







最近想对C++的面试题目进行一下更加具体的整理。其实认真思考一下C++程序员的面试,我们可以发现对程序员的能力的考察总是万变不离其中,这些基础知识主要分为五部分:一、 C/C++基础知识 二、 C/C++的一些特性,如面向对象,内存管理 三、 基础的数据结构编程的知识。 四、stl的一些基础知识。五、网络编程、多线程的知识、异常处理基础知识
本文试图覆盖C/C++面试的每一个知识点,所以对每个知识点介绍的并不深入。本文适合已经对一下具体知识有所了解的人,我对每个点都有粗略的讲解,如果想深入理解请阅读相关具体知识。
一、 C/C++的基础知识:包括指针、字符串处理、内存管理。
二、面向对象基础知识:包括多态、继承、封装。 多态的实现方式?多态的好处?
三、基础的数据结构面试:数组、链表、字符串操作、二叉树。这里要说的话就说的很多了,具体的有使用一些数据结构包括stl list, vector, map, hashmap, set。
四、stl的一些基础知识。
五、网络编程、多线程和异常处理的基础知识。
六、C++ 语言新特性。
七、其他计算机基础。
一、C/C++基础知识:
1. C/C++内存管理:C/C++的内存分为:堆、栈、自由数据区、静态数据区和常量数据区。
栈: 函数执行时,函数内部的局部变量在栈上创建,函数执行结束栈的存储空间被自动释放。
堆:就是那些new分配的内存块,需要程序员调用delete释放掉。
自由数据区:就是那些调用malloc的内存块,需要程序员调用free释放掉。(据说这个就是bullshit)
全局存储区:全局变量和静态变量被存放到同一块存储区域。
静态存储区:这里存放常量,不允许修改。
堆和栈的区别:a. 管理方式不同:堆需要程序员手动维护。 b. 栈的存储空间远小于堆。堆几乎不受限制。 c. 生长方式不同。栈是从高地址空间向低地址空间生长,堆是从低地址空间向高地址空间生长。 d. 效率不同:栈要远快于堆。
new和delete的区别:new和delete是C++的函数会调用,构造函数和析构函数。而malloc和delete只是分配对应的存储空间。
注意问题: 1. 意外处理:内存申请失败处理。2. 内存泄漏:申请的地址空间一定要释放。 3. 野指针:避免指针未赋值使用,一定要初始化。
给出一个图吧,关于内存空间的分配的:
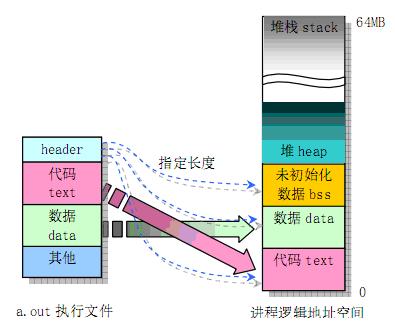
左边的是UNIX/LINUX系统的执行文件,右边是对应进程逻辑地址空间的划分情况。
2. 小端存储和大端存储:
小段:高位存在高地址上;大端:低位存在高地址上。
判定代码:
unsigned short test = 0x1234;
if( *(unsigned char *)&test=0x12 )//
return Big_Edian;//高位在低地址空间 大端存储
3. C++的指针使用:
a. 指针数组 与 数组指针: 注意[]的结合优先级比*要高。那么int *p[3];我们就得到了一个数组,数组的每个元素是int *的。而int (*p)[3];//我们就得到了一个指针,指向的是一个长度为3的一维数组。
b. 函数指针:例如对函数:int funcA(int a,int b); 我们可以定义一个指针指向这个函数:int (*func)(int,int); func=funcA; 函数指针可以用来实现多态和传入回调函数。
c. ptr++; 指针ptr的值加上了sizeof(ptr);
d. 谨记指针用完了一定是要回收的。
4. 运算符优先级:
a. 比较常考的就是 ++和--与*、&、.的优先级对比:注意正确的优先级是:. > ++ > -- > * > &
5. 二维数组的动态申请:
int **a=new int *[10];
for(i=0;i<10;i++)
a[i]=new int[10];
6. extern "C"声明的作用:
C++中引用C语言的函数和变量需要使用extern "C"来进行修饰。因为C++为了支持多态,函数和变量命名的方式和C不同,因此如果一个模块的函数和变量需要被其他模块使用,就需要使用extern "C"来修饰。该修饰制定编译器变量和函数是按照C语言方式进行链接的。
7. 指针和引用的区别,指针和数组的区别,const与define的区别:
指针和引用的区别:引用可以看作是变量的别名,不可以指向其他的地址,不能为空。
指针和数组的区别:指针可以指向其他地址,使用sizeof计算时两者的结果不同。
const与指针的区别:const定义的变量有类型,而define只是编译器的简单替换。
7.1 const 分类
a. const 修饰变量
b. const 修饰函数
c. const 修饰类
8. 如何判定程序是由C/C++编译器编译出来的?
