigned long nr_skipped[MAX_NR_ZONES] = { 0, };
unsigned long skipped = 0;
unsigned long scan, total_scan, nr_pages;
LIST_HEAD(pages_skipped);
//循环扫描链表src中的页,直到隔离到nr_to_scan个页或者链表src变为空
scan = 0;
for (total_scan = 0;
scan < nr_to_scan && nr_taken < nr_to_scan && !list_empty(src);
total_scan++) {
struct page *page;
page = lru_to_page(src);//出去待考察的页
prefetchw_prev_lru_page(page, src, flags);
if (page_zonenum(page) > sc->reclaim_idx) {
list_move(&page->lru, &pages_skipped);
nr_skipped[page_zonenum(page)]++;//如果不在指定回收内存域范围内就跳过该页
continue;
}
scan++;
switch (__isolate_lru_page(page, mode)) {//考察一个页是否可以隔离
case 0:
nr_pages = hpage_nr_pages(page);
nr_taken += nr_pages;
nr_zone_taken[page_zonenum(page)] += nr_pages;
list_move(&page->lru, dst);//将需要隔离的页放到dst链表中
break;
case -EBUSY:
list_move(&page->lru, src);
continue;
default:
BUG();
}
}
if (!list_empty(&pages_skipped)) {
int zid;
list_splice(&pages_skipped, src);//将需要跳过的页放回src中
for (zid = 0; zid < MAX_NR_ZONES; zid++) {
if (!nr_skipped[zid])
continue;
__count_zid_vm_events(PGSCAN_SKIP, zid, nr_skipped[zid]);
skipped += nr_skipped[zid];
}
}
*nr_scanned = total_scan;//返回已经扫描的页数
update_lru_sizes(lruvec, lru, nr_zone_taken);//更新统计数组
return nr_taken; //返回隔离的页数
}
函数__isolate_lru_page用于考察一个页是否可以隔离
int __isolate_lru_page(struct page *page, isolate_mode_t mode)
{
int ret = -EINVAL;
//如果页不在lru链表上就返回错误
if (!PageLRU(page))
return ret;
//如果页是Unevictable的,而且不允许隔离Unevictable的页,就返回
if (PageUnevictable(page) && !(mode & ISOLATE_UNEVICTABLE))
return ret;
ret = -EBUSY;
//如果设置了ISOLATE_ASYNC_MIGRATE,而且页不会被blocking才隔离
if (mode & ISOLATE_ASYNC_MIGRATE) {
if (PageWriteback(page))//不隔离正在回写的页
return ret;
if (PageDirty(page)) {
struct address_space *mapping;
//如果mapping为空或者migratepage不为空才能保证不会blocking
mapping = page_mapping(page);
if (mapping && !mapping->a_ops->migratepage)
return ret;
}
}
//考察是否隔离已经映射到进程的页,设置了ISOLATE_UNMAPPED表示不隔离映射了的页
if ((mode & ISOLATE_UNMAPPED) && page_mapped(page))
return ret;
//如果页的引用不为0就返回该页的引用计数
if (likely(get_page_unless_zero(page))) {
ClearPageLRU(page);
ret = 0;
}
return ret;
}1.3.3 收缩活动链表
函数shrink_active_list用于收缩活动链表,将活动链表中的部分页放到不活动链表中
static void shrink_active_list(unsigned long nr_to_scan,
struct lruvec *lruvec,
struct scan_control *sc,
enum lru_list lru)
{
unsigned long nr_taken;
unsigned long nr_scanned;
unsigned long vm_flags;
LIST_HEAD(l_hold); /* The pages which were snipped off */
LIST_HEAD(l_active);
LIST_HEAD(l_inactive);
struct page *page;
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
unsigned nr_deactivate, nr_activate;
unsigned nr_rotated = 0;
isolate_mode_t isolate_mode = 0;
int file = is_file_lru(lru); //返回1表示是file lru否者是anon lru
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
//将缓存到lru_add_pvec中的页放到对应的lru 链表中
lru_add_drain();
if (!sc->may_unmap)
isolate_mode |= ISOLATE_UNMAPPED;//不隔离映射到进程的页
spin_lock_irq(&pgdat->lru_lock);
//前一节有讲到下面函数用于隔离部分页,被隔离的页放到l_hold中,隔离的页数返回发到nr_taken中
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &l_hold,
