






 本文介绍了Linux中如何在一个PCB结构中同时支持双向链表和多叉树的数据结构,探讨了进程优先级的实现,以及如何通过nice值调整进程优先级,涉及CPU调度算法和进程队列管理。
本文介绍了Linux中如何在一个PCB结构中同时支持双向链表和多叉树的数据结构,探讨了进程优先级的实现,以及如何通过nice值调整进程优先级,涉及CPU调度算法和进程队列管理。
理解linux 当中如何做到 把一个PCB 放到多个 数据结构当中
在Linux 当中,一个进程的 PCB 不会仅仅值存在一个 数据结构当中,他既可以在 某一个队列当中,又可以在 一个 多叉树当中。
队列比如 cpu 的 运行队列,键盘的阻塞队列等等的双线链表当中。
而多叉树就本篇博客需要阐述的 进程优先级了。
如何实现的其实也很简单,就是在一个 PCB 结构体对象当中,不仅仅只有 双链表的 prev 前序结点指针和 next 后继结点指针;还有 多叉树当中的 比如 parent 父亲结点指针,和各个孩子的指针。这时,因为链式的数据结构管理各个 进程的 PCB 结构体对象也是通过这个结构体对象的 指针来实现管理的。所以,我们才说一个结点就可以插入到 一个双向链表当中,又可以插入到 一个多叉树当中。
下面,简单实现一个 PCB 结构体的 demo,来理解:
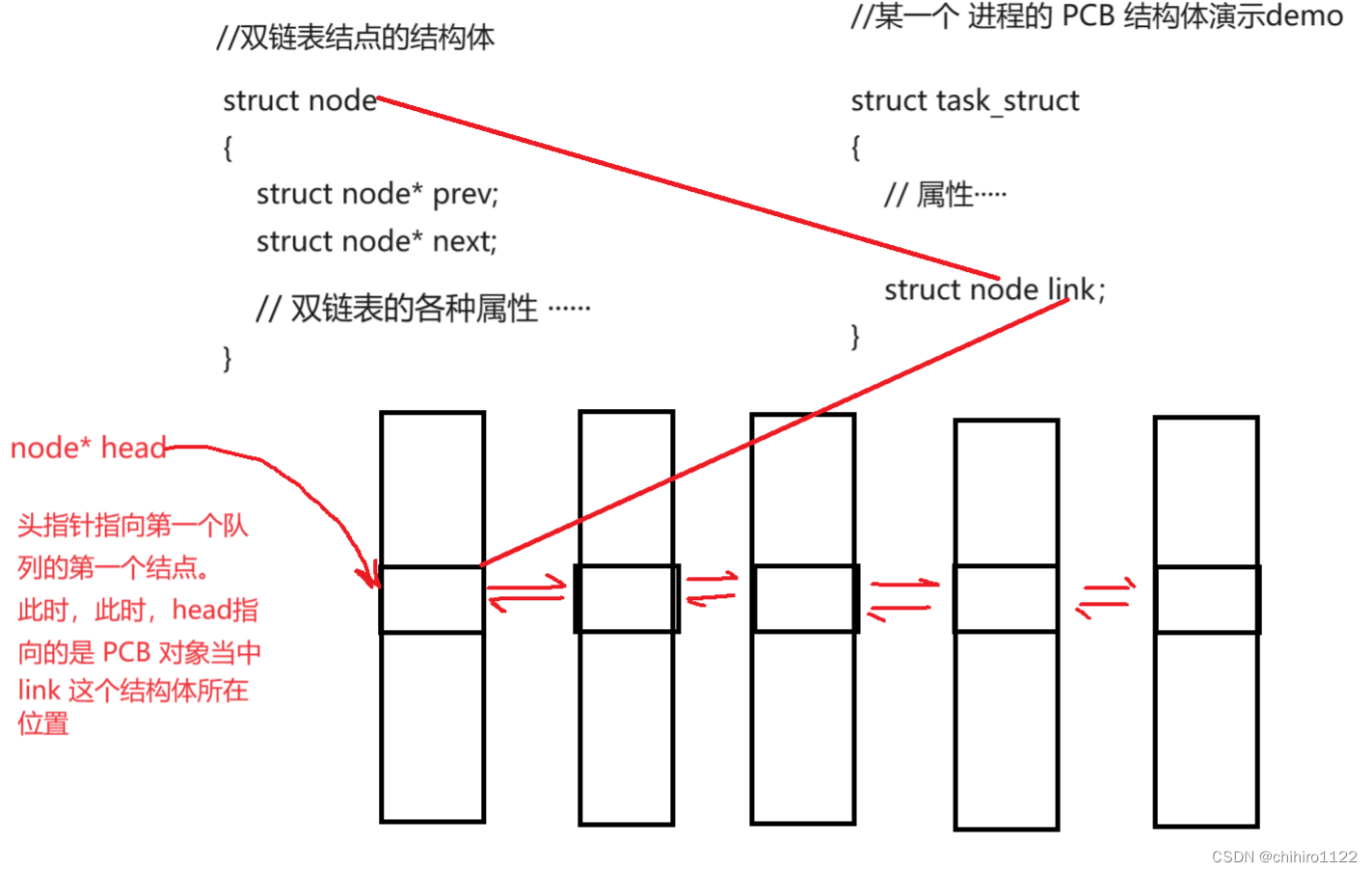
如上所示,通过在 PCB 结构体当中,内嵌一个 双链表结点的结构体,来维持 这个PCB在某一个 双链队列当中的存储位置。
这样,就可以通过一个 PCB 来找到这个 PCB 所在队列的所以的PCB 了,也就相当于是把 这个PCB链接到某一个队列当中了。