#ifdef __cplusplus
#else
#endif
9. const的作用,static的作用。
a. const 指定变量不可修改。
b. static 指定变量存在静态数据区,并且只初始化一次。
10. 变量字节对齐:为了加快内存寻址的效率,在C++内存管理时一般选取的是4字节对齐。如下变量占用8个字节:
struct Node{
int a,
char b
};
11. const与指针:
char * const p; //指针不可改
char const *p; //指针指向的对象不可修改
12. 操作符重载:
C/C++ 里大多数运算符都可以在 C++ 中被重载。C 的运算符中只有 . 和 ?:(以及sizeof,技术上可以看作一个运算符)不可以被重载。C++ 增加了一些自己的运算符,除了 :: 和 .* 外,大多数都可以被重载。
a. 单目操作符:
Point &Point:: operator++();//++a;
Point &Point:: operator++(int);//a++
b. 双目操作符:
Point &Point:: operator+=(Point b)// +=
源代码如下:
class Point{
public:
int x;
int y;
public:
void Print(){
cout<<"x="<<this->x<<endl;
cout<<"y="<<this->y<<endl;
}
Point(){
x=0;
y=0;
}
Point(const Point &a){
x=a.x;
y=a.y;
}
Point(int x,int y){
this->x=x;
this->y=y;
}
Point& operator+=(Point b);
Point& operator++();
Point& operator++(int);
};
Point& Point::operator+=(Point b){
x += b.x;
y += b.y;
return *this;
}
Point& Point::operator++(){
this->x++;
this->y++;
return *this;
}
Point& Point::operator++(int){
Point a(*this);
this->x++;
this->y++;
return a;
}
int main(){
Point *a=new Point(1,2);
Point *b=new Point(3,4);
Point c(10,20);
*a+=c;
a->Print();
++c;
c.Print();
c++;
c.Print();
return 0;
}
13. 函数调用传值与传引用
传值不会修改传入参数的值,而传引用会修改传入参数的值。
14. volatile与C/C++的四种cast函数:
volatile修饰的变量,编译器不会做优化,每次都是到内存中去读取或者写入修改。C++有四种cast函数:static_cast,dynamic_cast,const_cast,volatile_cast。
15. C++ 类的实例化如果没有参数是不需要括号的,否者就是调用函数并且返回对应的对象,例如如下代码就会报错:
struct Test
{
Test(int ) { }
Test() { }
void fun() { }
};
int main(void)
{
Test a(1);
a.fun();
Test b;
b.fun();
return 0;
}15. C++ 里面的const修饰函数时,标志该函数不会修改this指针的内容。而且const不能修饰非类内部的函数。
16. const可以重载,这是基于编译器编译时对函数进行重命名实现的。例如f( int a), f(const int a)是两个不同的函数了。
17. override(覆盖), overload(重载), polymorphism(多态)
18. const char* a, char const*, char*const的区别: const char * pa;//一个指向const类型的指针,char * const pc;//const修饰的指针
19. typename和class的区别:在模版中使用时,class与typename可以替换。在嵌套依赖类型中,可以声明typename后面的字符串为类型名,而不是变量。例如:
class MyArray //暂时还不是很懂,就先睡觉了。
{
public:
typedef int LengthType;
.....
