






1.创建项目
①、在想要创建目录的:scrapy startproject projectname
②、项目初始模板:
A:spider-爬虫对象<发送请求、解析数据>
B:Item-抓取数据的模型<字典>,可以扩展ItemLoader对原始数据进行二次加工。
C:middlewares-各种高级配置对象<还未深入学习>
D:pipelines-接收并校验数据,存储数据
E:settings-对爬虫进行全局配置
F:scrapy.cfg
2.常用scrapy命令
# 初始化项目
scrapy startproject project name
# 运行爬虫项目(注意这里的spidername爬虫对象Spider中的name字段值,同一工程中的spidername不允许重复)
scrapy crawl spidername
# 直接运行创建的爬虫
scrapy runspider spidername
# 查看当前项目中有多少爬虫
scrapy list
# 使用代码运行爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl spidername".split())
注:https://doc.scrapy.org/en/latest/topics/items.html
3.Crontab
①、Crontab命令是Unix系统和类Unix系统中,用来设置周期性执行的指令。
②、该命令从标准输入设备读取指令,并将其存放在“Crontab”文件中,以供后期读取和执行。
③、Crontab所存的指令,被守护进程激活。
④、crond常常在后台运行,以一分钟为间隔检查是否有预定的作业需要执行,这类作业一般成为cron jobs。
# 配置规则
# 1 * * * * 每分钟执行一次
# 0 * * * * 每小时执行一次
# 0 0 * * * 每天执行一次
# 0 0 * * 0 每周执行一次
# 0 0 1 * * 每月执行一次
# 0 0 1 1 * 每年执行一次配置步骤:
①、crontab -e
②、添加自己的定时任务
4.实战scrapy小练习
淘宝MM信息小爬虫
①、Spiders
#!/usr/bin/python
# -*- coding: UTF-8 -*-
__author__ = 'apple'
import scrapy
from scrapy import Spider,cmdline
from ScrapyTemplate.items import TBMMInfo
from scrapy.selector import Selector,SelectorList
from scrapy.loader import ItemLoader,processors
from scrapy.http.response.html import HtmlResponse
import re,time
# 爬取淘宝MM的数据
class TBMMSpider(Spider):
# 用于区别Spider,该名字必须是唯一的,您不可以为不同的Spider设定相同的名字
name = 'TBMM'
# 请求时间间隔
download_delay = 3
# 请求页码范围
page_index = 0
max_index = 1
# 允许访问的域名
allowed_domain = ['mm.taobao.com']
# 包含了Spider在启动时进行爬取的url列表®
# start_urls = [ ]
# 构造请求
def start_requests(self):
self.page_index += 1
results = []
if self.page_index <= self.max_index:
new_url = 'https://mm.taobao.com/json/request_top_list.htm?page=%s'%(self.page_index)
print('新的请求:',new_url)
results.append(scrapy.Request(new_url,callback=self.parse))
return results
# 解析方法:parse() 是spider的一个方法
def parse(self, response):
for person in response.xpath('/html/body/div[@class="list-item"]'):
tbMM = TBMMInfo()
###### CSS Selector解析
# 用户基础信息
person_info = person.css('div.personal-info>div.pic-word')
# 用户扩展信息
list_info = person.css('div.list-info')
tbMM['name'] = person_info.css('p.top>a::text').extract_first()
tbMM['userid'] = person_info.css('p.top>span.friend-follow::attr(data-userid)').extract_first()
tbMM['homepage'] = 'http:'+person_info.css('p.top>a::attr(href)').extract_first()
tbMM['avater'] = 'http:'+person_info.css('div.pic>a>img::attr(src)').extract_first()
tbMM['age'] = person_info.css('p.top>em>strong::text').extract_first()
# 匿名类:last-child nth-child(num)
tbMM['city'] = person_info.css('p.top>span::text').extract_first()
tbMM['jobs'] = person_info.css('p:last-child>em::text').extract_first()
tbMM['fans'] = person_info.css('p:last-child>em:last-child>strong::text').extract_first()
rank = list_info.css('div.popularity>dl>dt::text').extract_first()
tbMM['rank'] = re.sub('\s','',rank)
total_integral = list_info.css('div.popularity>dl>dd::text')[1].extract()
tbMM['total_integral'] = re.sub('\s','',total_integral)
# 信息列表
ul_list = ['add_integral','feedback_rate','image_count','sign_count']
for i in range(1,len(ul_list) + 1):
css_str = 'ul.info-detail>li>strong::text' if i == 1 else 'ul.info-detail>li:nth-child(%s)>strong::text'%(i)
value = list_info.css(css_str).extract_first()
if re.sub('\D','',value) == '':
value = '0'
tbMM[ul_list[i - 1]] = value
tbMM['description'] = list_info.css('p::text').extract_first().strip()
