







转自:http://blog.csdn.net/am45337908/article/details/48832947
一.D-S证据理论引入
诞生
D-S证据理论的诞生:起源于20世纪60年代的哈佛大学数学家A.P. Dempster利用上、下限概率解决多值映射问题,1967年起连续发表一系列论文,标志着证据理论的正式诞生。
形成
dempster的学生G.shafer对证据理论做了进一步发展,引入信任函数概念,形成了一套“证据”和“组合”来处理不确定性推理的数学方法
D-S理论是对贝叶斯推理方法推广,主要是利用概率论中贝叶斯条件概率来进行的,需要知道先验概率。而D-S证据理论不需要知道先验概率,能够很好地表示“不确定”,被广泛用来处理不确定数据。
适用于:信息融合、专家系统、情报分析、法律案件分析、多属性决策分析
二.D-S证据理论的基本概念
1、识别框架:由互不相容的基本命题(假定)组成的完备集合,表示对某一问题的所有可能答案,但其中只有一个答案是正确的。
2、mass函数(BPA):识别框架的子集称为命题。分配给各命题的信任程度称为基本概率分配。m(A)反映着对A的信度大小。

3、信任函数:信任函数Bel(A)表示对命题A的信任程度。

4、似然函数:似然函数Pl(A)表示对命题A非假的信任程度,也即对A似乎可能成立的不确定性度量。

5、合成规则(以两个mass函数为例)。

三.D-S证据理论的组合规则
m个mass函数的Dempster合成规则

其中K称为归一化因子,
1−K
即
∑A1⋂...⋂An=ϕm1(A1)⋅m2(A2)⋅⋅⋅mn(An)
反 应了证据的冲突程度
四.判决规则
设存在
A1,A2⊂U
,满足
m(A1)=max{m(Ai),Ai⊂U}
m(A2)=max{m(Ai),Ai⊂U且Ai≠A1}
若有:
m(A1)−m(A2)>ε1
m(Θ)<ε2
m(A1)>m(Θ)
则
A1
为判决结果,
ε1,ε2
为预先设定的门限,
Θ
为不确定集合
五.D-S证据理论存在的问题
(一)无法解决证据冲突严重和完全冲突的情况
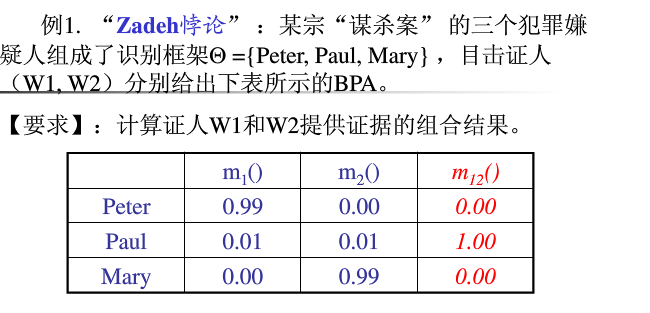
该识别框架为{Peter,Paul,Mary},基本概率分配函数为m{Peter},m{Paul},m{Mary}
由D-S证据理论的基本概念和组合规则进行解析



可以看出虽然在W1,W2目击中,peter和mary都为0.99,但是存在严重的冲突,造成合成之后的Bel函数值为0,这显然与实际情况不合,更极端的情况如果W1中m{peter)=1,W2中m{Mary}=1,则归一化因子K=0,D-S组合规则无法进行
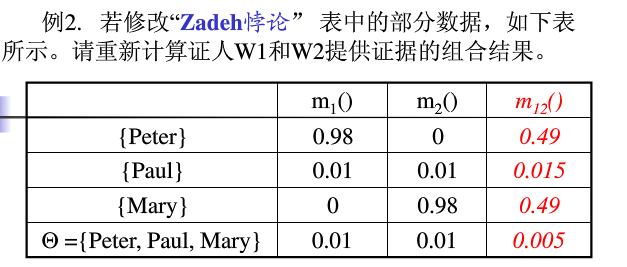