&nr_scanned, sc, isolate_mode, lru);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
reclaim_stat->recent_scanned[file] += nr_taken;//更新统计最近扫描的页数
while (!list_empty(&l_hold)) {
cond_resched();
page = lru_to_page(&l_hold);
list_del(&page->lru);
//如果是unevictable的页就跳过
if (unlikely(!page_evictable(page))) {
putback_lru_page(page);
continue;
}
//如果buffer太多就释放掉页的buffer
if (unlikely(buffer_heads_over_limit)) {
if (page_has_private(page) && trylock_page(page)) {
if (page_has_private(page))
try_to_release_page(page, 0);
unlock_page(page);
}
}
//如果页近期有被访问过而且页中存放的是可执行程序就将其加入到l_active链表中
if (page_referenced(page, 0, sc->target_mem_cgroup,
&vm_flags)) {
nr_rotated += hpage_nr_pages(page);
if ((vm_flags & VM_EXEC) && page_is_file_cache(page)) {
list_add(&page->lru, &l_active);
continue;
}
}
ClearPageActive(page); /* we are de-activating */
list_add(&page->lru, &l_inactive); //将页加入到inactive链表中
}
spin_lock_irq(&pgdat->lru_lock);
reclaim_stat->recent_rotated[file] += nr_rotated;
//将l_active中的页放入active lru链表中,并将引用计数为0的页当到l_hold中
nr_activate = move_active_pages_to_lru(lruvec, &l_active, &l_hold, lru);
//将l_inactive中的页放入inactive lru链表中,并将引用计数为0的页当到l_hold中
nr_deactivate = move_active_pages_to_lru(lruvec, &l_inactive, &l_hold, lru - LRU_ACTIVE);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&pgdat->lru_lock);
//释放引用计数为0的页
free_hot_cold_page_list(&l_hold, true);
}1.3.4 收缩非活动链表
static noinline_for_stack unsigned long
shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec,
struct scan_control *sc, enum lru_list lru)
{
LIST_HEAD(page_list);
unsigned long nr_scanned;
unsigned long nr_reclaimed = 0;
unsigned long nr_taken;
struct reclaim_stat stat = {};
isolate_mode_t isolate_mode = 0;
int file = is_file_lru(lru);
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
while (unlikely(too_many_isolated(pgdat, file, sc))) {
congestion_wait(BLK_RW_ASYNC, HZ/10);//如果隔离的页太多就进入睡眠
if (fatal_signal_pending(current))
return SWAP_CLUSTER_MAX;
}
//将lru缓存中的页释放到各个lru链表中去
lru_add_drain();
if (!sc->may_unmap)
isolate_mode |= ISOLATE_UNMAPPED;
spin_lock_irq(&pgdat->lru_lock);
//隔离部分lru中的页,保存到链表page_list中
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list,
&nr_scanned, sc, isolate_mode, lru);
//下面部分代码做相关统计信息更新
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
reclaim_stat->recent_scanned[file] += nr_taken;
if (global_reclaim(sc)) {
if (current_is_kswapd())
__count_vm_events(PGSCAN_KSWAPD, nr_scanned);
else
__count_vm_events(PGSCAN_DIRECT, nr_scanned);
}
spin_unlock_irq(&pgdat->lru_lock);
if (nr_taken == 0)
return 0;
//执行页面回收,待回收的页放在page_list中,回收完成之后没有被回收的页也被放在page_list中返回
nr_reclaimed = shrink_page_list(&page_list, pgdat, sc, 0,
&stat, false);
spin_lock_irq(&pgdat->lru_lock);
if (global_reclaim(sc)) {
if (current_is_kswapd())
__count_vm_events(PGSTEAL_KSWAPD, nr_reclaimed);
else
__count_vm_events(PGSTEAL_DIRECT, nr_reclaimed);
}
//将没有回收的页放回原有链表中,如果页的引用计数为0 就放到page_list中返回
putback_inactive_pages(lruvec, &page_list);