tbMM['insert_date'] = str(time.time())
###### XPath Selector解析
# person_info = person.xpath('div[@class="personal-info"]/div[@class="pic-word"]')
# list_info = person.xpath('div[@class="list-info"]')
#
# tbMM['name'] = person_info.xpath('p[@class="top"]/a/text()').extract_first()
# tbMM['userid'] = person_info.xpath('p[@class="top"]/span[@class="friend-follow J_FriendFollow"]/@data-userid').extract_first()
# tbMM['homepage'] = person_info.xpath('p[@class="top"]/a/@href').extract_first()
# tbMM['avater'] = person_info.xpath('div[@class="pic s60"]/a/img/@src').extract_first()
# tbMM['age'] = person_info.xpath('p[@class="top"]/em/strong/text()').extract_first()
# tbMM['city'] = person_info.xpath('p[@class="top"]/span[1]/text()').extract_first()
# tbMM['jobs'] = person_info.xpath('p[last()]/em/text()').extract_first()
# tbMM['fans'] = person_info.xpath('p[last()]/em[last()]/strong/text()').extract_first()
# rank = list_info.xpath('div[@class="popularity"]/dl/dt/text()').extract_first()
# tbMM['rank'] = re.sub('\s', '', rank)
# total_integral = list_info.xpath('div[@class="popularity"]/dl/dd/text()')[1].extract()
# tbMM['total_integral'] = re.sub('\s', '', total_integral)
# ul_list = ['add_integral', 'feedback_rate', 'image_count', 'sign_count']
# for i in range(1, len(ul_list) + 1):
# tbMM[ul_list[i - 1]] = list_info.xpath('ul[@class="info-detail"]/li[%s]/strong/text()'%(i)).extract_first()
# tbMM['description'] = list_info.xpath('p/text()').extract_first().strip()
# for key,value in tbMM.items():
# print(key,'=',value)
yield tbMM
# yield Request:返回请求对象
requests = self.start_requests()
if requests: yield requests[0]
@classmethod
def parser_list(cls,response):
###### XPath Selector解析使用itemLoader
# 用户基础信息
person_info = 'div.personal-info>div.pic-word>'
# 用户扩展信息
list_info = 'div.list-info>'
# 初始化loader
loader = ItemLoader(item=TBMMInfo(), response=response)
loader.add_css('name', person_info + 'p.top>a::text')
loader.add_css('userid', person_info + 'p.top>span.friend-follow::attr(data-userid)')
loader.add_css('homepage', person_info + 'p.top>a::attr(href)')
loader.add_css('avater', person_info + 'div.pic>a>img::attr(src)')
loader.add_css('age', person_info + 'p.top>em>strong::text')
# 匿名类:last-child nth-child(num)
loader.add_css('city', person_info + 'p.top>span::text')
loader.add_css('jobs', person_info + 'p:last-child>em::text')
loader.add_css('fans', person_info + 'p:last-child>em:last-child>strong::text')
loader.add_css('rank', list_info + 'div.popularity>dl>dt::text')
loader.add_css('total_integral', list_info + 'div.popularity>dl>dd::text')
# 信息列表
ul_list = ['add_integral', 'feedback_rate', 'image_count', 'sign_count']
for i in range(1, len(ul_list) + 1):
loader.add_css(ul_list[i - 1],
list_info + 'ul.info-detail>li>strong::text' if i == 1 else list_info + 'ul.info-detail>li:nth-child(%s)>strong::text' % (
i))
loader.add_css('description', list_info+'p::text')
return loader.load_item()
if __name__ == "__main__":
print('TBMMSpider__Main')
'''
# 迭代器
def diedai_num():
for i in range(4):
yield i
i += 1
for m in range(3):
yield str(m)+'TRUE'
m += 1
iter = iter(diedai_num())
print(type(iter))
x = 1
nums = []
strs = []
while True:
try:
value = next(iter)
if isinstance(value,int):
nums.append(value)
elif isinstance(value,str):
strs.append(value)
print('第%d次'%(x),value,'\n')
x += 1
except StopIteration:
print('迭代完成!!!')