但是,这样的话有一个问题,就是,我可以找到 存在与 各个 PCB 对象当中的 link 结构体对象在各个 PCB 当中存储的位置,但是,如果我们想要访问整个 PCB对象的话,需要拿到 PCB 对象的地址(存储 PCB 对象起始位置的 PCB类型的结构体指针)。
所以,结合上述 demo,我们用以下方式来 计算出 link 和 link所在PCB对象当中的 地址偏移量,然后 得到 PCB 对象的起始地址:
(task_struct*)((char*)head - (char*)&(task_struct*)0->link) -> other上述代码就可以拿到 PCB 的起始地址,然后访问 PCB 当中的 其他 (other)属性。
怎么做到的呢?我们来一步一步看:

(上述的 head 和 &(task_struct*)0->link 要强转成 char* 类似的,以为此时是以 数字的方式来看待的,而不是指针,我们是为了计算出偏移量。但是上述为了图片的 宽度没有写上。)画个图来 理解:
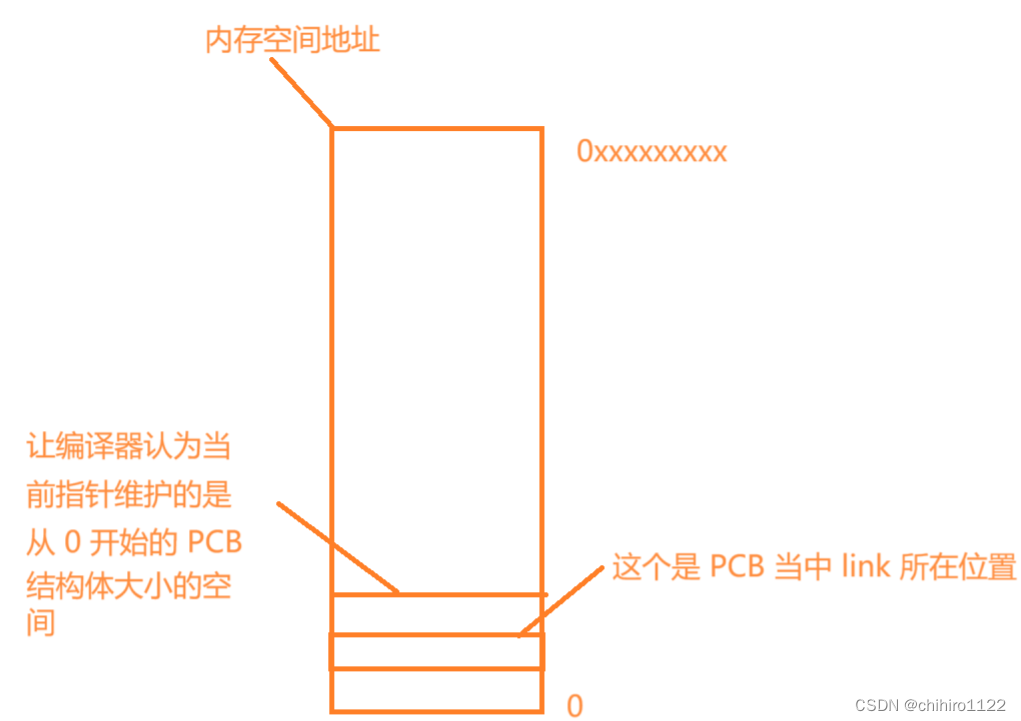
利用 0 开始 的 PCB 结构体指针,计算出 link 距离 PCB 起始位置的 偏移量(相对距离)。
像上述是一个PCB 的访问方式,当然,一个队列当中会有很多个,不同种类的 PCB 对象,那么其中的 link 所在位置也是不一样的,但是都可以同种上述的方式来,计算出当前PCB当中 link 相对于 PCB 起始位置的偏移量。
进程的优先级
因为资源是有限的,进程有很多个,所以,注定了进程之间是竞争关系。
操作系统必须要保证 各个进程之间必须要 良性竞争。 所以,制定了优先级,对于各个进程之间,对于资源的访问,谁先谁后,由进程各自的优先级决定。
cpu资源分配的先后顺序,就是指进程的优先权(priority)。
优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可能改善系统性能。
