







导语
在模型训练过程中,我们通常会遇到过拟合与欠拟合问题。其中欠拟合是指模型未考虑足够的样本信息而无法对真实情况精确建模的现象。比如一个小孩第一次见到天鹅后认为鸭子也是天鹅。反之,过拟合指的则是模型过度考虑样本信息而无法对真实情况精确建模的现象。我们还举刚才的例子,小孩看到的有:天鹅有翅膀和黄色的嘴巴,天鹅脖子是长长的且有点曲度,天鹅的整个体型略大于鸭子,而且恰巧这些天鹅的羽毛全都是白色的。这导致他以后看到羽毛是黑色的天鹅就会认为那不是天鹅。诚然,这两个问题都将导致模型的泛化能力弱,要如何才能防止这类问题的发生呢?对于欠拟合问题,通常只需增大训练样本数以及适量增加特征即可解决;而对于过拟合问题,应对方法除了常规的特征选择与数据集扩增以外,我们通常还会给损失函数加上一个正则项进行权重抑制。那么,这个正则项具体是什么?又是如何起作用的呢?
把控拟合方向的马车夫
机模型训练,说到底都是参数估计问题。比如我们要拟合一条直线,模型是 y=ax+b ,其中的a和b就是我们需要估计的参数,而每一个参数代表的就是一个特征的权重。还拿之前天鹅的例子来说,小孩之所以不认识黑色的天鹅,是因为“天鹅是白色的”这个特征的权重在他认知里的得分很高。而把正则项加入损失函数一起计算可以抑制这些过高的权重,甚至能让某些权重变为0(实现特征稀疏),从而把控模型的整体拟合方向。就像马车夫,拉着模型这驾马车朝着正确的方向跑去。
目前正则项一共有三种:L0范数、L1范数和L2范数。这三种正则项接下来我将分别讲解其作用和原理。
L0范数
L0范数表示向量中非零元素的个数,其数学形式如下:
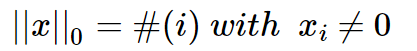
直观上看,降低非零权重参数的个数可以很好地剔除局部特征(比如上面例子里天鹅的羽毛颜色),实现特征稀疏(原因可见上篇文章 ),使模型拥有较强的泛化能力。但是,由于L0范数很难求解,我们通常放弃这个方法。直观上我是这样理解这个问题得难解性的:L0的目标是特征权重非0即1,也正因为它的取值非0即1,导致其本身无法计算梯度,使得在训练过程中每一步迭代后得到的基本都是非0结果,从而无法最优化。
L1范数
L1范数表示向量中每个参数绝对值的和,其有个美称叫“稀疏规则算子”(Lasso regularization),数学形式如下:
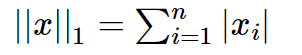
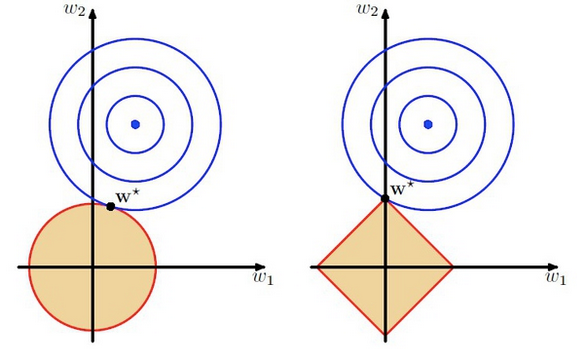
L1正则是如何实现特征稀疏的呢?我们不妨举个简单的栗子: y=w1x1+w2x2+b ,对这个线性模型我们加入正则项 ||w||1 。如下图右所示,蓝色等高线表示损失函数的等高值,蓝色圆心表示损失函数最小时的最优 w 参数值;而红色平行四边形表示L1正则项条件下的
L2范数
L2范数就是我们常说的欧氏距离,其也有个美称,叫“岭回归”(Ridge regularization),数学形式如下:
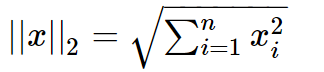
可知,L2范数越小,使得 w <script type="math/tex" id="MathJax-Element-63">w</script>的每个权重参数都很小,但其与L1范数不同之处在于它不会让权重等于0而是接近于0,如上图左所示。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
结语
以上便是我对机器学习中正则项的理解。此外,防止过拟合的方法还有很多,诸如减少特征、权值衰减、Early stopping、数据验证、扩增数据集和Dropout等方法都大有学问,以后有机会再补上。在此感谢各位的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注小斗公众号 对半独白!
















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









