







 系列文章目录文章目录系列文章目录前言一、CUDA内存模型1. 寄存器2. 本地内存3. 共享内存4. 常量内存5. 纹理内存6. 全局内存7. GPU缓存二、静态全局内存示例总结参考资料附录前言最近在温习CUDA C 全局内存的知识,这里对关键知识点进行总结并分享给大家。较差的全局内存访问方式是造成内存负载效率大幅下降的原因之一。这里主要介绍以下几点内容:剖析核函数与全局内存的联系及其对性能的影响;介绍全局内存访问模式介绍如何通过核函数高效的利用全局内存一、CUDA内存
系列文章目录文章目录系列文章目录前言一、CUDA内存模型1. 寄存器2. 本地内存3. 共享内存4. 常量内存5. 纹理内存6. 全局内存7. GPU缓存二、静态全局内存示例总结参考资料附录前言最近在温习CUDA C 全局内存的知识,这里对关键知识点进行总结并分享给大家。较差的全局内存访问方式是造成内存负载效率大幅下降的原因之一。这里主要介绍以下几点内容:剖析核函数与全局内存的联系及其对性能的影响;介绍全局内存访问模式介绍如何通过核函数高效的利用全局内存一、CUDA内存
系列文章目录
文章目录
前言
最近在温习CUDA C 全局内存的知识,这里对关键知识点进行总结并分享给大家。
较差的全局内存访问方式是造成内存负载效率大幅下降的原因之一。
这里主要介绍以下几点内容:
- 剖析核函数与全局内存的联系及其对性能的影响;
- 介绍全局内存访问模式
- 介绍如何通过核函数高效的利用全局内存
一、CUDA内存模型
现代加速器中,内存管理对高性能计算有着极大的影响。
大多数工作负载收到加载和存储速度限制,因此低延迟、高带宽内存对性能十分有利。
CUDA内存模型结合了主机和设备的内存系统,展现了完整的内存层次结构,这样我们可以显式的控制数据布局以达到优化性能的目的。
现代的计算机不断改进低延迟低容量的内存层次结构来优化性能,典型的内存层次结构如下图所示:
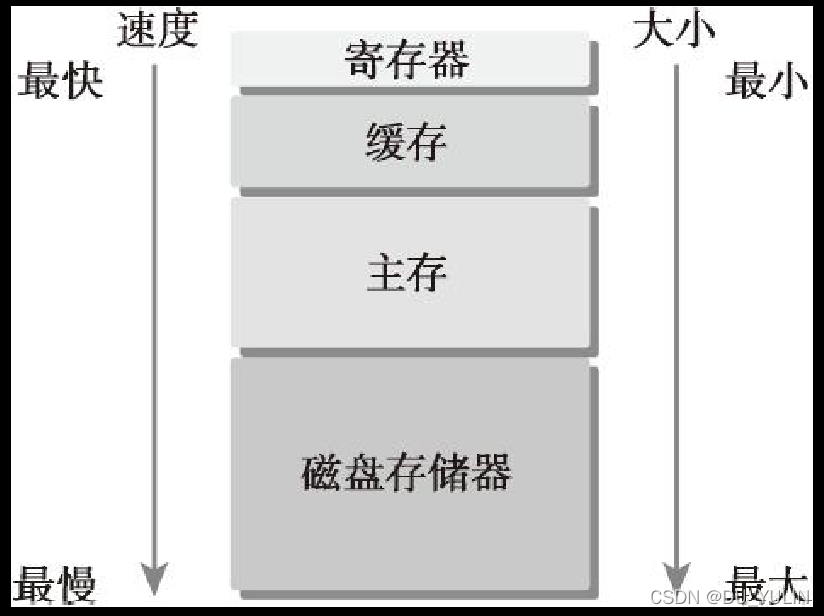 CPU和GPU的主存采用DRAM(动态随机存取存储器),低延迟内存(缓存、寄存器)使用SRAM(静态随机存取存储器)。内存层次结构中最大且最慢的级别通常使用磁盘或闪存驱动来实现。