(二)难以辨识模糊程度
由于证据理论中的证据模糊主要来自于各子集的模糊度。根据信息论的观点,子集中元素的个数越多,子集的模糊度越大
(三)基本概率分配函数的微小变化会使组合结果产生急剧变化
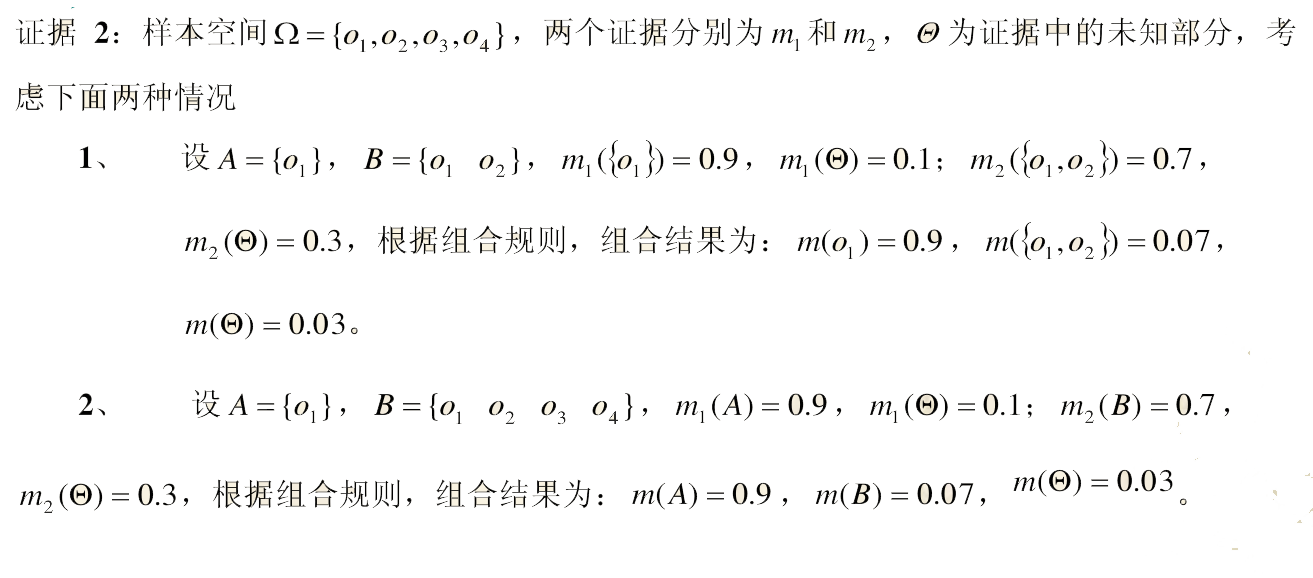
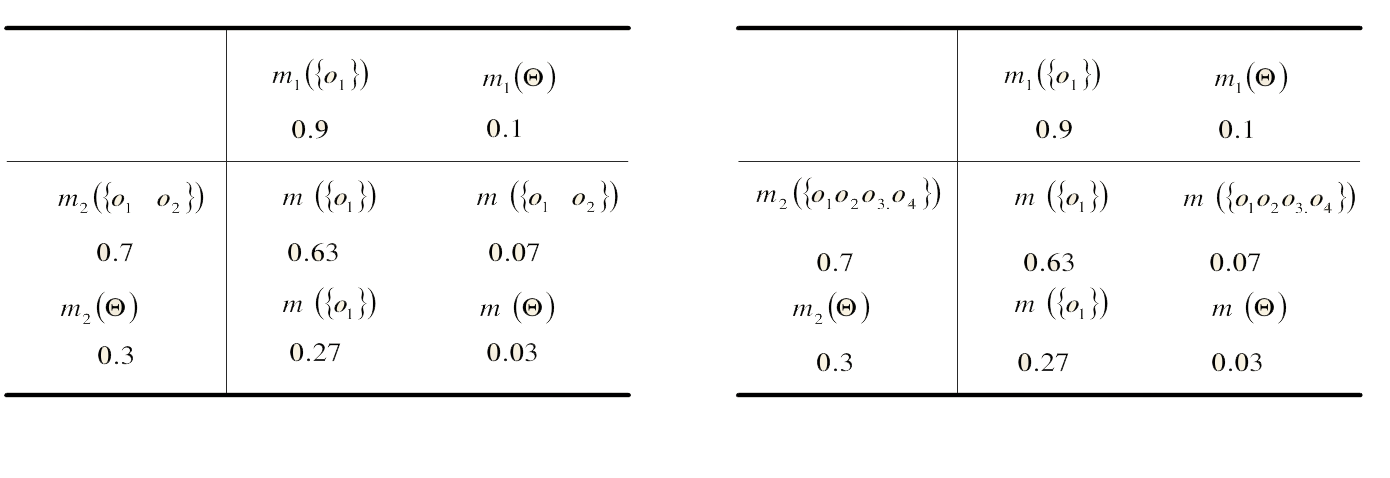