//释放掉引用计数变为0的页
free_hot_cold_page_list(&page_list, true);
……
return nr_reclaimed;
}1.3.5 执行页面回收
struct reclaim_stat {
unsigned nr_dirty;// page_list中赃页数
unsigned nr_unqueued_dirty;// page_list中赃页但是没有放入块设备请求队列中的页数
unsigned nr_congested;// page_list中阻塞的页数
unsigned nr_writeback; // page_list中处于回写中但是不是被回收的页数
unsigned nr_immediate; //page_list中即回写中而且即将被回收的页数
unsigned nr_activate;// page_list中近期被访问过需要添加到activate list的页数
unsigned nr_ref_keep;// page_list中近期被访问过的页数
unsigned nr_unmap_fail;//解除映射失败的页数
};
static unsigned long shrink_page_list(struct list_head *page_list,
struct pglist_data *pgdat,
struct scan_control *sc,
enum ttu_flags ttu_flags,
struct reclaim_stat *stat,
bool force_reclaim)
{
LIST_HEAD(ret_pages);
LIST_HEAD(free_pages);
int pgactivate = 0;
unsigned nr_unqueued_dirty = 0;
unsigned nr_dirty = 0;
unsigned nr_congested = 0;
unsigned nr_reclaimed = 0;
unsigned nr_writeback = 0;
unsigned nr_immediate = 0;
unsigned nr_ref_keep = 0;
unsigned nr_unmap_fail = 0;
cond_resched();
while (!list_empty(page_list)) {//遍历链表page_list直到为空
struct address_space *mapping;
struct page *page;
int may_enter_fs;
enum page_references references = PAGEREF_RECLAIM_CLEAN;
bool dirty, writeback;
cond_resched();
page = lru_to_page(page_list);
list_del(&page->lru);
//如果页被锁住就跳过该页
if (!trylock_page(page))
goto keep;
sc->nr_scanned++;//增加扫描计数
if (unlikely(!page_evictable(page)))//如果是un evictable页就尝试设置activate并放到ret_pages中
goto activate_locked;
//如果页是映射到进程的,但是不允许回收映射了的页就将页解锁后放到ret_pages中
if (!sc->may_unmap && page_mapped(page))
goto keep_locked;
/*如果是映射页或者交换缓存中的页就double扫描计数,这说明可扫描的页不多应当尽快结束页扫描,否者会影响系统性能*/
if ((page_mapped(page) || PageSwapCache(page)) &&
!(PageAnon(page) && !PageSwapBacked(page)))
sc->nr_scanned++;
//标记是否允许文件系统操作
may_enter_fs = (sc->gfp_mask & __GFP_FS) ||
(PageSwapCache(page) && (sc->gfp_mask & __GFP_IO));
//判断页是否为赃或者处于回写中
page_check_dirty_writeback(page, &dirty, &writeback);
if (dirty || writeback)
nr_dirty++;
//赃但是没有回写,说明页没有被加入块设备请求队列
if (dirty && !writeback)
nr_unqueued_dirty++;
//如果是文件映射返回页的mapping ,如果是匿名映射返回NULL,如果在交换缓存中返回swapper_spaces
mapping = page_mapping(page);
/*两种情况会增加阻塞页框计数:1)赃页或者正在回写的页,而且当前页所在inode的阻塞标志置位;2)页处于回写中而且标记页正在被回收*/
if (((dirty || writeback) && mapping &&
inode_write_congested(mapping->host)) ||
(writeback && PageReclaim(page)))
nr_congested++;
if (PageWriteback(page)) {//页处于回写中,下面处理都是基于这一前提
//设置标志PGDAT_WRITEBACK标识有大量的页处于回写中
if (current_is_kswapd() &&//当前线程是交换线程
PageReclaim(page) &&//页处于回收过程中
test_bit(PGDAT_WRITEBACK, &pgdat->flags)) {
nr_immediate++;//增加nr_immediate统计,表示页即将被回收
goto activate_locked;//将页放到ret_pages中返回
} else if (sane_reclaim(sc) ||//如果回收的是整个内存域就返回true
!PageReclaim(page) || !may_enter_fs) {
SetPageReclaim(page);
nr_writeback++;//增加回写页计数
goto activate_locked;
} else {
unlock_page(page);
wait_on_page_writeback(page);//等页回写完成
list_add_tail(&page->lru, page_list); //将页放到page_list中下次考虑
continue;
}
}
//如果没有设置强制回收就检查页的访问情况
if (!force_reclaim)
references = page_check_references(page, sc);
