







a. 基本类型:所有的基本类型都有相应的对齐参数,编译器在编译时,会用全局的对齐参数和当前类型的对齐参数中较小的一个进行对齐。比如,编译时指定暗8bytes对齐(用#pragma pack(8)实现之),可是由于一个char变量的大小为一个byte,所以最后还是按1byte对齐。
b. 复合类型:复合类型的对齐原则,就是取其成员变量数据类型的字节数的最大者和在编译时指定的对齐数两者之间较小的字节数进行对齐。如果没有用诸如#pragma pack指定全局对齐数,则该复合类型的对齐数就是其成员变量数据类型字节数之最大者。
即:(1)用#pragma pack(8)指定了全局对齐数目: 一个类对象的内存对齐数 = min(指定的全局对齐数,成员变量数据
类型字节数最大者)
(2)未指定全局对齐数目:
一个类对象的内存对齐数 = max(成员变量数据
类型字节数最大者)例如:
<span style="font-size:14px;">#include <iostream>
using namespace std;
// #pragma pack(4)
class PatClass0 // PatClass0的对齐数为1。因为其成员变量c1的数据类型为char,而sizeof(char)=1
{
private:
char c1;
};
class PatClass1 // PatClass1的对齐数为1。因为其成员变量c1和c2的数据类型均为char,而sizeof(char)=1
{
private:
char c1;
char c2;
};
class PatClass2 // PatClass2的对齐数为2。因为其成员变量c1的数据类型均为char,sizeof(char)=1,
{ // 成员变量c2的数据类型为short,而sizeof(short)=2。
private: // 取其字节数最大者,即2。
char c1;
short c2;
};
class PatClass3 // PatClass3的对齐数为4。因为其成员变量c1的数据类型均为char,sizeof(char)=1,
{ // 成员变量c2的数据类型为int,而sizeof(int)=4。
private: // 取其字节数最大者,即4。
char c1;
int c2;
};
class PatClass4 // PatClass4的对齐数为8。因为其成员变量c1的数据类型均为char,sizeof(char)=1,
{ // 成员变量c2的数据类型为double,而sizeof(8)=8。
private: // 取其字节数最大者,即8。
char c1;
double c2;
};
class PatClass5 // PatClass5的对齐数为4。见PatClass3说明
{
private:
int c1;
};
class PatClass6 : public PatClass5 // PatClass6的对齐数为4。这是因为它继承了PatClass5,PatClass5中的成员
{ // 变量c1也会被编译器安插在类PatClass6的对象中(尽管不能对其进行普通意
private: // 义上的访问),而c1的数据类型为int,sizeof(int)=4。所以PatClass6的对齐数
char c2; // 为4。
};
int main(void)
{
PatClass0 c0;
PatClass1 c1;
PatClass2 c2;
PatClass3 c3;
PatClass4 c4;
PatClass5 c5;
PatClass6 c6;
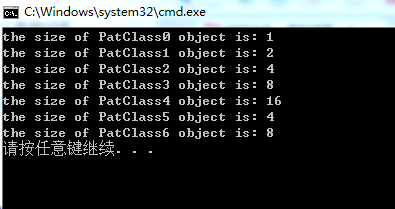
cout << "the size of PatClass0 object is: " << sizeof(c0) << endl;
// PatClass0的对齐数为1byte,它只有一个成员变量char c1,因此其对象c0的大小为1byte
cout << "the size of PatClass1 object is: " << sizeof(c1) << endl;
// PatClass1的对齐数为1byte,它有两个成员变量char c1和char c2,因此其对象c1的大小为2bytes
cout << "the size of PatClass2 object is: " << sizeof(c2) << endl;
// PatClass2的对齐数为2bytes,它有一个成员变量char c1和一个成员变量short c2,合起来为3bytes,由于其
// 对齐数为2bytes,因此需要填充1byte,才能变成2的倍数。故此其对象c2的大小为4bytes。
cout << "the size of PatClass3 object is: " << sizeof(c3) << endl;
// PatClass3的对齐数为4bytes,它有一个成员变量char c1和一个成员变量int c2,合起来为5bytes,由于其
// 对齐数为4bytes,因此需要填充3bytes,才能变成4的倍数。故此其对象c3的大小为8bytes。
cout << "the size of PatClass4 object is: " << sizeof(c4) << endl;
// PatClass4的对齐数为8bytes,它有一个成员变量char c1和一个成员变量double c2,合起来为9 bytes,由于
// 其对齐数为8bytes,因此需要填充7bytes,才能变成8的倍数。故此其对象c4的大小为16 bytes。
cout << "the size of PatClass5 object is: " << sizeof(c5) << endl;
// PatClass5的对齐数为4 bytes,它只有一个成员变量int c1,合起来为4bytes,刚好是其对齐数的倍数。