break
print('获取到的数字结果:',nums)
print('获取到的字符串结果:',strs)
'''
②、items
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Field,Item
########### 对象模型类
class TBMMInfo(Item):
# Item:一个包含了item所有声明的字段的字典,不仅仅是获取到的字段。
# 该字典的key是字段(field)的名字,值是 Item声明 中使用到的 Field 对象。
# Field:仅仅是内置字典的一个别名
userid = Field() # 用户ID
name = Field() # 姓名
homepage = Field() # 个人主页
avater = Field() # 头像
age = Field() # 年龄
city = Field() # 城市
jobs = Field() # 职业
fans = Field() # 粉丝数
rank = Field() # 排行
total_integral = Field() # 总积分
add_integral = Field() # 新增积分
feedback_rate = Field() # 好评率
image_count = Field() # 导购照片
sign_count = Field() # 签约数量
description = Field() # 描述
insert_date = Field() # 插入时间
# 在Item Loader 中声明的 field-specific 属性: field_in and field_out (most precedence)
# Item中的字段元数据(input_processor and output_processor key)
# Item Loader 默认处理器: ItemLoader.default_input_processor() and ItemLoader.default_output_processor() (least precedence)
③、pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from ScrapyTemplate.items import TBMMInfo
from ScrapyTemplate import settings
from scrapy import Item
from scrapy.exceptions import DropItem
import pymysql
class DBManagerHelp(object):
def __init__(self):
# 数据库连接参数
self.db_configs = settings.DEFAULT_DB_CONFIG
# 数据库
self.connect(**self.db_configs)
# 数据源
self.data_source = []
# 连接数据库
def connect(self,**kwargs):
try:
self._SQL_DB = pymysql.Connect(**kwargs)
self._DB_CURSOR = self._SQL_DB.cursor()
print('DBManagerHelp数据库连接成功',self._SQL_DB)
except Exception as e:
self._SQL_DB = None
self._DB_CURSOR = None
print(repr(e), 'ERROR')
@property
def sql_db(self):
if self._SQL_DB is None : self.connect(self.db_configs)
return self._SQL_DB
@property
def db_cursor(self):
if self._DB_CURSOR is None: self.connect(self.db_configs)
return self._DB_CURSOR
# 创建表
def create_table(self,name,fields={}):
if not fields :
print('DBManagerHelp建表失败:',name)
return
fields_sql = ''
items = fields.items() if isinstance(fields,dict) else fields
for key, value in items:
fields_sql += (str.upper(key) + ' ' + str.upper(value) + ',')
# 建表sql
table_sql = '''CREATE TABLE IF NOT EXISTS %s(%s)'''%(name,fields_sql[:-1])
try:
# 执行建表语句
self.db_cursor.execute(table_sql)
self.commit_all()
except Exception as e:
print(repr(e), 'ERROR')
# 建表参数<留待子类重写>
def table_infos(self):
return '',{}
# 批量插入到数据库
def insert_items(self,item_source=[]):
if not item_source : return
# 获取表名和字段名
table_name,fields = self.table_infos()
# 需要插入的字段
insert_keys = fields.keys()