switch (references) {
case PAGEREF_ACTIVATE:
goto activate_locked;//如果页近期两次被访问过就尝试设置activate并放到ret_pages中
case PAGEREF_KEEP:
nr_ref_keep++;//如果页近期被访问过一次就将其放到ret_pages中
goto keep_locked;
case PAGEREF_RECLAIM:
case PAGEREF_RECLAIM_CLEAN:
; /* try to reclaim the page below *//下面尝试回收这个页
}
//如果是匿名页而且不在交换缓存中就将其添加到交换缓存
if (PageAnon(page) && PageSwapBacked(page) &&
!PageSwapCache(page)) {
if (!(sc->gfp_mask & __GFP_IO))
goto keep_locked;
if (!add_to_swap(page, page_list))
goto activate_locked;
may_enter_fs = 1; //允许文件系统操作
mapping = page_mapping(page);//返回swapper_spaces
} else if (unlikely(PageTransHuge(page))) {
if (split_huge_page_to_list(page, page_list))
goto keep_locked;
}
if (page_mapped(page)) {//如果页有被映射到进程就尝试解除映射
if (!try_to_unmap(page, ttu_flags | TTU_BATCH_FLUSH)) {
nr_unmap_fail++;
goto activate_locked;
}
}
if (PageDirty(page)) {
/*不写出的情况:1)非kswapd进程,只有kswapd 才能文件系统操作,否者可能递归导致栈溢出;2)不是正在回收的页;3)不是正在做大量赃页回写*/
if (page_is_file_cache(page) &&
(!current_is_kswapd() || !PageReclaim(page) ||
!test_bit(PGDAT_DIRTY, &pgdat->flags))) {
inc_node_page_state(page, NR_VMSCAN_IMMEDIATE);
SetPageReclaim(page);
//将页置为activate并添加到ret_pages中
goto activate_locked;
}
if (references == PAGEREF_RECLAIM_CLEAN)
goto keep_locked;//近期有被访问过而且变赃就ret_pages中
if (!may_enter_fs)//不允许文件系统相关操作
goto keep_locked;
if (!sc->may_writepage)//不允许回写
goto keep_locked;
try_to_unmap_flush_dirty();
switch (pageout(page, mapping, sc)) {//将页写出
case PAGE_KEEP:
goto keep_locked;
case PAGE_ACTIVATE:
goto activate_locked;
case PAGE_SUCCESS:
if (PageWriteback(page))
goto keep;
if (PageDirty(page)) //如果页被再次弄脏
goto keep;
if (!trylock_page(page))//页被锁住
goto keep;
if (PageDirty(page) || PageWriteback(page))//页被弄脏或者在回写中
goto keep_locked;
mapping = page_mapping(page);
case PAGE_CLEAN:
; /* try to free the page below */
}
}
if (page_has_private(page)) {
if (!try_to_release_page(page, sc->gfp_mask)) //释放掉页的buffer
goto activate_locked;
if (!mapping && page_count(page) == 1) {
unlock_page(page);
if (put_page_testzero(page))
goto free_it;
else {
nr_reclaimed++;
continue;
}
}
}
if (PageAnon(page) && !PageSwapBacked(page)) {
if (!page_ref_freeze(page, 1))
goto keep_locked;
if (PageDirty(page)) {
page_ref_unfreeze(page, 1);
goto keep_locked;
}
count_vm_event(PGLAZYFREED);
} else if (!mapping || !__remove_mapping(mapping, page, true))//从页缓存中删除
goto keep_locked;
__ClearPageLocked(page);
free_it:
nr_reclaimed++;
list_add(&page->lru, &free_pages); //将页挂到free_pages中等待释放
continue;
activate_locked:
if (PageSwapCache(page) && (mem_cgroup_swap_full(page) ||
PageMlocked(page)))
try_to_free_swap(page);
if (!PageMlocked(page)) {
SetPageActive(page);
pgactivate++;
}
keep_locked:
unlock_page(page);
keep:
list_add(&page->lru, &ret_pages);
VM_BUG_ON_PAGE(PageLRU(page) || PageUnevictable(page), page);
}
mem_cgroup_uncharge_list(&free_pages);
try_to_unmap_flush(); //输出tlb
free_hot_cold_page_list(&free_pages, true); //释放空闲页,没有释放成功的会通过free_pages返回
list_splice(&ret_pages, page_list);//等待进一步处理的页