还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
如果因为调度算法不合理,优先级设定算法不合理,就会导致某些进程长时间得不到CPU资源,某些进程的代码长时间得不到推进。造成了该进程的饥饿问题。
这种饥饿问题,在用户体验上看来就是,某个进程卡死了,得不到响应。就像在 windows 当中,可能遇到过其他进程都没事,但是某一个进程卡死了,提示无法响应,此时你会有两个选项:结束进程或者是再等等。
我们可以使用 ps -l 查看当前终端下,用户启动的 进程,但是这个命令不能查看单独由其他终端启动的进程。如果想查看的话,可以再多加一个 -a 选项来查看用户启动的全部进程:

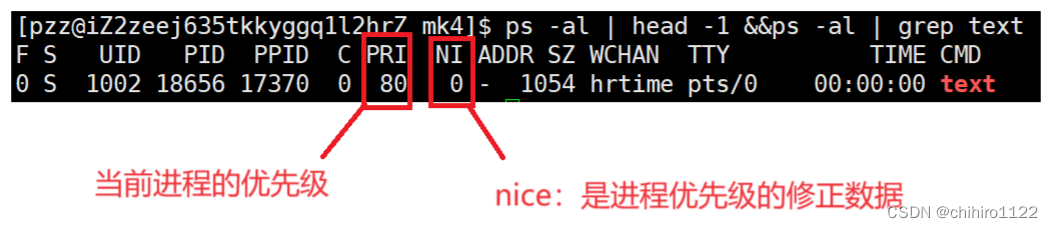
UID 的解释:因为计算机只认识数字,所以,区分各个 用户也是使用数字来区分的,UID 就是各个用户独有的ID,就像身份证号一样,在这个操作系统当中,一个用户的这一个 ID 是独有的。
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。
NI 的解释:因为 操作系统当中的调度器,要更具当前操作系统的需求,或者是用户的需求,要给根据算法来修改某一个进程的 优先级,但是原来的优先级是 调度器计算出来非常合理的优先级,也就是 PRI 是刚开始计算出来最合理的优先级,所以这个 PRI 优先级是要保存的;所以,如果调度器要修改优先级的话,修改的不是 PRI,而是使用 PRI(new)=PRI(old)+nice 。从而使用 PRI(new)作为现在 进程所使用的优先级。当 此时 操作系统和用户没有再需求之后,就会使用 原本的 PRI 优先级。
虽然都是按照 PRI(new)=PRI(old)+nice 这个公式来进行修改的,但是 PRI(old)是不变的,默认一直都是 80 。