}
template<class T>
void MyMethod( T myarr )
{
typedef typename T::LengthType LengthType;
LengthType length = myarr.GetLength;
}二、面向对象和C++特性描述:
1. 面向对象三个基本特征:继承、多态和封装。
2. 多态:多态是面向对象继承和封装的第三个重要特征,它在运行时通过派生类和虚函数来实现,基类和派生类使用同样的函数名,完成不同的操作和实现相隔离的另一类接口。多态提高了代码的隐藏细节实现了代码复用。
3. 什么是纯虚函数和纯虚类:有些情况下基类不能对虚函数有效的实现,我们可以把它声明为纯虚函数。此时基类也无法生成对象。
4. 什么是虚函数:虚函数是类内部使用virtual修饰的,访问权限是public的,并且非静态成员函数。虚函数是为了实现动态连接,定义了虚函数以后对基类和派生类的虚函数以同样形式定义,当程序发现virtual虚函数以后会自动的将其作为动态链接来处理。纯虚函数在继承类实现时,需要全部实现。
如public virtual function f()=0;
注:下列函数不能被声明为虚函数:普通函数(非成员函数);静态成员函数;内联成员函数;构造函数;友元函数。
5. 运行时绑定和虚函数表:
动态绑定:绑定的对象是动态类型,其特性依赖于对象的动态特性。
虚函数表: C++的多态是通过动态绑定和虚函数表来实现的。这是虚函数的地址表,存储着函数在内存的地址。一般类的对象实例地址就是虚函数表。有虚函数覆盖时,虚函数的地址存储的是被覆盖的子类的函数的地址。
其实知道虚函数表了,我们就可以通过操作指针的方式访问一些额外的数据(当然如果直接写成代码会编译不通过的)。对于基类指针指向派生类时:我们可以通过内存访问派生类未覆盖基类的函数,访问基类的非public函数。
6. 空类的大小不是零:因为为了确保两个实例在内存中的地址空间不同。
如下,A的大小为1,B因为有虚函数表的大小为4.
class A{};
class B:public virtual A{};
多重继承的大小也是1,如下:
class Father1{}; class Father2{};
class Child:Father1, Father2{};
7. 深拷贝与浅拷贝:
C++会有一个默认的拷贝构造函数,将某类的变量全部赋值到新的类中。可是这种情况有两个例外:(1). 类的默认构造函数做了一些额外的事情,比如使用静态数据统计类被初始化的次数(此时浅拷贝也无法解决问题,需要额外的修改拷贝构造函数)。 (2). 类内部有动态成员:此时发生拷贝时就需要对类内部的动态成员重新申请内存空间,然后将动态变量的值拷贝过来。
8. 只要在基类中使用了virtual关键字,那么派生类中无论是否添加virtual,都可以实现多态。
9. 虚拟析构函数:在使用基类指针指向派生类时,如果没有定义虚拟析构函数那么派生类的析构函数不会被调用,动态数据也不会被释放。
构造函数和析构函数的调用顺序为:先基类构造函数,再派生类构造函数。析构时,先派生类析构函数,再基类析构函数。
10. public,protected, private权限:privated:类成员函数、友元函数。 protected:派生类、类成员函数、友元函数,public所有
11. 可重入函数(多线程安全),即该函数可以被中断,就意味着它除了自己栈上的变量以外不依赖任何环境。
12. 操作系统内存管理有堆式管理、页式管理、段式管理和段页式管理。堆式管理把内存分为一大块一大块的,所需程序片段不在主村时就分配一块主存程序,把程序片段load入主存。页式管理:把主页分为一页一页的,每一页的空间都比块小很多。段式管理:把主存分为一段一段的,每一段的空间比一页一页的空间小很多。段页式管理。
13. C++四种CAST操作符:
C/C++的强制转换风格如下: (T) expression或 T(expression) 函数风格。C++定义了四种转换符: reinterpret_cast、static_cast、dynamic_cast和const_cast,目的在于控制类之间的类型转换。
reinterpreter_cast <type-id> (expression) 能够实现非相关类型之间的转换,但只是复制原的数据到目的地址,可能包含无用值,且不可移植。如: double d=reinterpret_cast<double &>(n);
const_cast<type-id> expression: 修改const或volatile属性。消除对象的常量属性。
static_cast<type-id> expression: 父子类之间转换、空指针->目标指针、任何类型转化为void类型、任意类型转换。
dynamic_cast<type-id> expression: 是唯一不能用旧风格执行的强制转换。用于多态类型的任意隐式类型转换及相反的过程。基类指针转化为派生类时,基类需要有虚函数(否则编译报错)。相对于static_cast,增加了安全检验。
//结论:父指针指向子对象地址,不用强转,即可。
//基类没有虚函数时,只有static_cast可以编译通过。基类有虚函数时dynamic_cast也可以编译通过。
class Base
{
public:
Base(){a1=1;}
