







文章目录
GPU device内存
https://face2ai.com/CUDA-F-4-1-内存模型概述/
内存种类
一个SM中有一个shared memory,这个时一个block中所有线程都可访问的。
每个线程有自己的local memory和一组寄存器。
所有的block都可以访问一个叫做global memory和一个constant memory(只读),和一个纹理寄存器(只读)。
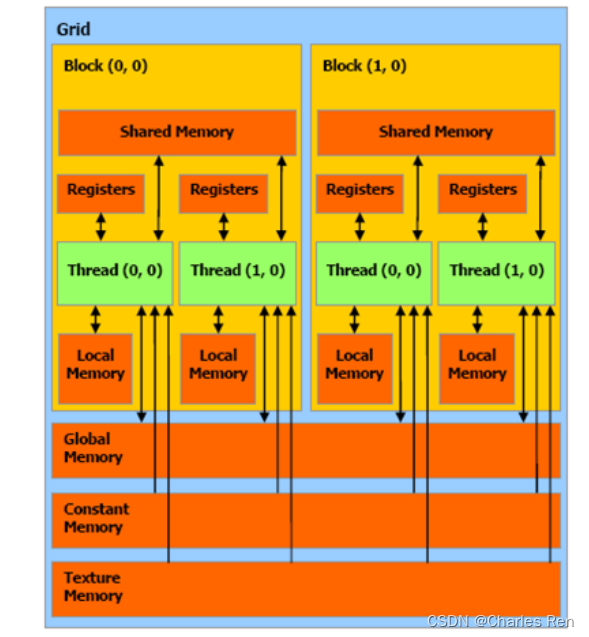

速度从快到慢
- Register file
- Shared Memory
- Constant Memory
- Texture Memory
- Local Memory and Global Memory
不同内存使用方式
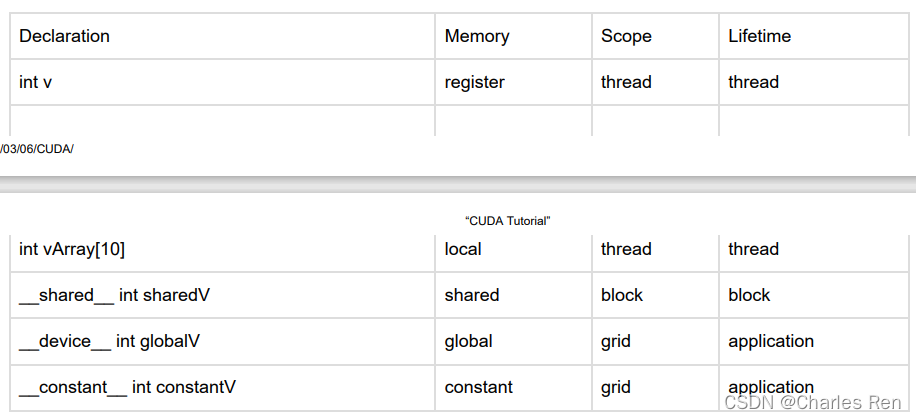
总结:
- 一般我们操作可编程内存常用的时shared_memory和global_memory。声明变量的时候默认是在register,而声明数组默认是在local memory。
- GPU也有缓存,一级二级,这些是不可编程的,硬件决定。texture memory应该也是不可编程的。
Global memory
https://developer.nvidia.com/blog/how-access-global-memory-efficiently-cuda-c-kernels/
声明可以使用__device__标识符
使用cudaMalloc , cudaFree and cudaMemcpy中host to device.
这些操作的都是global meomory。他是常驻DRAM的。
比如下面我们声明后动态赋值
__device__ int globalArray[256];
void foo()
{
...
int *myDeviceMemory = 0;
cudaError_t result = cudaMalloc(&myDeviceMemory, 256 * sizeof(int));
...