这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行所以,调整进程优先级。
需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
那么,既然优先级可以被调整,那么是不是就以为这个,我们可以把一个 进程的nice 值,调的非常的低,使得这个进程优先级很高,一直被调度?答案是不行的。
Linux不想过多的让用户参与到 优先级的调整当中,只能在对应的范围之内膝盖 nice 值。超过范围,只能给范围的极值作为值返回,不能超过极值。
在Linux下,就是调整进程nice值nice其取值范围是-20至19,一共40个级别。
利用 top 修改nice的同时修改 进程的 PRI(new)
top 是任务管理器,当我们在 top 窗口当中,按下 r 键,就可以执行 renice 命令:
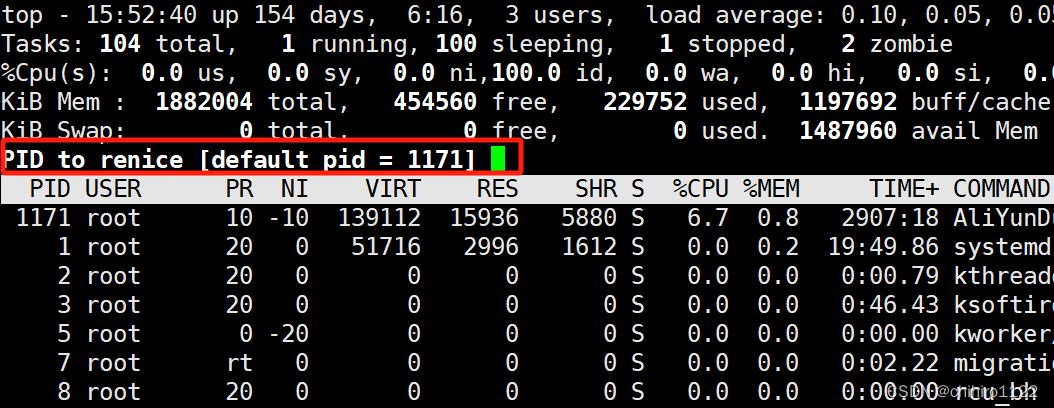
此时它提示我们输入 某个进程 的PID,我们就输入 我们自己写的 死循环进程的PID:

回车之后,就会提示我们,要修改的nice值为多少,我们就可以再 上述所说的 nice 的区间当中给值,就算是 超出了,也就给出对应分为的极值。比如我们现在给出 100:
![]()
回车之后就会修改 nice 值:
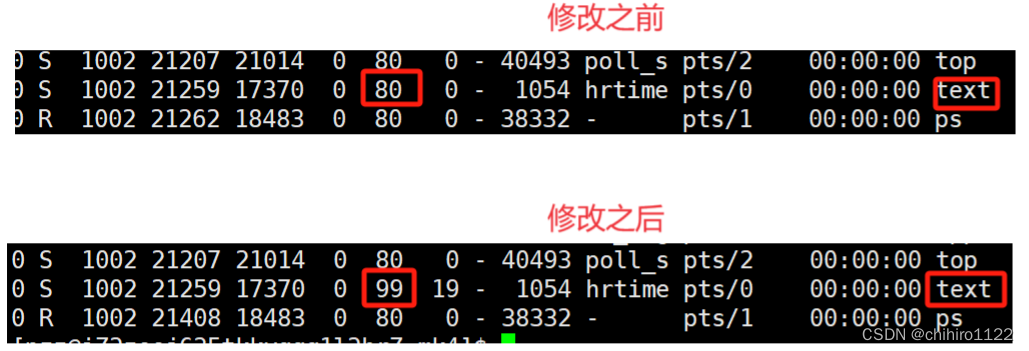
因为 nice 最大就是 19,所以,此时就是修改到了 99。
Linux当中 cpu 当中调度不同优先级的做法
在 cpu 当中有一个运行队列,这些队列当中的使用指针的方式排列着 处于运行状态的 进程的PCB指针。但是,这些进程的 优先级有大有小,cpu 是如何调度其中的 进程的呢?
