






4.1使用SAS过程步
PROC语句 所有的语句的必须部分为proc+过程名
BY语句 BY语句在过程proc sort中是必须的,它用来对观测值排序。其他过程BY用来对变量进行分别分析
TITLE和FOOTNOTE语句
LABEL语句
4.7使用proc format创建自己的格式
注意,变量值是字符串时要加上引号,range不止一个值要用逗号隔开,连续的range要用-。关键字low和high可以用来指代变量中的最小和最大的非缺失值。DATA carsurvey;
INFILE 'c:\MyRawData\Cars.dat';
INPUT Age Sex Income Color $;
PROC FORMAT;
VALUE gender 1 = 'Male'
2 = 'Female';
VALUE agegroup 13 -< 20 = 'Teen'
20 -< 65 = 'Adult'
65 -< HIGH = 'Senior';
VALUE $ col 'W' = 'Moon White'
'B' = 'Sky Blue'
'Y' = 'Sunburst Yellow';
PROC PRINT DATA = carsurvey;
FORMAT Sex gender. Age agegroup. Color $col.;
TITLE 'Survey Result Print with User-Defined Formats';
RUN;4.8定制一个简单的报告
data Candy;
INPUT Name $ Class DateReturned MMDDYY10. CandyType $ Quantity;
CARDS;
Adriana 21 3/21/2000 MP 7
Nathan 14 3/21/2000 CD 19
Matthew 14 3/21/2000 CD 14
Claire 14 3/22/2000 CD 11
Caitlin 21 3/24/2000 CD 9
Ian 21 3/24/2000 MP 18
Chris 14 3/25/2000 CD 6
Anthony 21 3/25/2000 MP 13
Stephen 14 3/25/2000 CD 10
Erika 21 3/25/2000 MP 17
;
RUN;
*Write a report with FILE and PUT statement;
DATA _NULL_;
SET Candy;
Profit = Quantity * 1.25;
FILE 'C:\Users\lei\Desktop\Student.rep' PRINT;
TITLE;
PUT @5 'Candy sales report for ' Name 'from classroom' Class
/ @5 'Congratulations: You sold ' Quantity 'boxes of candy'
/ @5 'and earnd ' Profit DOLLAR6.2 ' for our field trip.'
//;
RUN;DATA _NULL_ 是告诉SAS不要写数据集名,以便程序更快。FILE语句创造了一个输出文件。空标题TITLE语句告诉SAS除去所有的自动标题。指示器@n指定移动到第n行,+n指定移动n行,/移动到下一行(//移动两行),#n跳动到第n行,用@hold保留在当前行?
4.9使用proc means描述数据
具体形式,PROC MEANS ;语句;RUN;
其中,包括,data=数据集;maxdec=指定输出结果小数位数,默认为7位;noprint,禁止结果在output窗口输出;alpha,设置可信区间水平,默认为0.05.
<stattistics-keywords>:包括MAX,MIN,MEAN,MEDIAN,NMISS,RANGE,STDDEV,SUM。若不加统计关键词默认打印顺序为非缺失值个数(N),均值(MEAN),标准差(STDDEV),最小值(MIN),最大值(MAX)语句包括,BY variable-list;分变量单独分析,但数据须先按照variable-list的变量顺序排序(proc sort).
CLASS variable-list;分变量单独分析,会更集中一些,且不需要排序
VAR variable-list;指定分析哪种数值变量,默认则使用所有的数值变量。DATA sales;
INPUT CustomerID $ SaleDate MMDDYY10. Petunia SnapDragon Marigold;
CARDS;
756-01 05/05/2001 120 80 110
834-01 05/12/2001 90 160 60
901-02 05/18/2001 50 100 75
834-01 06/01/2001 80 60 100
756-01 06/11/2001 100 160 75
901-02 06/19/2001 60 60 60
756-01 06/25/2001 85 110 100
;
RUN;
*使用VAR;
data sales;
set sales;
Month = MONTH(SaleDate);
PROC SORT DATA=sales;
By Month;
*Calculate means by Month for flower sales;
PROC MEANS DATA=sales;
BY month;
VAR Petunia SnapDragon Marigold;
TITLE 'Summary of Flower Sales by Month';
RUN;
#example2. from sas base 70;
proc format;
value agegrp
low-12 = 'Pre-Teen'
13-high = 'Teen';
run;
proc means data=sashelp.class;
var height;
class sex Age;
format Age agegrp.;
run;
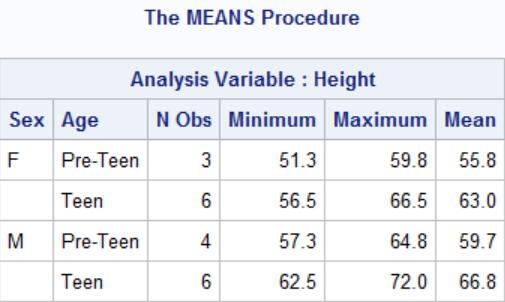
proc means data=sashelp.class min max mean maxdec=1;
var height;
class sex age;
format age agegrp.;
run;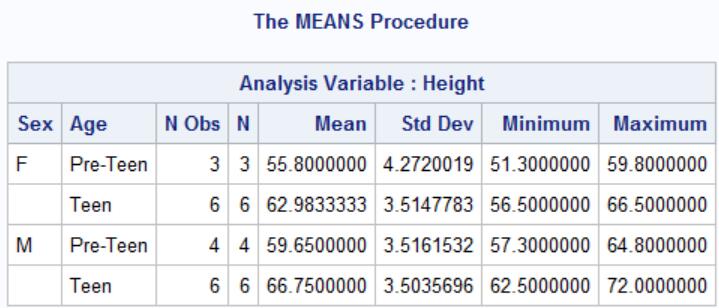
4.10将描述性统计写入SAS数据集中
PROC SORT DATA = sales;
by CustomerID;
PROC MEANS NOPRINT DATA = sales;
By CustomerID;
VAR Petunia SnapDragon Marigold;
OUTPUT OUT = totals MEAN(Petunia SnapDragon Marigold) = MeanP MeanS MeanM;
PROC PRINT DATA = totals;
RUN;4.11使用proc freq为数据计数
基本形式 PROC FREQ; TABLES variable-combinations;
产生一维频率表,只要列出变量名,如TABLES YearsEducation;
建立两个变量的交叉表需要一个*号,如TABLE Sex*YearsEducation,表示Sex by YearEducation,
这个语句之后可以用/option的形式添加选项,主要有:List,用list形式打印交叉表(而不是网络);MISSING,频率统计量中包含缺失值;NOCOL,NOROW,在交叉表中不包含列/行百分比;OUT=data-set输出数据集。
默认计算频数、百分比、累积频数和累积百分比 Proc freq data=learn.survey; Table Gender Ques1-Ques3/nocum; Run; Nocum告诉SAS不要包含两个累积统计量,同理可用NOPERCENT去掉百分比统计量。
用FORMAT 进行分组统计
注意MISSING选项
两者结果不同,有MISSING选项的会单独列出缺失值个数
二维列联表
PROC FREQ data=learn.blood; Tables GenderBloodType; Run;
多重二维表
Tables (A B)(C D);
Tables A * ( B C D);
4.12使用proc tabulate产生一个表格报告
基本形式,PROC TABULATE;
CLASS classification-variable-list;
TABLE page-dimension, row-dimension, column-dimension;














 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