一.Yager合成公式

改进中主要引入了 m(X) ,把冲突给了未知命题
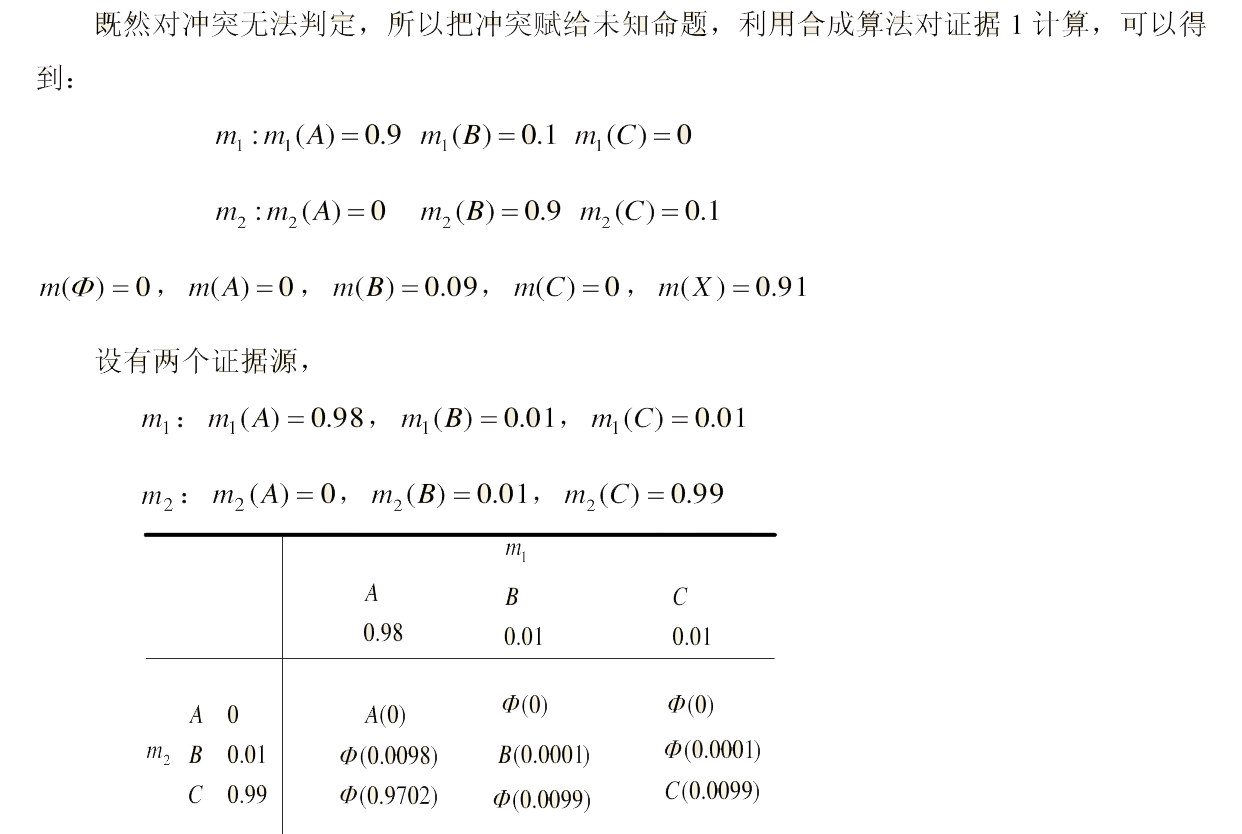


二.Yager合成公式改进