}
连续访问与跨越访问global memory
https://blog.csdn.net/Bruce_0712/article/details/65444997
因为对 Global memory 访问没有缓存,因此显存的性能对GPU至关重要。为了能够高效的访问显存,读取和存储必须对齐,宽度为4Byte。如果没有正确的对齐,读写将被编译器拆分为多次操作,极大的影响效率。
每个 thread 一次读取的内存数据量,可以是 32 bits、64 bits、或 128 bits。不过,32 bits 的效率是最好的。64 bits 的效率会稍差,而一次读取 128 bits 的效率则比一次读取 32 bits 要显著来得低(但仍比 non-coalesced 的存取要好)。
每组16 Threads 同时访问连续且对齐的64/128 Byte称为Coalesced访问模式,这是达到带宽的理路峰值的必要条件。
看个例子
template <typename T>
__global__ void offset(T* a, int s)
{
int i = blockDim.x * blockIdx.x + threadIdx.x + s;
a[i] = a[i] + 1;
}
template <typename T>
__global__ void stride(T* a, int s)
{
int i = (blockDim.x * blockIdx.x + threadIdx.x) * s;
a[i] = a[i] + 1;
}
for (int i = 0; i <= 32; i++) {
checkCuda( cudaMemset(d_a, 0, n * sizeof(T)) );
checkCuda( cudaEventRecord(startEvent,0) );
offset<<<n/blockSize, blockSize>>>(d_a, i);
stride<<<n/blockSize, blockSize>>>(d_a, i);
checkCuda( cudaEventRecord(stopEvent,0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
printf("%d, %f\n", i, 2*nMB/ms);
}
我们看到使用这两种方式调用kernel函数唯一区别就是内存的访问方式int i = (blockDim.x * blockIdx.x + threadIdx.x) * s;这里一个是使用内存下标连续访问,而第二种是跳跃访问,运行结果发现
Offset, Bandwidth (GB/s):
0~ 32 均为45.955883左右
Stride, Bandwidth (GB/s):
1, 45.687134
2, 23.113905
3, 15.409269
4, 11.591246
5, 9.256516
6, 7.697044
7, 6.603973
8, 5.765683
9, 5.769941
10, 5.761431
11, 5.723443
12, 5.628603
13, 5.564459
14, 5.410318
15, 5.321867
16, 5.343708
17, 5.170417
18, 5.079649
19, 4.963469
20, 4.985641
21, 4.734848
22, 4.686563
23, 4.526443
24, 4.653068
25, 4.278477
26, 4.273797
27, 4.098898
28, 4.105360
29, 3.809118
30, 3.794317
31, 3.660965
32, 4.018775
可以看到跨越访问在global memeory会损失性能。
但是当我们使用2D数组的时候,就不可避免的会跨越访问,这时,我们可以借助shared Memor处理转置关系来提高性能。
Shared Memory
on chip所以速度非常快,大概是local和globa lmemory的100倍。
shared memory会被分配给每个线程block上,因为block也是在逻辑上分配的,所以shared也是逻辑上分配给每个block。
因为每个block上的不同线程访问同一个block,所以有竞争问题。同步问题可以使用__syncthreads关键字来避免。
举例:
静态共享内存
静态共享内存在创建时候指明大小。
动态共享内存
而动态内存可以不指明大小。
但是在启动kernel函数的时候来指定
dynamicReverse<<<1,n,n*sizeof(int)>>>(d_d, n);
看下面代码例子,对比使用静态共享内存和动态共享内存
#include <stdio.h>
__global__ void staticReverse(int *d, int n)
{
__shared__ int s[1000];
int t = threadIdx.x;
int tr = n-t-1;
//从global memory拷贝写入shared memory
s[t] = d[t];
//因为数组s是所有线程共享的,如果不做同步执行下面语句则可能出现数据竞争问题
// Will not conttinue until all threads completed
//调用同步函数,只有当前block中所有线程都完成之后,再往下走
__syncthreads();
//从shared memory读,然后写回到global memory
d[t] = s[tr];
}
__global__ void dynamicReverse(int *d, int n)
{
extern __shared__ int s[];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
//目的:将一个数组中的数据前后交换,实现倒序
int main(void)
{
const int n = 1000;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++) {
a[i] = i;
r[i] = n-i-1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run version with static shared memory
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
float time_gpu;
cudaEvent_t start_GPU,stop_GPU;
cudaEventCreate(&start_GPU);
cudaEventCreate(&stop_GPU);
cudaEventRecord(start_GPU,0);
staticReverse<<<1,n>>>(d_d, n);
//globalReverse<<<1,n>>>(d_d, n);
cudaEventRecord(stop_GPU,0);
cudaEventSynchronize(start_GPU);
cudaEventSynchronize(stop_GPU);
cudaEventElapsedTime(&time_gpu, start_GPU,stop_GPU);
printf("\nThe time from GPU:\t%f(ms)\n", time_gpu);
cudaDeviceSynchronize();
cudaEventDestroy(start_GPU);
cudaEventDestroy(stop_GPU);
cudaMemcpy(d, d_d, n*sizeof(int), cudaMemcpyDeviceToHost);
//check
for (int i = 0; i < n; i++) {
if (d[i] != r[i])
printf("Error: d[%d]!=r[%d] (%d, %d)\n", i, i, d[i], r[i]);
}
// run dynamic shared memory version
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
cudaEventCreate(&start_GPU);
cudaEventCreate(&stop_GPU);
cudaEventRecord(start_GPU,0);
dynamicReverse<<<1,n,n*sizeof(int)>>>(d_d, n);
cudaEventRecord(stop_GPU,0);
cudaEventSynchronize(start_GPU);
cudaEventSynchronize(stop_GPU);
cudaEventElapsedTime(&time_gpu, start_GPU,stop_GPU);
printf("\nThe time from GPU:\t%f(ms)\n", time_gpu);
cudaDeviceSynchronize();
cudaEventDestroy(start_GPU);
cudaEventDestroy(stop_GPU);
cudaMemcpy(d, d_d, n * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i]) printf("Error: d[%d]!=r[%d] (%d, %d)\n", i, i, d[i], r[i]);
}
__syncthreads() 是轻量级的,并且是以block 级别做同步。
CPU Host内存
对CUDA架构而言,主机端的内存被分为两种,一种是可分页内存(pageable memroy)和页锁定内存(page-locked或 pinned)。
可分页内存 Pageable
可分页内存是使用I malloc()或者new在主机上分配
页锁定内存 Pinned(Page-locked)
页锁定内存是使用CUDA函数cudaMallocHost 或者cudaHostAlloc()在主机内存上分配.