其实在这个运行队列当中,会存储两个 存储 PCB指针的 指针数组,这个两个数组一般的大小是 140 个元素,前 0-99 个元素存储的是其他进程的 task_struct指针,在后面的 [100 - 139 )这个刚好 40 个元素 的指针就是存储的是 我们可以修改的 nice 指针的数目。
我们用这 40 个元素做例子:
我们可以修改到的 优先级范围就在 [60 , 99) 这个区间当中,这个区间就刚好映射到了 [100, 139 ) 这个指针数组的下标。那么我们就可以根据优先级,映射到 这个指针数组下标。类似这样的结构,如下图所示:
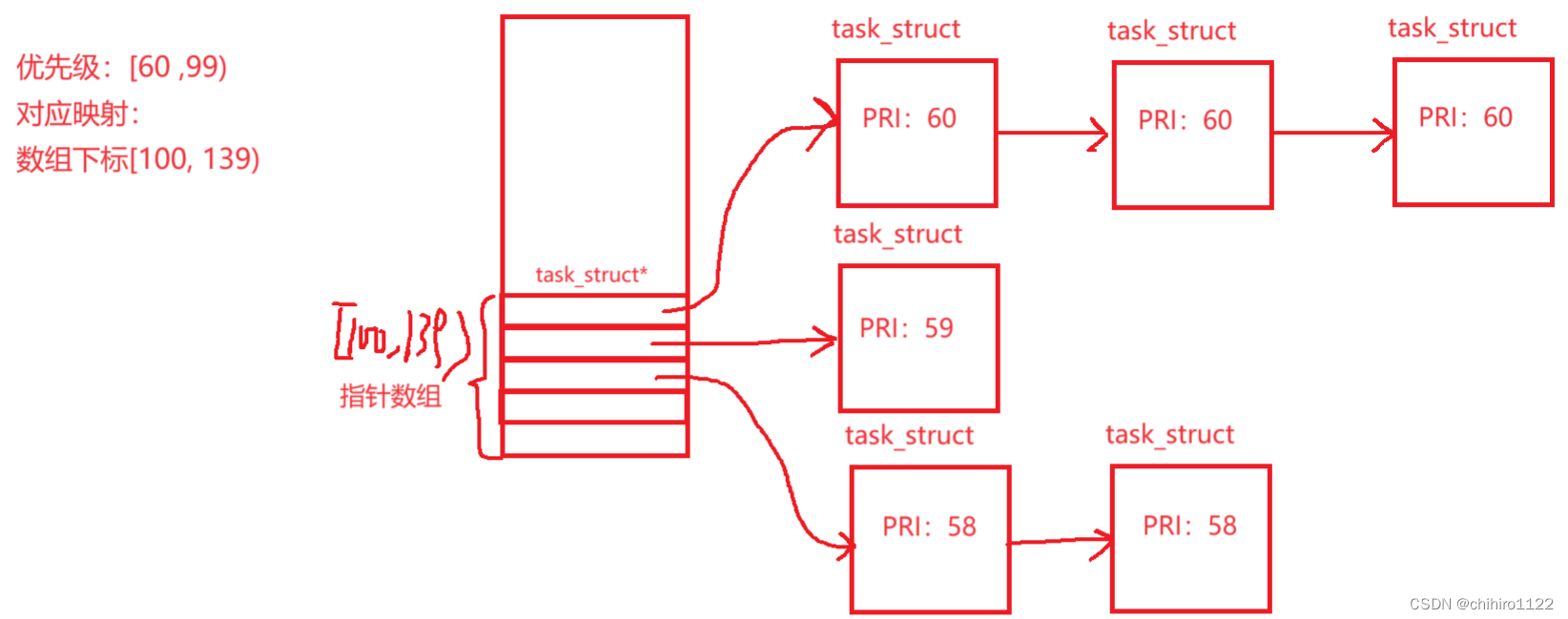
利用这种 类似于 开散列式的哈希表来 实现,这种结构非常像 哈希桶。
cpu只需要在左边的指针数组当中 按照下标来一个调用有这个 task_struct * 指向的单链表来依次调用其中的 进程。
如果后续需要添加进程,只需要按照 这个进程的 优先级,插入到对应的 指针数组 元素指向的 单链表尾插即可。
上述描述的是running 这个指针数组,当 运行队列当中只有 running 这个指针数组之时,那么就是按照上述的方式进行操作的。
但是,在LInux 当中还有一个 waiting 指针数组,在上述,我们说过,在后序插入的 进程,是直接在 running 维护的对应的单链表当中尾插的。但是现在有了 waiting指针数组,就不在 running 当中插入了,直接在 waiting 指针数组当中插入即可。这个 waiting 指针数组的存储结构 和 running 是一样的。