virtual void test(){}
int a1;
};
class Derive:public Base
{
public:
Derive(){a2=2;}
int a2;
};
int main(int argc, char *argv[])
{
Base *pb;
Derive *pd;
Base b;
Derive d;
cout <<"&b:"<<&b<<endl;
cout<<"&d:"<<&d<<endl;
pb=&d;
cout<<__LINE__<<"pb:"<<pb<<endl;
pb=static_cast<Base*>(&d);
cout<<__LINE__<<"pb:"<<pb<<endl;
pb=dynamic_cast<Base*>(&d);
cout<<__LINE__<<"pb:"<<pb<<endl;
//pd=&b;//error
//cout<<__LINE__<<"pd:"<<pd<<endl;
pd=static_cast<Derive*>(&b);
cout<<__LINE__<<"pd:"<<pd<<endl;
pd=dynamic_cast<Derive*>(&b);//error
cout<<__LINE__<<"pd:"<<pd<<endl;
return 0;
}14. shared_ptr是一个包含引用计数的智能指针。它的引用计数是安全且无锁的,但内存对象的读写不是,因为shared_ptr有两个数据成员,读写操作不能原子化。shared_ptr的线程安全级别和内建类型、标准库容器、string一样。shared_ptr实体可以被两个线程同时写入。如果要从多个线程同时读写一个shared_ptr对象,那么需要加锁。使用示例如下:
#include "boost/shared_ptr.hpp"
#include <cassert>
#include <stdlib.h>
#include <iostream>
#include "boost/make_shared.hpp"
using namespace std;
class shared //一个拥有shared_ptr的类
{
private:
boost::shared_ptr<int> p; //shared_ptr成员变量
public:
shared(boost::shared_ptr<int> p_):p(p_){} //构造函数初始化shared_ptr
void print() //输出shared_ptr的引用计数和指向的值
{
cout << "count:" << p.use_count() << " v=" <<*p << endl;
}
};
void print_func(boost::shared_ptr<int> p) //使用shared_ptr作为函数参数
{
//同样输出shared_ptr的引用计数和指向的值
cout << "count:" << p.use_count() << " v=" <<*p << endl;
}
void f()
{
typedef vector<boost::shared_ptr<int> > vs; //一个持有shared_ptr的标准容器类型
vs v(10); //声明一个拥有10个元素的容器,元素被初始化为空指针
int i = 0;
for (vs::iterator pos = v.begin(); pos != v.end(); ++pos)
{
(*pos) = boost::make_shared<int>(++i); //使用工厂函数赋值
cout << *(*pos) << ", "; //输出值
}
cout << endl;
boost::shared_ptr<int> p = v[9];
*p = 100;
cout << *v[9] << endl;
}
int main()
{
boost::shared_ptr<int> p(new int(100));
shared s1(p);
s1.print();
shared s2(p); //构造两个自定义类
s1.print();
s2.print();
*p = 20; //修改shared_ptr所指的值
print_func(p);
s1.print();
f();
}
//对应于shared_ptr的是<span style="font-family: Arial, Helvetica, sans-serif;">static_pointer_cast 和 dynamic_pointer_cast,它的用法和static_cast、dynamic_cast很像。</span> 14. 构造函数初始化列表和构造函数初始化的区别:
a. 初始化列表可以初始化const变量,编译时处理。
b. 初始化列表的变量初始化顺序为变量声明顺序。
c. 可以用默认构造函数,构造函数不需要那么多参数。。。
15. 友元函数
a. 实现类之间的数据共享,减少系统开销,提高效率。应用场景:1). 运算符重载需要 2). 两个类共享数据
注意点: 友元函数不能被继承,友元函数没有this指针
三、基础的数据结构编程知识:
| 排序法 | 平均时间 | 最差情形 | 稳定度 | 额外空间 | 备注 |
| 冒泡 | O(n2) | O(n2) | 稳定 | O(1) | n小时较好 |