cudaFreeHost()来释放
注意cudaMalloc()是在GPU上分配内存
页锁定内存的重要属性是:主机的操作系统将不会对这块内存进行分页和交换操作,确保该内存始终驻留在物理内存中。
由于每个页锁定内存都需要分配物理内存,并且这些内存不能交换到磁盘上,所以页锁定内存比使用标准malloc()分配的可分页内存更消耗内存空间。
主机端-设备端的数据传输带宽高;某些设备上可以通过zero-copy功能映射到设备地址空间,从GPU直接访问,省掉主存与显存间进行数据拷贝的工作;
pinned memory 不可以分配过多:导致操作系统用于分页的物理内存变少, 导致系统整体性能下降;通常由哪个cpu线程分配,就只有这个线程才有访问权限;
测试
下面我们做个测试:
- host分配可分页内存,然后拷贝到device再拷贝回host,重复执行10次
- host分配页锁定内存,然后拷贝到device再拷贝回host,重复执行10次
- 对比执行时间
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "iostream"
#include <stdio.h>
using namespace std;
#define COPY_COUNTS 10
#define MEM_SIZE 25*1024*1024
float cuda_host_alloc_test(int size, bool up)
{
//耗时统计
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
int *a, *dev_a;
//在主机上分配页锁定内存
cudaError_t cudaStatus = cudaMallocHost((void **)&a, size * sizeof(*a));
//在设备上分配内存空间
cudaStatus = cudaMalloc((void **)&dev_a, size * sizeof(*dev_a));
//计时开始
cudaEventRecord(start, 0);
for (int i = 0; i < COPY_COUNTS; i++)
{
//从主机到设备复制数据
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
//从设备到主机复制数据
cudaStatus = cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaFreeHost(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return (float)elapsedTime / 1000;
}
float cuda_host_Malloc_test(int size, bool up)
{
//耗时统计
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
int *a, *dev_a;
//在主机上分配可分页内存
a = (int*)malloc(size * sizeof(*a));
//在设备上分配内存空间
cudaError_t cudaStatus = cudaMalloc((void **)&dev_a, size * sizeof(*dev_a));
//计时开始
cudaEventRecord(start, 0);
//执行从copy host to device 然后再 device to host执行100次,记录时间
for (int i = 0; i < COPY_COUNTS; i++) {
//从主机到设备复制数据
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
//从设备到主机复制数据
cudaStatus = cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
free(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return (float)elapsedTime / 1000;
}
int main()
{
float allocTime = cuda_host_alloc_test(MEM_SIZE, true);
cout << "页锁定内存: " << allocTime << " s" << endl;
float mallocTime = cuda_host_Malloc_test(MEM_SIZE, true);
cout << "可分页内存: " << mallocTime << " s" << endl;
return 0;
}
chongbin@DESKTOP-SFAMAG4:~/c_project/6memory$ ./a.out
页锁定内存: 0.685681 s
可分页内存: 1.43228 s
可以看到:页锁定内存的访问时间约为可分页内存的访问时间的一半。
总结与建议
-
Pinned内存使用零拷贝,减少内存拷贝到时间,但是不要过分的分配pinned memory。因为这会削减整体系统的性能,他是直接减少物理内存的。所以建议衡量使用pinned meomory和对这个系统的性能,合理使用pinned memory.
-
建议在写代码时先使用pageble memory后面优化的时候再用pinned memory.
-
建议在内存拷贝的时候,将内存分配更多的小份拷贝。比如可以使用
cudaMemcpy2D(dest, dest_pitch, src, src_pitch, w, h, cudaMemcpyHostToDevice)来做二维数组的拷贝。
参考链接:
https://blog.csdn.net/dcrmg/article/details/54975432
https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
















 1727
1727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