# 要插入的列表
values_list = []
for item in item_source:
value_tuple = []
for field in insert_keys:
lower_field = str.lower(field)
if field in item.keys():
value_tuple.append(item[field])
elif lower_field in item.keys():
value_tuple.append(item[lower_field])
if not value_tuple:continue
values_list.append(tuple(value_tuple))
if not values_list : return
key_sql = ','.join(insert_keys)
value_sql = ','.join(['%s' for i in range(len(insert_keys))])
update_sql = ','.join([field + '=VALUES(' + field + ')' for field in insert_keys])
# 插入语句
insert_sql = r"""INSERT INTO %s(%s) VALUES (%s) ON DUPLICATE KEY UPDATE %s"""%(table_name,key_sql,value_sql,update_sql)
try:
self.db_cursor.executemany(insert_sql,values_list)
self.data_source.clear()
self.commit_all()
except Exception as e:
print('数据插入失败:', repr(e))
# 提交到数据库
def commit_all(self,close=False):
try:
self.sql_db.commit()
except Exception as e:
print(repr(e), 'ERROR')
# 事务回滚
self.sql_db.rollback()
if close:
self.db_cursor.close()
self.sql_db.close()
################# scrapy的回调方法 #################
def open_spider(self, spider):
print('DBManagerHelp开始:', spider)
# 创建表格
table_name,fields = self.table_infos()
self.create_table(table_name,fields)
def process_item(self, item, spider):
if len(self.data_source) > settings.MAX_INSERTS_ITEM:
print('批量插入数据:',settings.MAX_INSERTS_ITEM,'条')
self.insert_items(self.data_source)
def close_spider(self, spider):
print('DBManagerHelp关闭:', spider)
# 插入数据
self.insert_items(self.data_source)
# 事务提交或者回滚
self.commit_all(close=True)
class TBMMInfoPipeline(DBManagerHelp):
def table_infos(self):
return 'TBMM_TABLE',{'USERID': 'VARCHAR(20) NOT NULL PRIMARY KEY',
'NAME': 'VARCHAR(20)',
'HOMEPAGE': 'VARCHAR(100)',
'AVATER': 'VARCHAR(100)',
'AGE': 'INT',
'CITY': 'VARCHAR(10)',
'JOBS': 'VARCHAR(40)',
'FANS': 'INTEGER',
'RANK': 'INTEGER',
'TOTAL_INTEGRAL': 'INTEGER',
'ADD_INTEGRAL': 'INTEGER',
'FEEDBACK_RATE': 'INTEGER',
'IMAGE_COUNT': 'INTEGER',
'SIGN_COUNT': 'INTEGER',
'DESCRIPTION': 'VARCHAR(400)',
'INSERT_DATE': 'INTEGER'
}
# 数据插入失败: InternalError(1366, "Incorrect integer value: '—' for column 'FEEDBACK_RATE' at row 1")
# SQL语句在windows下不区分大小写,在Linux下数据库名、表名、字段名区分大小写
def process_item(self, item, spider):
super(TBMMInfoPipeline,self).process_item(item,spider)
# 淘宝MM数据
if isinstance(item,TBMMInfo) and item['userid'] is not None:
self.data_source.append(item)
return item
else:
raise DropItem('UserId is nil')
④、settings