| 交换 | O(n2) | O(n2) | 不稳定 | O(1) | n小时较好 |
| 选择 | O(n2) | O(n2) | 不稳定 | O(1) | n小时较好 |
| 插入 | O(n2) | O(n2) | 稳定 | O(1) | 大部分已排序时较好 |
| 基数 | O(logRB) | O(logRB) | 稳定 | O(n) | B是真数(0-9), R是基数(个十百) |
| Shell | O(nlogn) | O(ns) 1<s<2 | 不稳定 | O(1) | s是所选分组 |
| 快速 | O(nlogn) | O(n2) | 不稳定 | O(nlogn) | n大时较好 |
| 归并 | O(nlogn) | O(nlogn) | 稳定 | O(1) | n大时较好 |
| 堆 | O(nlogn) | O(nlogn) | 不稳定 | O(1) | n大时较好 |
int partition(int a[],int low,int high){
int data=a[low],tem;
int i=low+1,j=low+1;
while(j<=high){
if(a[j]>data)
j++;
else{
tem=a[i];
a[i]=a[j];
a[j]=tem;
i++;
j++;
}
}
a[low]=a[i-1];
a[i-1]=data;
return i-1;
}
void qsort1(int a[],int low,int high){
if(low>=high)
return;
int mid=partition(a,low,high);
if(mid-1>low)
qsort1(a,low,mid-1);
if(high>mid+1)
qsort1(a,mid+1,high);
}void HeapModify(int a[], int i, int length){
int j=-1;
if( i*2+1 < length ){
if( a[i*2+1]>a[i]){
j=i*2+1;
}
}
if( i*2 +2 < length){
if( a[i*2 +2] > a[i] && a[2*i+2] > a[2*i+1]){
j=i*2+2;
}
}
if( j> 0){
int tem;
tem=a[i];
a[i]=a[j];
a[j]=tem;
HeapModify(a,j,length);
}
}
void Heap_sort(int a[],int length){
int i,tem;
for(i=length/2;i>=0;i--){
HeapModify(a,i,length);
}
for(i=0;i<length-1;i++){
tem=a[0];
a[0]=a[length-1-i];
a[length-1-i]=tem;
HeapModify(a,0,length-i-1);
}
}c ) 最大子数组求和:
int Max_Sum(const int a[],const int length_a){
int length,i,max1=0;
int *b=new int[10];
max1=b[0]=a[0];
for(i=1;i<length_a;i++){
b[i]=max(b[i-1]+a[i],a[i]);
if(b[i]>max1){
max1=b[i];
}
}
return max1;
}int atoi1(char *str){
assert(str!=NULL);
int result=0,pos=1;
if(*str=='-'){
pos=-1;
str++;
}
while(*str!='\0'){
assert(*str<='9'&&*str>='0');
result=result*10+*str-'0';
str++;
}
return result*pos;
}char *itoa1(int num,int k){
char data[]="0123456789ABCDEF";
bool pos=true;
int count=1,tem;
int num1=num;
if(num<0){
num=-num;
pos=false;
count++;
}
while(num>0){
num=num/k;
count=count+1;
}
char *result=new char[count];
char *presult=result,*pstr;
if(pos==false){
*presult++='-';
}
pstr=presult;
while(num1>0){
*presult++=data[num1%k];
num1=num1/k;
}
*presult--='\0';
while(pstr<presult){
tem=*pstr;
*pstr=*presult;
*presult=tem;
*presult--;
*pstr++;
}
return result;
}char * Replace_Str(char * str, char * target){
assert(str!=NULL&&target!=NULL);
char *pstr=str;
int count=0;
while(*pstr!='\0'){
if(*pstr==' '){
count++;
} pstr++;
}
