







可以先参考这里:https://blog.csdn.net/wyqwilliam/article/details/84024182
接下来以组合搜索时使用should条件来做演示。
数据准备如下:
创建索引:
PUT http://127.0.0.1:9200/mytest/
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"person": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"mail": {
"type": "keyword"
},
"hobby": {
"type": "text",
"analyzer":"ik_max_word"
}
}
}
}
}
添加文档:
POST http://127.0.0.1:9200/mytest/_bulk
{"index":{"_index":"mytest","_type":"person"}}
{"name":"张三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"mytest","_type":"person"}}
{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、篮球"}
{"index":{"_index":"mytest","_type":"person"}}
{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、篮球、游泳、听音乐"}
{"index":{"_index":"mytest","_type":"person"}}
{"name":"赵六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳、篮球"}
{"index":{"_index":"mytest","_type":"person"}}
{"name":"孙七","age": 24,"mail": "555@qq.com","hobby":"听音乐、看电影、羽毛球"}
搜索查询如下:
POST /mytest/person/_search
{
"query": {
"bool": {
"must": {
"match": {
"hobby": "篮球"
}
},
"must_not": {
"match": {
"hobby": "音乐"
}
},
"should": [
{
"match": {
"hobby": "游泳"
}
}
]
}
},
"highlight": {
"fields": {
"hobby": { }
}
}
}
上面搜索的意思是:
搜索结果中必须包含篮球,不能包含音乐,如果包含了游泳,那么它的相似度更高。
结果:
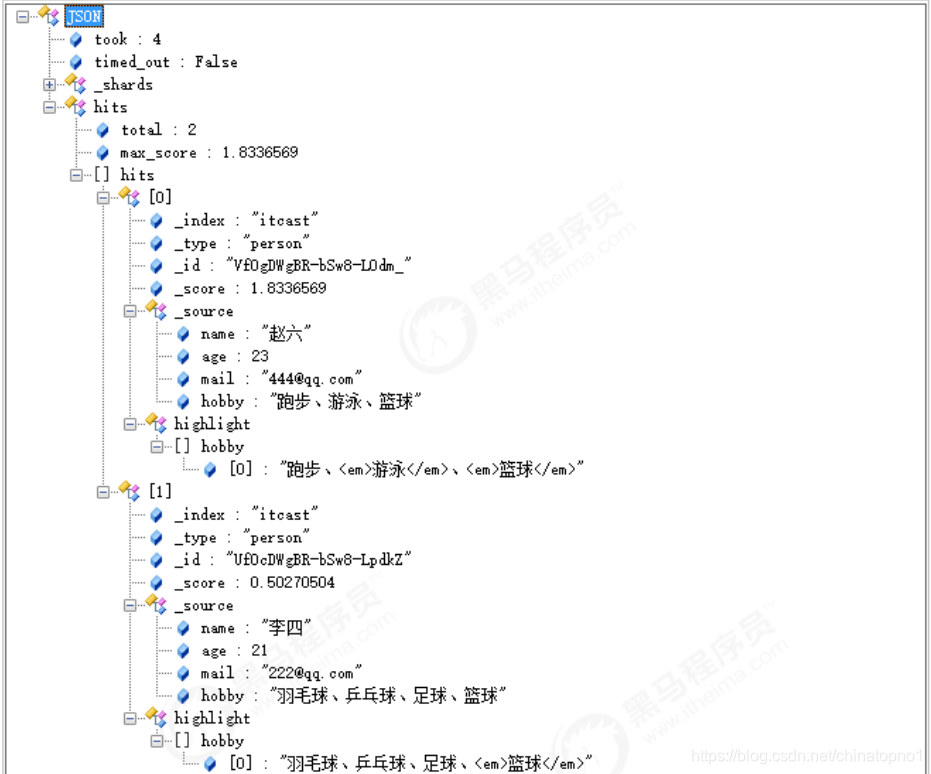
评分的计算规则:
bool 查询会为每个文档计算相关度评分 _score , 再将所有匹配的 must 和should 语句的分数 _score 求和,最后除以 must 和 should 语句的总数。
must_not 语句不会影响评分; 它的作用只是将不相关的文档排除。
默认情况下,should中的内容不是必须匹配的,如果查询语句中没有must,那么就会至少匹配其中一个。当然了,
也可以通过minimum_should_match参数进行控制,该值可以是数字也可以的百分比。
示例:
post 127.0.0.1:9200/mytest/person/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"hobby": "游泳"
}
},
{
"match": {
"hobby": "篮球"
}
},
{
"match": {
"hobby": "音乐"
}
}
],
"minimum_should_match": 2
}
},
"highlight": {
"fields": {
"hobby": { }
}
}
}
minimum_should_match为2,意思是should中的三个词,至少要满足2个。
结果:
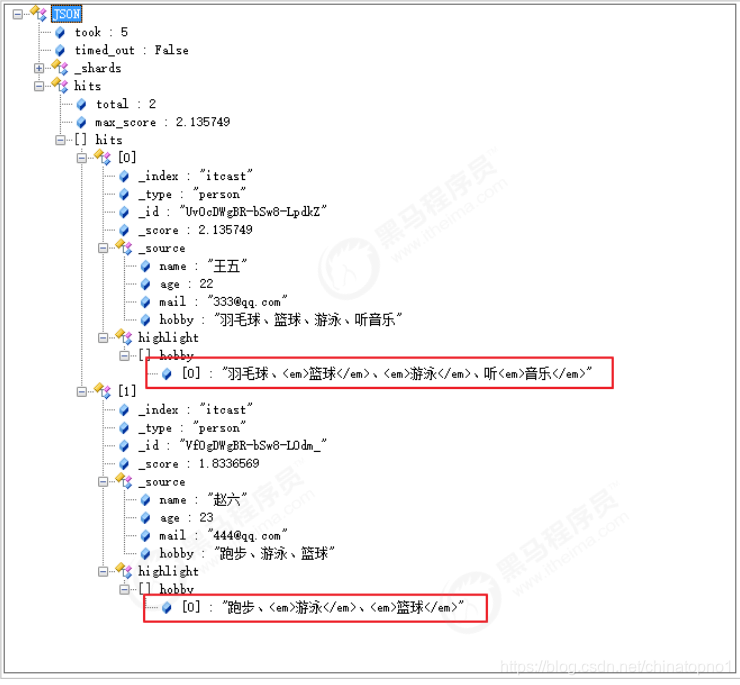

















 4472
4472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