为了解决多个证据中有一个证据否定A,则合成结果也否认A,对Yager公式进行改进

例1:
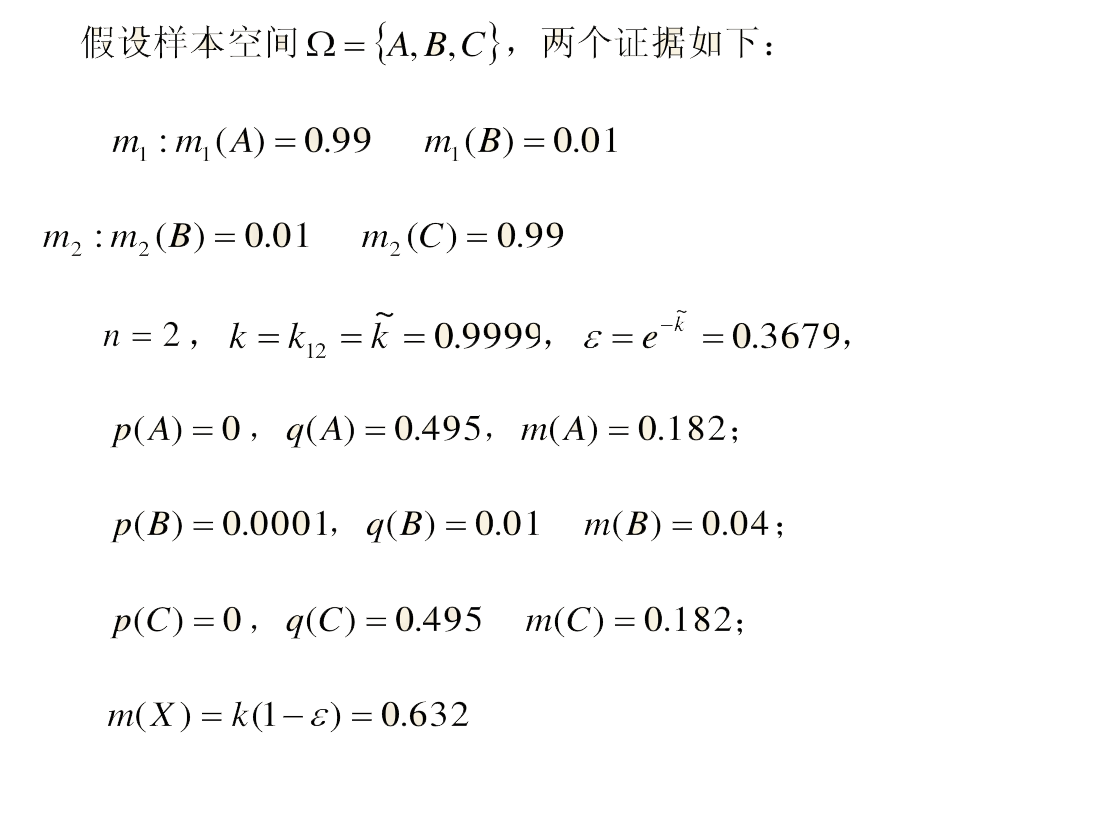
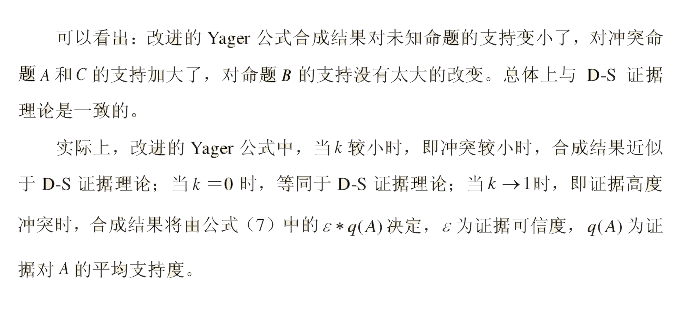
