







一、DBNs是一个概率生成模型,与传统的判别模型的神经网络相对,用于建立一个观察数据和标签之间的联合分布。
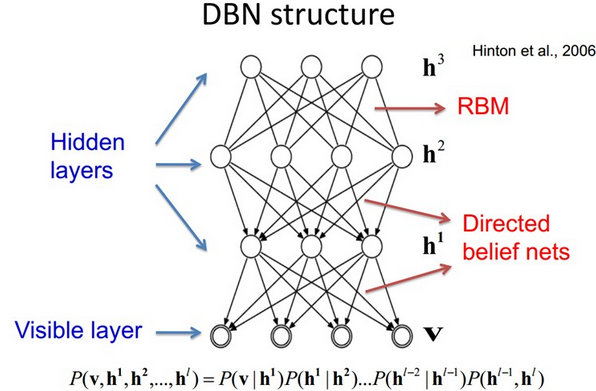
二、DBN的训练
CD(Contrastive Divergence)是log-likelihood gradient的近似算法,同时是a successful update rule for training RBMs,用于训练RBM。
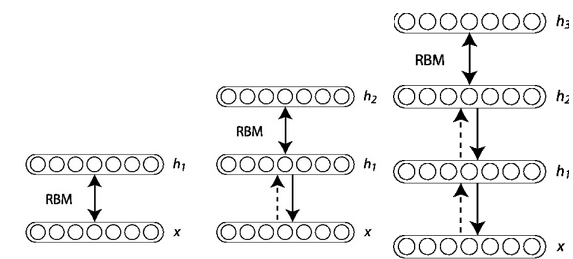
在训练时, Hinton采用了逐层无监督的方法来学习参数。首先把数据向量x和第一层隐藏层作为一个RBM, 训练出这个RBM的参数(连接x和h1的权重, x和h1各个节点的偏置等等), 然后固定这个RBM的参数, 把h1视作可见向量, 把h2视作隐藏向量, 训练第二个RBM, 得到其参数, 然后固定这些参数, 训练h2和h3构成的RBM, 具体的训练算法如下:

CD的训练过程中用到了Gibbs 采样,即在训练过程中,首先将可视向量值映射给隐单元,然后用隐层单元重建可视向量,接着再将可视向量值映射给隐单元……反复执行这种步骤。
k-Gibbs的过程如下:
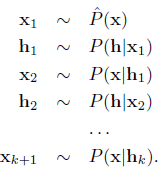
其中,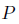 是model distribution,
是model distribution,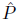 是training set distribution
是training set distribution
是model distribution,是training set distribution
DBN训练算法:

DBN运用CD算法逐层进行训练,得到每一层的参数Wi和ci用于初始化DBN,之后再用监督学习算法对参数进行微调。

三、经典的DBN网络结构
经典的DBN网络结构是由若干层 RBM 和一层 BP 组成的一种深层神经网络, 结构如下图所示.
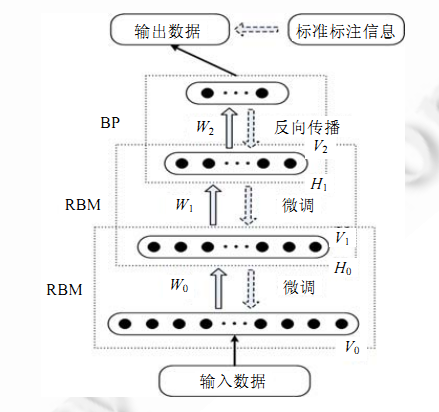
DBN 在训练模型的过程中主要分为两步:
第 1 步:分别单独无监督地训练每一层 RBM 网络,确保特征向量映射到不同特征空间时,都尽可能多地保留特征信息;
第 2 步:在 DBN 的最后一层设置 BP 网络,接收 RBM 的输出特征向量作为它的输入特征向量,有监督地训练实体关系分类器.而且每一层 RBM 网络只能确保自身层内的 权值对该层特征向量映射达到最优,并不是对整个 DBN 的特征向量映射达到最优,所以反向传播网络还将错误信息自顶向下传播至每一层 RBM,微调整个 DBN 网络.RBM 网络训练模型的过程可以看作对一个深层 BP 网络权值参数的初始化,使DBN 克服了 BP 网络因随机初始化权值参数而容易陷入局部最优和训练时间长的缺点.
上述训练模型中第一步在深度学习的术语叫做预训练,第二步叫做微调。最上面有监督学习的那一层,根据具体的应用领域可以换成任何分类器模型,而不必是BP网络。
关于贝叶斯网络“解去”(explaining away)
当我们建立多因一果的BN结构时,如果其中一个原因已经确定了结果的形成,那其他原因就应该忽略。
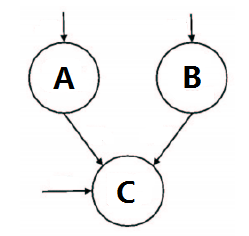
上图为一个简单的BN模型,在我们有任何证据证明C成立之前,A和B是独立的证据。也就是说,改变一个没有影响到其他。但只要我们获得了证据证明C,A的概率变化必然引起B概率相反的变化,反之亦然。它们是相互竞争地解释C的成立.这就是说,只要我们用A把C成立这件事解释过去了,那B作为C的原因也就没有意义了。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