char * result=new char[sizeof(str)+count*strlen(target)];
char *presult=result;
for(pstr=str;pstr!='\0';pstr++){
if(*pstr!=' '){
*presult=*pstr;
}
else{
char *ptarget=target;
while(*ptarget!='\0'){
*presult++=*ptarget++;
}
}
}
*presult='\0';
return result;
}void strcpy1(char * source, char * dest){
assert(source!=NULL&&dest!=NULL);
char * psource=source, *pdest=dest;
while(*psource!='\0'){
*pdest++=*psource++;
}
*pdest='\0';
}<span style="font-size:14px;">int Find_Str(const char* source,const char* target){ //查找目的串在源串中出现的位置,最弱的方法
assert(source!=NULL&&target!=NULL);
int i,j,i1;
int len_source=strlen(source),len_target=strlen(target);
for(i=0;i<len_source;i++){
i1=i;
for(j=0;source[i1]==target[j]&&j<len_target;i1++,j++);
if(j==len_target)
return i;
}
return -1;
}</span>void *memcpy1(void * dest, const void * source, size_t num){//注意需要考虑内存重叠的部分,特别的dest在source数据区间内部时候的处理
assert(dest!=NULL&&source!=NULL);
int i;
byte *psource=(byte *) source;
byte *pdest=(byte *) dest;
if(pdest>psource&&pdest<psource+num){
for(i=num-1;i>=0;i--)
*(pdest+i)=*(psource+i);
}else{
for(i=0;i<=num;i++)
*(pdest+i)=*(psource+i);
}
return dest;
}3) 链表处理:
a). 链表相交判定:
void Pre_Traverse_Recur(NODE *root){//前序递归
if(root==NULL)
return;
cout<<root->data;
Pre_Traverse_Recur(root->left);
Pre_Traverse_Recur(root->right);
}
void Pre_Traverse(NODE *root){<span style="font-family: Arial, Helvetica, sans-serif;">//前序非递归</span>
stack<NODE*> stack1;
NODE *p=root;
while(p!=NULL||!stack1.empty()){
while(p!=NULL){
cout<<p->data;
stack1.push(p);
p=p->left;
}
if(!stack1.empty()){
p=stack1.top();
stack1.pop();
p=p->right;
}
}
}void Inorder_Traverse_Recur(NODE *root){//中序递归
if(root==NULL)
return;
Pre_Traverse_Recur(root->left);
cout<<root->data;
Pre_Traverse_Recur(root->right);
}
void Inorder_Traverse(NODE *root){<span style="font-family: Arial, Helvetica, sans-serif;">//中序非递归</span>
stack <NODE*> stack1;
NODE *p=root;
while(p!=NULL||!stack1.empty()){
while(p!=NULL){
stack1.push(p);
p=p->left;
}
if(!stack1.empty()){
p=stack1.top();
cout<<p->data;
stack1.pop();
p=p->right;
}
}
}void Postorder_Traverse_Recur(NODE *root){//后序递归
if(root==NULL)
return;
Postorder_Traverse_Recur(root->left);
Postorder_Traverse_Recur(root->right);
cout<<root->data;
}
#include <hash_map>
using namespace std;
using namespace __gnu_cxx;