而且,不仅仅有上述两个 指针数组,还有两个 二级指针,指向这个两个数组。实际上,cpu 不是按照 running数组的首元素地址开始执行程序,而是按照 这个 指向 running数组的 二级指针来执行进程。当 running 当中的进程执行完之后,只需要 交换 指向 running数组 和 waiting数组 两个数组的 两个二级指针指向即可。就是把 两个二级指针指向的内存做交换。
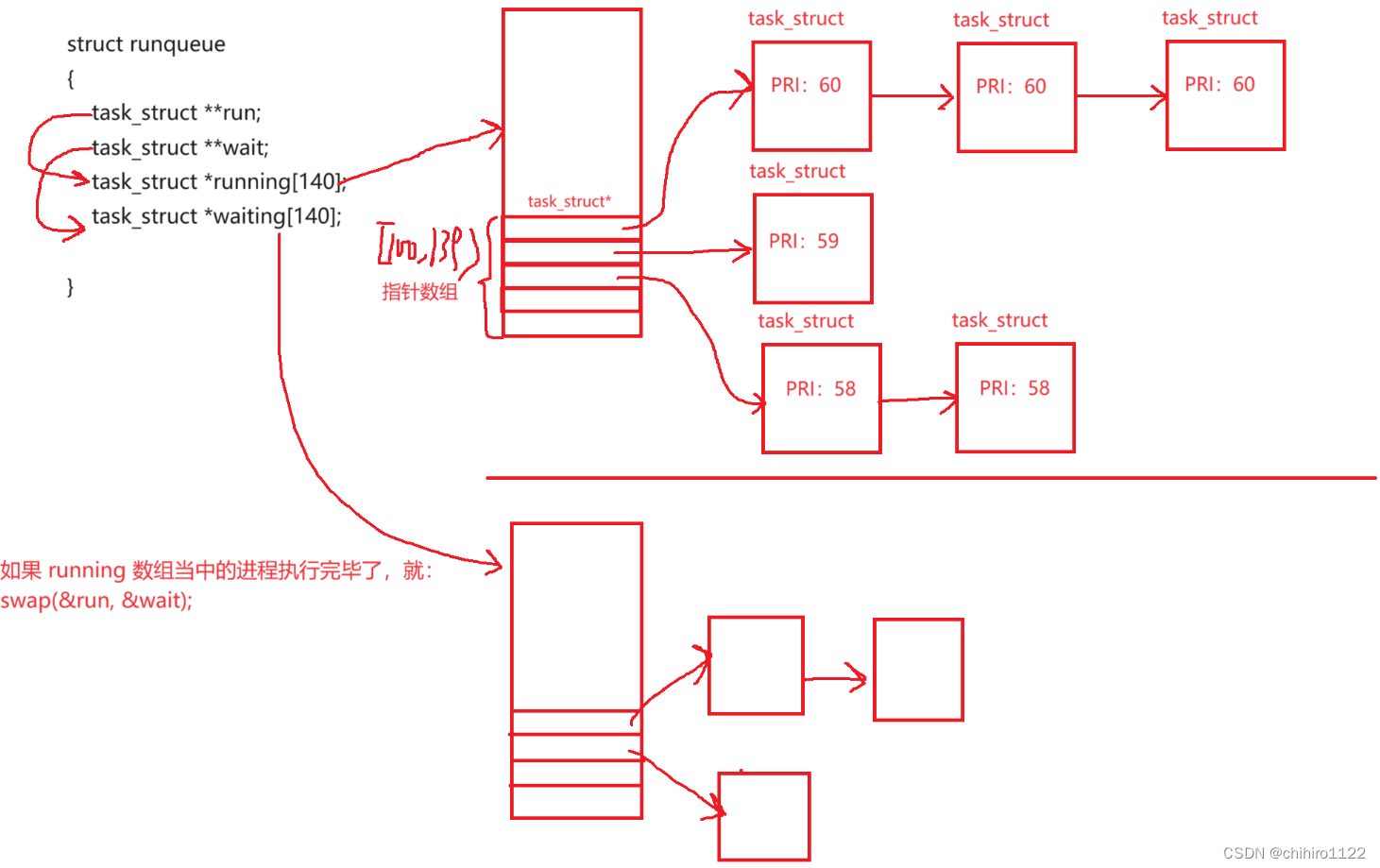
向上述所举的例子,run 这个二级指针,一定指向的是 正在执行的队列;而 wait 二级指针指向的是 还没有新插入的正在等待的队列。
但是,现在还有一问题,怎么知道 run 指向的队列已经执行完了呢?
就只能取遍历这个指针数组,各个指针元素是否指向空。
但是,这种方式有点满,所以,我们使用 位图 来映射 这个队列的每一个位置是否为空。使用 位图就可以 实现近乎 O(1)的时间复杂度来找到 从当前查找位置开始,最近一个 不为空的 单链表位置。
具体位图,可以看一下博客介绍:
C++ - 位图 - bitset 容器介绍_chihiro1122的博客-CSDN博客
这种使用位图来实现查找 最近的 队列不为空的算法,被称之为 --- Linux 内核 当中的 O(1)调度算法。
总结
我们所看到的 各种外设,硬件设备,进程试图访问,或者使用这些外设之时,都是要在各种队列当中进行排队的。因为 这些外设,硬件设备,是少量的,而进程动不动就几百个,是很多的,这也就导致了 进程之间要竞争,要排队。