count_vm_events(PGACTIVATE, pgactivate);
if (stat) {//设置统计量
stat->nr_dirty = nr_dirty;
stat->nr_congested = nr_congested;
stat->nr_unqueued_dirty = nr_unqueued_dirty;
stat->nr_writeback = nr_writeback;
stat->nr_immediate = nr_immediate;
stat->nr_activate = pgactivate;
stat->nr_ref_keep = nr_ref_keep;
stat->nr_unmap_fail = nr_unmap_fail;
}
return nr_reclaimed;
}1.3.6 解除页的映射
bool try_to_unmap(struct page *page, enum ttu_flags flags)
{
struct rmap_walk_control rwc = {
.rmap_one = try_to_unmap_one, //用于解除一页的映射
.arg = (void *)flags,
.done = page_mapcount_is_zero,//获取页的引用计数
.anon_lock = page_lock_anon_vma_read,// 返回匿名页的anon_vma
};
if (flags & TTU_RMAP_LOCKED)
rmap_walk_locked(page, &rwc);
else
rmap_walk(page, &rwc); /*根据页找到anon_vma或者address_space;然后找到对应的vm_area_struct;进而找到对应的pte。最后调用rmap_one解除该页的映射*/
return !page_mapcount(page) ? true : false;
}
void rmap_walk(struct page *page, struct rmap_walk_control *rwc)
{
if (unlikely(PageKsm(page)))
rmap_walk_ksm(page, rwc);
else if (PageAnon(page))
rmap_walk_anon(page, rwc, false);
else
rmap_walk_file(page, rwc, false);
}下面只看匿名映射,关于匿名映射可以参考我之前的一篇文章“Linux进程地址空间管理”
static void rmap_walk_anon(struct page *page, struct rmap_walk_control *rwc,
bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff_start, pgoff_end;
struct anon_vma_chain *avc;
if (locked) {
anon_vma = page_anon_vma(page);
} else {
anon_vma = rmap_walk_anon_lock(page, rwc);// page->mapping 与上~PAGE_MAPPING_FLAGS就是anon_vma
}
if (!anon_vma)
return;
// anon_vma中可能映射了多个页,下面得到page在anon_vma中的起始和结束偏移
pgoff_start = page_to_pgoff(page);
pgoff_end = pgoff_start + hpage_nr_pages(page) - 1;
/*“Linux进程地址空间管理”中有讲过anon_vma代表一个匿名映射,每一个anon_vma对应一个avc,avc联系了vm_area_struct和anon_vma,avc又会加入到anon_vma所在root anon_vma的anon_vma.rb_root中,anon_vma.rb_root中保存的是一组共享映射*/
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root,
pgoff_start, pgoff_end) {
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(page, vma);
if (!rwc->rmap_one(page, vma, address, rwc->arg))//解除page的映射
break;
if (rwc->done && rwc->done(page))
break;
}
}
static bool try_to_unmap_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
struct mm_struct *mm = vma->vm_mm;
struct page_vma_mapped_walk pvmw = { //存放获取pte的相关信息,找到对应的pte之后保存在pvmw.pte中返回
.page = page,
.vma = vma,
.address = address,
};
pte_t pteval;
struct page *subpage;
bool ret = true;
enum ttu_flags flags = (enum ttu_flags)arg;
if ((flags & TTU_MUNLOCK) && !(vma->vm_flags & VM_LOCKED))
return true;
while (page_vma_mapped_walk(&pvmw)) {
……
subpage = page - page_to_pfn(page) + pte_pfn(*pvmw.pte);//page可能是联合页中的一个
address = pvmw.address;
……
flush_cache_page(vma, address, pte_pfn(*pvmw.pte));//刷出cache
if (should_defer_flush(mm, flags)) {
pteval = ptep_get_and_clear(mm, address, pvmw.pte);//获取pte中的值然后清除pte的内容
set_tlb_ubc_flush_pending(mm, pte_dirty(pteval));
} else {
pteval = ptep_clear_flush(vma, address, pvmw.pte); //获取pte中的值然后清除pte的内容,刷新tlb
}