// 故此其对象c5的大小为4 bytes。
cout << "the size of PatClass6 object is: " << sizeof(c6) << endl;
// PatClass6的对齐数为4 bytes,它有一个成员变量char c2,并从PatClass5中继承来了int c1,合起来为5bytes,
// 因此需要填充3bytes,才能变成4的倍数。故此其对象c6的大小为8 bytes。
return 0;
}</span>
输出结果为:
如果用#pragma pack(4)(在上面的程序中被注释了)指定全局对齐数为4bytes,结果如下:
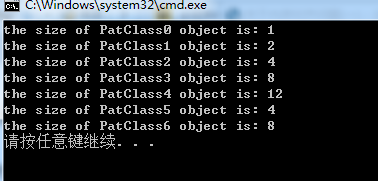
其实这样的指定,只影响到了PatClass4,因为只有它有一个double成员变量,而sizeof(double)=8bytes,其他各类
均没有数据类型超过4bytes的。在前面曾经提及,一个类对象的内存对齐数 = min(指定的全局对齐数,成员变量数据
类型字节数最大者),因此在这个例子中PatClass4类型的对象的对齐数应该为4bytes。在PatClass类型的对象c4中,
成员变量double c2占8bytes,另外一个成员变量char c1占1byte,合起来一共9 bytes,因此要最小填充3 bytes,
才能成员对齐数4的倍数,即此时PatClass4类型的对象的大小为12bytes。
许多实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐,而这个k则被称为该数据类型的对齐模数(alignment modulus)。当一种类型S的对齐模数与另一种类型T的对齐模数的比值是大于1的整数,我们就称类型S的对齐要求比T强(严格),而称T比S弱(宽 松)。这种强制的要求一来简化了处理器与内存之间传输系统的设计,二来可以提升读取数据的速度。比如这么一种处理器,它每次读写内存的时候都从某个8倍数 的地址开始,一次读出或写入8个字节的数据,假如软件能保证double类型的数据都从8倍数地址开始,那么读或写一个double类型数据就只需要一次 内存操作。否则,我们就可能需要两次内存操作才能完成这个动作,因为数据或许恰好横跨在两个符合对齐要求的8字节内存块上。某些处理器在数据不满足对齐要 求的情况下可能会出错,但是Intel的IA32架构的处理器则不管数据是否对齐都能正确工作。不过Intel奉劝大家,如果想提升性能,那么所有的程序 数据都应该尽可能地对齐。
ANSI C标准中并没有规定,相邻声明的变量在内存中一定要相邻。为了程序的高效性,内存对齐问题由编译器自行灵活处理,这样导致相邻的变量之间可能会有一些填充 字节。对于基本数据类型(int char),他们占用的内存空间在一个确定硬件系统下有个确定的值,所以,接下来我们只是考虑结构体成员内存分配情况。
Win32平台下的微软C编译器(cl.exe for 80×86)的对齐策略:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
备注:编译器在给结构体开辟空间时,首先找到结构体中最宽的基本数据类型,然后寻找内存地址能被该基本数据类型所整除的位置,作为结构体的首地址。将这个最宽的基本数据类型的大小作为上面介绍的对齐模数。
2) 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
备注:为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的首地址相对于结构体首地址的偏移是否是本成员的整数倍,若是,则存放本成员,反之,则在本成员和上一个成员之间填充一定的字节,以达到整数倍的要求,也就是将预开辟空间的首地址后移几个字节。
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要,编译器会在最末一个成员之后加上填充字节(trailing padding)。
备注:结构体总大小是包括填充字节,最后一个成员满足上面两条以外,还必须满足第三条,否则就必须在最后填充几个字节以达到本条要求。
根据以上准则,在windows下,使用VC编译器,sizeof(T)的大小为8个字节。
而在GNU GCC编译器中,遵循的准则有些区别,对齐模数不是像上面所述的那样,根据最宽的基本数据类型来定。在GCC中,对齐模数的准则是:对齐模数最大只能是 4,也就是说,即使结构体中有double类型,对齐模数还是4,所以对齐模数只能是1,2,4。而且在上述的三条中,第2条里,offset必须是成员 大小的整数倍,如果这个成员大小小于等于4则按照上述准则进行,但是如果大于4了,则结构体每个成员相对于结构体首地址的偏移量(offset)只能按照 是4的整数倍来进行判断是否添加填充。
看如下例子:
struct T
{
char ch;
double d ;
};
那么在GCC下,sizeof(T)应该等于12个字节。
如果结构体中含有位域(bit-field),那么VC中准则又要有所更改:
1) 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
2) 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
3) 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式(不同位域字段存放在不同的位域类型字节中),Dev-C++和GCC都采取压缩方式;
备注:当两字段类型不一样的时候,对于不压缩方式,例如:
struct N
{
char c:2;
int i:4;
};