例2:
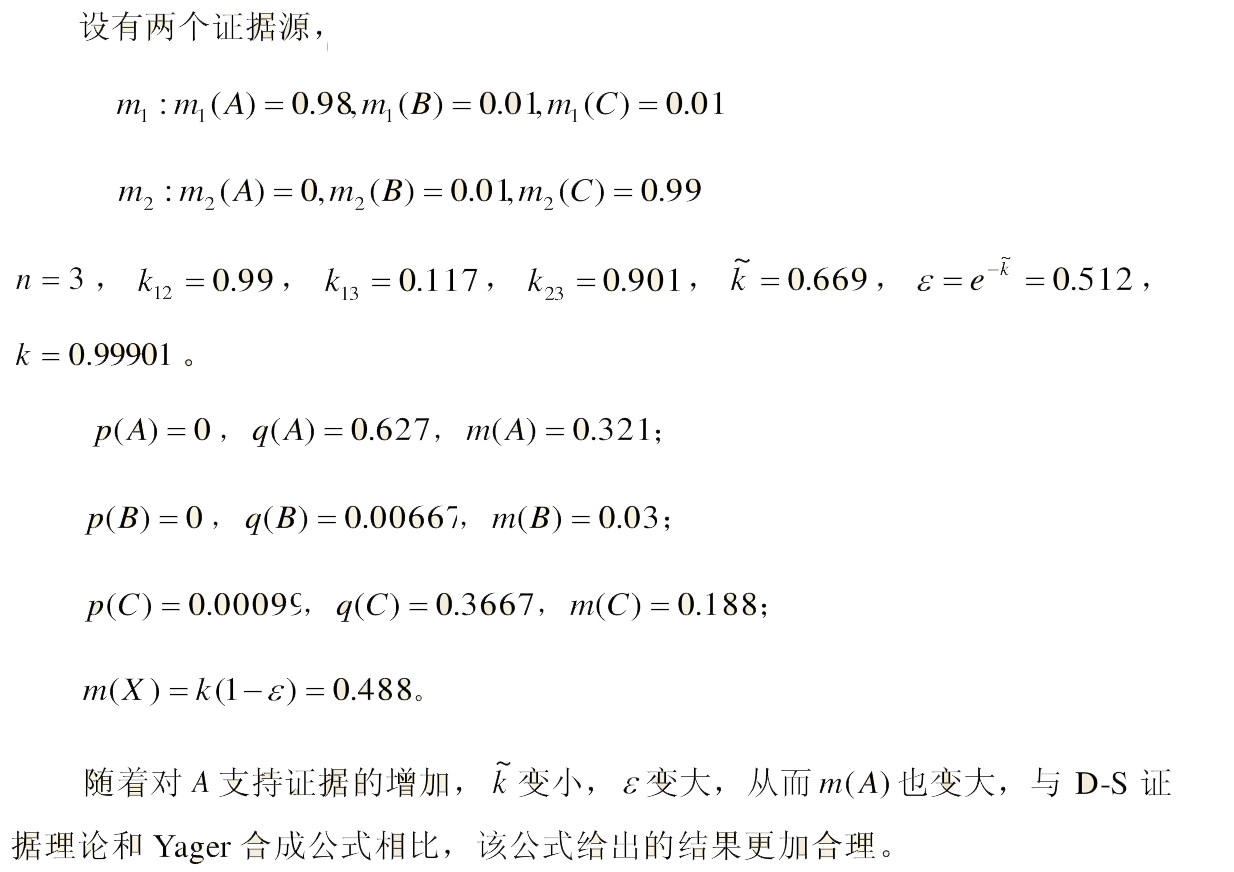


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