/*系统通过pte_mkdirty(entry)来标记pte dirty,如果是在写的时候触缺页异常或者页换入,系统就会用pte_mkdirty(entry)来标记新页*/
if (pte_dirty(pteval))
set_page_dirty(page);//调用mapping->a_ops->set_page_dirty标记一个页,如果是交换缓存中页将调用到swap_set_page_dirty
//访问HWPoison标记的页将会触发一个异常,这类页不能解除映射
if (PageHWPoison(page) && !(flags & TTU_IGNORE_HWPOISON)) {
if (PageHuge(page)) {
int nr = 1 << compound_order(page);
hugetlb_count_sub(nr, mm);
} else {
dec_mm_counter(mm, mm_counter(page));
}
//构建hwpoison页的pte
pteval = swp_entry_to_pte(make_hwpoison_entry(subpage));
set_pte_at(mm, address, pvmw.pte, pteval);//重新设置映射
} else if (pte_unused(pteval)) {
dec_mm_counter(mm, mm_counter(page));
} else if (IS_ENABLED(CONFIG_MIGRATION) &&
(flags & TTU_MIGRATION)) {
swp_entry_t entry;
pte_t swp_pte;
/*如果这个页正在进行页迁移,就先不要解除映射,pte中设置SWP_MIGRATION_XX,如果访问到这个页将会产生缺页异常,并在do_swap_page中等待迁移完成后返回。*/
entry = make_migration_entry(subpage,
pte_write(pteval));
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
set_pte_at(mm, address, pvmw.pte, swp_pte); //重新映射
} else if (PageAnon(page)) { //如果是匿名页
swp_entry_t entry = { .val = page_private(subpage) };
pte_t swp_pte;
……
if (swap_duplicate(entry) < 0) { //增加交换槽位的引用计数
set_pte_at(mm, address, pvmw.pte, pteval);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
if (list_empty(&mm->mmlist))
list_add(&mm->mmlist, &init_mm.mmlist);
spin_unlock(&mmlist_lock);
}
dec_mm_counter(mm, MM_ANONPAGES);
//构建交换页的pte,并重新映射
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
set_pte_at(mm, address, pvmw.pte, swp_pte);
} else
dec_mm_counter(mm, mm_counter_file(page));
discard:
page_remove_rmap(subpage, PageHuge(page));//从页缓存中删除该页
put_page(page);
mmu_notifier_invalidate_page(mm, address);
}
return ret;
}1.3.7 页写出
static pageout_t pageout(struct page *page, struct address_space *mapping,
struct scan_control *sc)
{
if (!is_page_cache_freeable(page))
return PAGE_KEEP;
if (!mapping) {// 一些数据日记相关的页可能存在page->mapping == NULL
if (page_has_private(page)) {
if (try_to_free_buffers(page)) {//释放掉页的buffers
ClearPageDirty(page);
pr_info("%s: orphaned page\n", __func__);
return PAGE_CLEAN;
}
}
return PAGE_KEEP;
}
if (mapping->a_ops->writepage == NULL)
return PAGE_ACTIVATE;
if (!may_write_to_inode(mapping->host, sc))
return PAGE_KEEP;
//清除页的dirty标记,然后写出该页
if (clear_page_dirty_for_io(page)) {
int res;
struct writeback_control wbc = {
.sync_mode = WB_SYNC_NONE,
.nr_to_write = SWAP_CLUSTER_MAX,
.range_start = 0,
.range_end = LLONG_MAX,
.for_reclaim = 1,
};
SetPageReclaim(page);
res = mapping->a_ops->writepage(page, &wbc); //调用特定文件系统函数写出一个页
if (res < 0)
handle_write_error(mapping, page, res);
if (!PageWriteback(page)) {
ClearPageReclaim(page);
}
inc_node_page_state(page, NR_VMSCAN_WRITE);
return PAGE_SUCCESS;
}
return PAGE_CLEAN;
}1.4 内存压缩
----------------------------待续-------------------------------
2 缓存收缩
----------------------------待续-------------------------------
3 OOM
----------------------------待续-------------------------------















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