依然要满足不含位域结构体内存对齐准则第2条,i成员相对于结构体首地址的偏移应该是4的整数倍,所以c成员后要填充3个字节,然后再开辟4个字节的空间 作为int型,其中4位用来存放i,所以上面结构体在VC中所占空间为8个字节;而对于采用压缩方式的编译器来说,遵循不含位域结构体内存对齐准则第2 条,不同的是,如果填充的3个字节能容纳后面成员的位,则压缩到填充字节中,不能容纳,则要单独开辟空间,所以上面结构体N在GCC或者Dev-C++中 所占空间应该是4个字节。
4) 如果位域字段之间穿插着非位域字段,则不进行压缩;
备注:
结构体
typedef struct
{
char c:2;
double i;
int c2:4;
}N3;
在GCC下占据的空间为16字节,在VC下占据的空间应该是24个字节。
5) 整个结构体的总大小为最宽基本类型成员大小的整数倍。
ps:
- 对齐模数的选择只能是根据基本数据类型,所以对于结构体中嵌套结构体,只能考虑其拆分的基本数据类型。而对于对齐准则中的第2条,确是要将整个结构体看成是一个成员,成员大小按照该结构体根据对齐准则判断所得的大小。
- 类对象在内存中存放的方式和结构体类似,这里就不再说明。需要指出的是,类对象的大小只是包括类中非静态成员变量所占的空间,如果有虚函数,那么再另外增加一个指针所占的空间即可。
位域
有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可。为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为“位域”或“位段”。所谓“位域”是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。 这样就可以把几个不同的对象用一个字节的二进制位域来表示。一、位域的定义和位域变量的说明位域定义与结构定义相仿,其形式为:
struct 位域结构名
{ 位域列表 };
其中位域列表的形式为: 类型说明符 位域名:位域长度
例如:
struct bs
{
int a:8;
int b:2;
int c:6;
};
位域变量的说明与结构变量说明的方式相同。 可采用先定义后说明,同时定义说明或者直接说明这三种方式。例如:
struct bs
{
int a:8;
int b:2;
int c:6;
}data;
说明data为bs变量,共占两个字节。其中位域a占8位,位域b占2位,位域c占6位。对于位域的定义尚有以下几点说明:
1. 如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域从下一单元开始。例如:
struct bs
{
unsigned a:4
unsigned :0 /*空域*/
unsigned b:4 /*从下一单元开始存放*/
unsigned c:4
}
在这个位域定义中,a占第一个单元的前4位,后28位填0表示不使用,b从第二个单元开始,b占用4位,c占用4位。
2. 位域可以无位域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
struct k
{
int a:1
int :2 /*该2位不能使用*/
int b:3
int c:2
};
从以上分析可以看出,位域在本质上就是一种结构类型, 不过其成员是按二进位分配的。#include <stdio.h> typedef struct _A { unsigned int a:4;//位段成员的类型仅能够为unsigned或者int unsigned b:4; unsigned c:2; unsigned d:6; unsigned E:1; unsigned D:2; unsigned T:3; unsigned A:9; unsigned h:4; //前面已经为31,故4+31>32已超过一个存储单元,所以4在一个新的存储单元存放 unsigned y:29;//由于前面的4在一个新的存储单元的开头存放,且29+4>32, 故在另一个新的存储单元存放 }A; //所以最后求出的A的大小是4 + 4 + 4 =12 /*对上面的具体解释: 一个位段必须存储在同一个存储单元中,不能跨两个单元.如果某存储单元空间中不能容纳 下一个位段,则改空间不用,而从下一个存储单元起存放该位段. 结构体A中的h和y就是这种情况. 在gcc环境下,测试后,一个存储单元为4个字节. */ typedef struct _S { unsigned a:4; unsigned b:4; unsigned c:22; unsigned q:1; unsigned h:1; //unsigned i:33; // 错误:‘i’ 的宽度超过它自身的类型 //unsigned i:1;当多出此行时,该结构体大小由4变为8,因为此行之前正好为32位 } S; typedef struct _T { //当没有占满一个存储单元时,结构体的大小对齐为一个存储单元的大小 unsigned a:2; unsigned b:2; unsigned j:1; unsigned : 1;//可以定义无名位段,此例中该无名位段占用1位的空间,该空间将不被使用 } T; typedef struct _V { unsigned a:1; unsigned b:4; unsigned :0; //定义长度为0的位段时不能指定名字,否则编译不过 unsigned d:1; //定义了0字段后,紧接着的下一个成员从下一个存储单元开始存放; }V; //此例子中,d前面那个存储单元中的余下的27位中被0填充了 int main() { A a; S s; T t; V v; printf("sizeof(a)=%d\n", sizeof(a)); printf("sizeof(s)=%u\nsizeof(t)=%u\n", sizeof(s), sizeof(t)); printf("sizeof(v)=%d\n", sizeof(v)); return 0; }
















 4046
4046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