# -*- coding: utf-8 -*-
# Scrapy settings for ScrapyTemplate project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
import random
BOT_NAME = 'ScrapyTemplate'
SPIDER_MODULES = ['ScrapyTemplate.spiders']
NEWSPIDER_MODULE = 'ScrapyTemplate.spiders'
# 日志级别
# CRITICAL - 严重错误(critical)
# ERROR - 一般错误(regular errors)
# WARNING - 警告信息(warning messages)
# INFO - 一般信息(informational messages)
# DEBUG - 调试信息(debugging messages)
LOG_LEVEL = 'ERROR'
# Obey robots.txt rules
# 通俗来说,robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中。
# 它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页 不希望 你进行爬取收录
ROBOTSTXT_OBEY = False
# 禁止重定向
# REDIRECT_ENABLED = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)<全局并发数>
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3 # 下载延迟
DOWNLOAD_TIMEOUT = 15 # 下载超时
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)<禁止/启用Cookie>
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
"Accept": "*/*",
'Referer': 'http://www.baidu.com',
'Accept-Encoding':'UTF-8'
}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'ScrapyTemplate.middlewares.ScrapytemplateSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'ScrapyTemplate.middlewares.MyCustomDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines<存储器部件>
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'ScrapyTemplate.pipelines.TBMMInfoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 数据库链接默认配置
# '''
# host = None, user = None, password = "",
# database = None, port = 0, unix_socket = None,
# charset = '', sql_mode = None,
# read_default_file = None, conv = None, use_unicode = None,
# client_flag = 0, cursorclass = Cursor, init_command = None,
# connect_timeout = 10, ssl = None, read_default_group = None,
# compress = None, named_pipe = None, no_delay = None,
# autocommit = False, db = None, passwd = None, local_infile = False,
# max_allowed_packet = 16 * 1024 * 1024, defer_connect = False,
# auth_plugin_map = {}, read_timeout = None, write_timeout = None,
# bind_address = None
# '''
DEFAULT_DB_CONFIG = {
'host':'127.0.0.1',
'port':3306,
'user':'root',
'passwd':'apple',
'db':'TESTDB',
'charset':'utf8',
'use_unicode':True,
'connect_timeout':20
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENTS = ['Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36',
]
USER_AGENT = random.choice(USER_AGENTS)
# 数据库批量插入最大数值
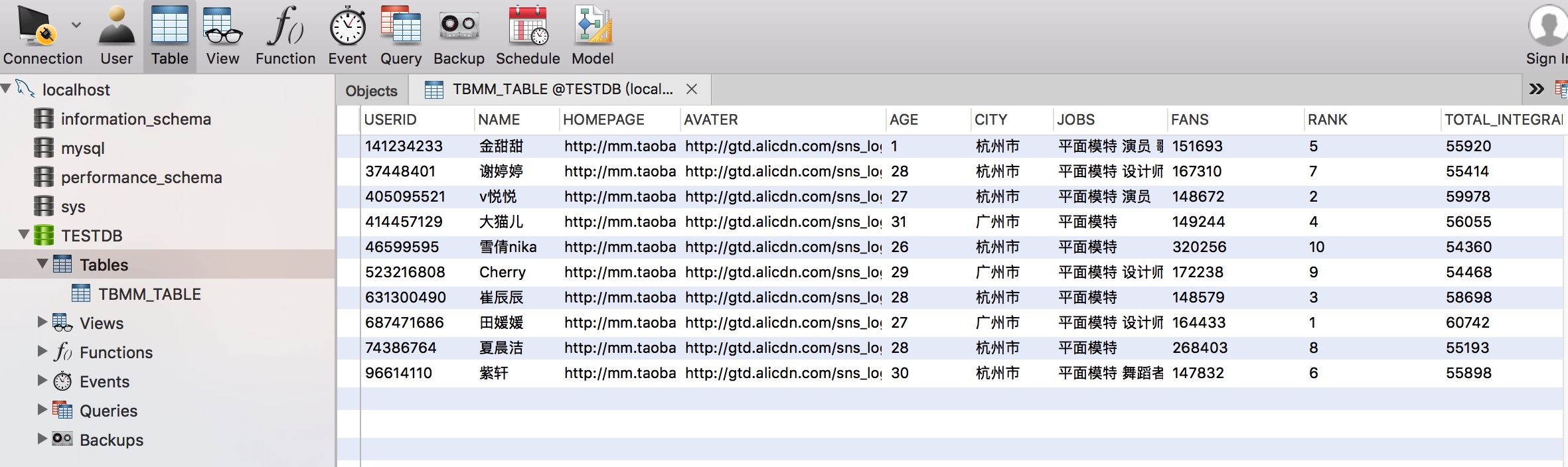
MAX_INSERTS_ITEM = 100⑤、数据库















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









