









 本文介绍了一种技巧,如何通过在Ubuntu系统下利用Firefox浏览器、LibreOfficeDraw和OCR软件如AbbyyFineReader,通过打印网页然后转换为PDF来获取被平台限制的付费文档。操作包括调整打印比例、删除无关元素并进行OCR识别。
本文介绍了一种技巧,如何通过在Ubuntu系统下利用Firefox浏览器、LibreOfficeDraw和OCR软件如AbbyyFineReader,通过打印网页然后转换为PDF来获取被平台限制的付费文档。操作包括调整打印比例、删除无关元素并进行OCR识别。
1.使用需求
平时我们经常需要查询搜索一些文档资料,往往会遇到查到的文档资料被各大平台无耻地设置为付费下载,而且一般会禁用从页面上复制的功能。扫描版的文档本身就是图片,无法将文字复制出来,文字版的也会受到限制,只能浏览不能复制下载。
如果这些文档资料是平台自身生产的也就罢了,付费也是应该的,但大多数平台采取的是让用户上传资料,付费方可下载,费用由上传者和平台按比例分成的模式。对于用户原创的资料付费使用也无可厚非。问题是基本上平台用的也都是上传者搬运的资料,比如国家标准规范之类的。这就有点过分了。
于是乎摸索了一个免费获取文档资料的小技巧,与大家分享一下。
2.软件准备
- unbuntu系统
- 浏览器(如firefox等)
- LibreOffice Draw
- Abbyy FineReader (Ocr文字识别软件,windows系统下)
3.操作步骤
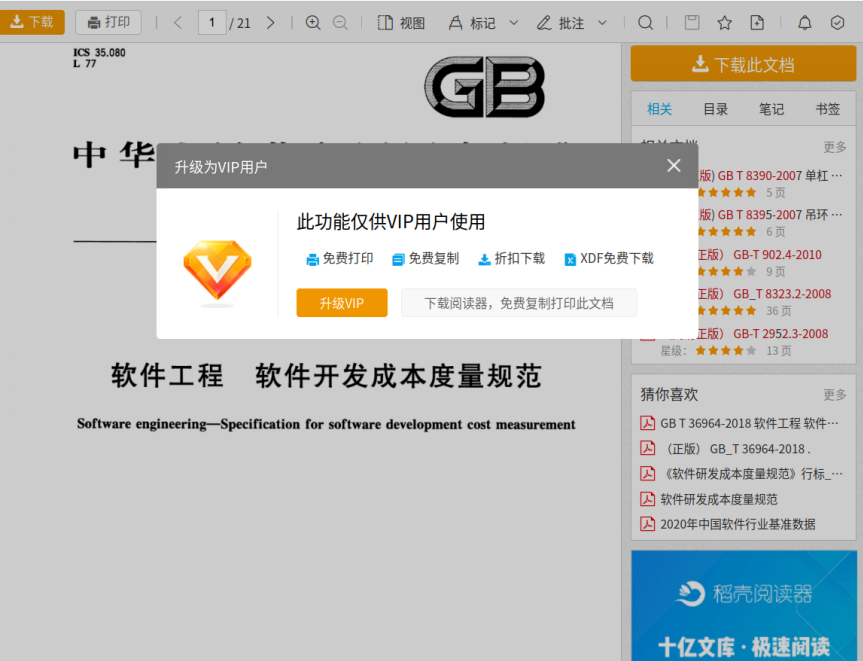
比如我们要查找一个规范《GB∕T 36964-2018 软件工程 软件开发成本度量规范》,百度一下发现各大平台都有,而且都要付费下载。从其中找到一个不必付费就可以全文预览的,打开。
点击页面左上角的“下载”会提示付费方可下载,左上角的“打印”则提示仅供VIP用户使用。
|
|
在打印预览窗口查看调整页面缩放比例,默认比例下,会将网页上的全部可见元素都打印出来,如链接、按钮、广告……等。
如果当前页面按70%的缩放比例打印出来,每一页的右侧都会出现页面1/4到1/3左右的边栏内容,链接、广告或空白,正文部分被缩得比较小。

适当调整缩放比例到95%,可以看到右侧的边栏被挤出了页面之外,正文所占比例基本达到正常水平。只是会有一些页面下方的链接等元素被挤到了下一页独占一页,总页数由22页变成了30页。不过没有关系,后续删除掉即可。