所以,操作系统为了能更好的管理 进程 之间的运行,就引入了优先级,让进程之间合理竞争相关资源。因为 各个资源是不能做到并发执行的,但是因为 cpu 计算速度很快,可以用一些调度算法,结合优先级做到 用户看上去是很多进程在同时运行一样。
各种资源,在各个进程使用期间是 独享的,并不是多个进程占用同一资源。在多进程运行期间互不干扰。进程在设计理念之上,就是 在自己运行之上不能影响到 其他进程的运行,这样是进程的独立性。
如果在不考虑多核cpu的情况下,多个进程在多个CPU下分别,同时进行运行,这称之为并行
,这个称之为并行。
同时,如果此时只有一个 cpu ,在一段时间之内,很多个进程都得到的执行,或者实现完毕,这个过程称之为并发。
当然,为了防止某一个进程一直占用cpu,所以,一个进程还有一个时间片的概念,只允许一个进程在规定的时间之内占用时间片。
如果一个进程的时间片到了,那么这个进程就会排到下一个 等待队列当中,等到cpu处理下一轮的 进程队列。
这也是 Linux 在处理进程队列这件事情之上的 优雅处理。使得后序链入的进程,只能在当前cpu正在执行 的运行队列当中的进程全部执行完,才会执行下一个队列当中的进程,而在cpu 处理当前队列的 进程之时,在此期间链接上来的 进程,只能链接到 等待队列当中。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