void Postorder_Traverse(NODE *root){//非递归后序遍历
stack <NODE *> stack1;
hash_map <int,int> hashmap1;
assert(root!=NULL);
NODE *p=root;
while(p!=NULL){
stack1.push(p);
p=p->left;
hashmap1[stack1.size()]=0;
}
while(!stack1.empty()){
p=stack1.top();
while(p->right&&hashmap1[stack1.size()]==0){
hashmap1[stack1.size()]=1;
p=p->right;
while(p!=NULL){
stack1.push(p);
hashmap1[stack1.size()]=0;
p=p->left;
}
p=stack1.top();
}
p=stack1.top();
cout<<p->data;
stack1.pop();
}
}
list<int> lst1;
list<int>::iterator itor;
lst1.push_front(1);
lst1.push_back(2);
int i=lst1.front();
list1.size();
list1.empty(); stack<int> stack1;
stack1.push(10);
int i=stack1.top();
stack1.pop();
stack1.size();
stack1.empty(); vector<int> v;
vector<int> ::iterator itor;
for(int i=0;i<10;i++){
v.push_back(i);
}
itor=v.begin();
v.insert(itor,55);
v.erase(itor);
for(itor=v.begin();itor!=v.end();itor++){
cout<<*itor<<endl;
}
vector<int>::iterator findit = find(v.begin(),v.end(),123);
if(findit==v.end())
cout<<"Not exist!!"<<endl; map <int,int> map1;
map1[5]=5;
map1.insert(pair<int,int>(7,7));
map1.insert(pair<int,int>(1,1));
map <int,int> ::iterator itor;
for(itor=map1.begin();itor!=map1.end();itor++)
cout<<itor->first<<itor->second<<endl;
itor=map1.find(5);
if(itor!=map1.end())
cout<<"Exists"<<endl;
map1.size();
map1.empty(); (1). TIME_WAIT 为两个MSL的时间,因为a. 为了保证客户端发送的最后一个ACK能够到达服务器。b.防止已经失效的连接请求报文段出现在本连接中。 (2). FLOOD流攻击使用了TCP三次握手的协议的漏洞。客户端伪造了多个IP发送syn请求。
(1). TIME_WAIT 为两个MSL的时间,因为a. 为了保证客户端发送的最后一个ACK能够到达服务器。b.防止已经失效的连接请求报文段出现在本连接中。 (2). FLOOD流攻击使用了TCP三次握手的协议的漏洞。客户端伪造了多个IP发送syn请求。

class Singleton{ private: static Singleton *_instance; Singleton(){ } public: static Singleton * Instance(){ if(0==_instance) _instance=new Singleton; return _instance; }return _instance; }};Singleton* Singleton::_instance = 0;int main(){ Singleton *sg = Singleton::Instance(); return 0;}public static synchronized Singleton * Get_Instance(){
12. SQL注入:
SQL Injection:通过把SQL命令插入到Web表单提交或输入域名或页面请求查询字符串,最终打到欺骗服务器执行恶意SQL的命令。
防止SQL注入有一下几点:
b. 左连接、右连接、内连接、外连接
c. 乐观锁、悲观锁
7. 数据库存储过程介绍: http://blog.sina.com.cn/s/blog_76b2c4810101b8qz.html
8. C++ 11的新特性--- auto的使用: http://blog.csdn.net/huang_xw/article/details/8760403
9. boost总结汇总: http://blog.csdn.net/huang_xw/article/details/8758212















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