文件保存之后,使用Ubuntu自带的LibreOffice Draw打开。我用Ubuntu系统的目的也仅仅是为了用这个软件。目前已经支持Windows,只不过我的windows系统下没有安装,所以还是在Ubuntu下进行编辑。
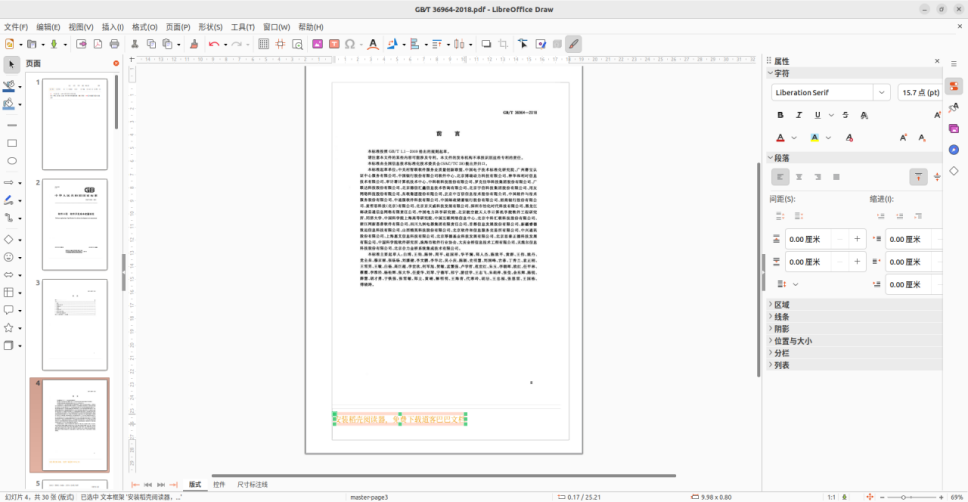
打开pdf文件之后可以看到,我们关心的文档正文部分由于原稿是扫描版,在pdf中也是以图片形式嵌入在文档页面上的。其他从网页上带来的元素,都是以文本框、图片、图形、线条等方式呈现的,可以使用鼠标逐一进行选中、删除。这些元素可以理解为网页上的各种可见和不可见的图层和样式。比如下图中左侧缩略图最上面一页就是网页上的超链接等文本信息,没有正文,可以直接右键->删除。后面类似的无用页面都可以直接删除。
其他pdf编辑软件可能也能进行类似元素控件的选择和删除。但如果网页上有控件的上下层叠加遮挡,比如水印图片、浮动广告图片等,很多软件就不好处理了,即使处理过之后,被遮挡的文字内容也会缺失。而Draw这个软件就可以直接删除上层遮挡元素,保留下层的正文。

页面下方的文本框、页面线框等元素,也可以使用鼠标框选删除。
个人经验是:把正文图片稍微移开一点,用鼠标可以点选到的元素都可以删掉,再把正文图片对其页面即可。此处在页面无效元素都删除之后,把正文图片放大到充满页面的大小,因为扫描的原件中正文已经让出了页边距,在嵌入网页时又被让出了一次页边距,所以此时可以把图片充满页面,不必考虑页边距的问题。
下面是调整之后的效果。

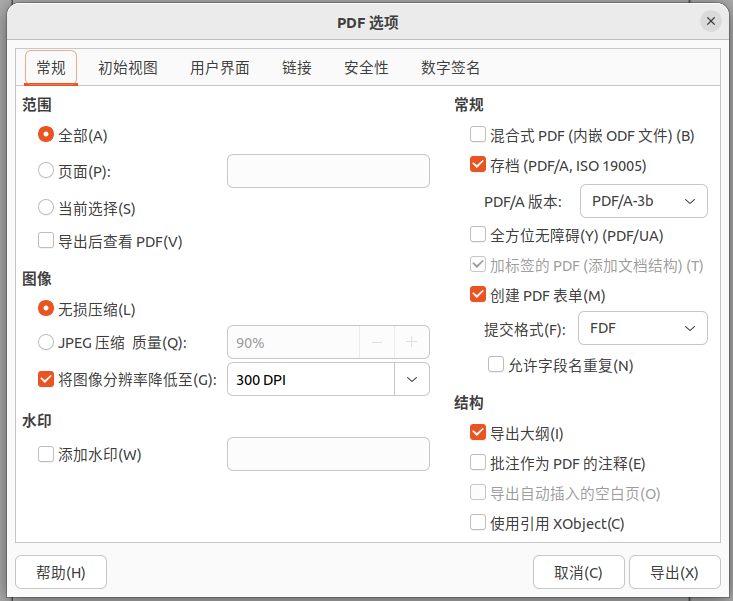
都调整好之后使用“导出为pdf”将文件导出。此时一个完美的扫描版就产生了。
为了使用文档中的内容,还需要将扫描版pdf用OCR识别软件转换为文字版。这就是常规操作了,很多软件都可以实现,本人感觉效果最好的是Abbyy FineReader。这个软件好像是没有Ubuntu版,只好回到Windows下进行处理。(下次我要在windows下安装LibreOffice Draw了,不再费事切换系统了)
查到一篇介绍在Ubuntu下进行OCR识别的软件,下次也要试试,如果好用,也就不用切换回windows了。文章地址:https://www.cnblogs.com/usmile/p/14846701.html
原本想切换到windows把OCR的步骤补上,可惜我的软件试用期过了,一时没找到河蟹码,不过操作很简单。大家可以找个河蟹版试一下。
方法你学废了吗?如果有帮助欢迎点赞、评论或关注。
#点赞富三代,分享美一生#

















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