CPU和GPU的主存采用DRAM(动态随机存取存储器),低延迟内存(缓存、寄存器)使用SRAM(静态随机存取存储器)。内存层次结构中最大且最慢的级别通常使用磁盘或闪存驱动来实现。
如果数据被处理器频繁使用,该数据应该被保存在低延迟、低容量的存储器中;如果数据被存储以备后用,数据就该被存储在高延迟、大容量的存储器中。
GPU和CPU内存模型的主要区别是,CUDA编程模型能将内存层次结构更好的让我们能显示的控制它的行为。
对于我们这种程序猿来说,存储器有两种类型:可编程与不可编程的。
在CPU内存层次结构中,L1和L2缓存是不可编程的;
CUDA内存模型中可编程内存有:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
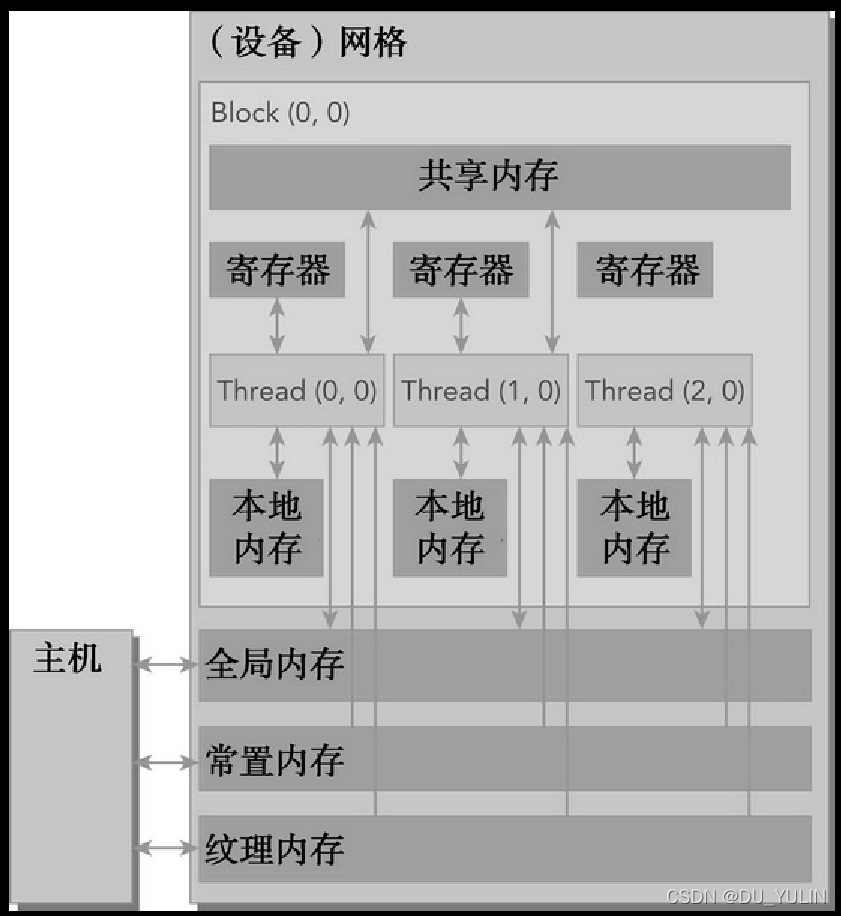 上图中的内存空间的层次结构中,每种都有不同的作用域、生命周期和缓存行为。
上图中的内存空间的层次结构中,每种都有不同的作用域、生命周期和缓存行为。
核函数中的线程有自己私有的本地内存;一个线程块有自己的共享内存,同一线程块中所有线程都可见,内容持续线程块的整个生命周期;所有线程都可以访问全局内存;所有线程都能访问的只读内存空间:常量内存空间和纹理内存空间。
这里需要特别提示的是:纹理内存为各种数据布局提供了不同的寻址模式和滤波模式。
对于一个应用程序,全局内存、常量内存和纹理内存中的内容具有相同的生命周期。
1. 寄存器
寄存器是GPU上运行速度最快的内存空间。
核函数中声明的没有其他修饰符的自变量(个人理解,就是普通的函数内局部变量)通常存储在寄存器中。如果用于引用该数组的索引是常量且能在编译时确定,该数组也存储在寄存器中。
寄存器变量对于每个线程时私有的,核函数通常使用寄存器来保存需要频繁访问的线程私有变量。寄存器变量与核函数的生命周期相同,核函数执行结束,那么就不能对寄存器变量进行访问。
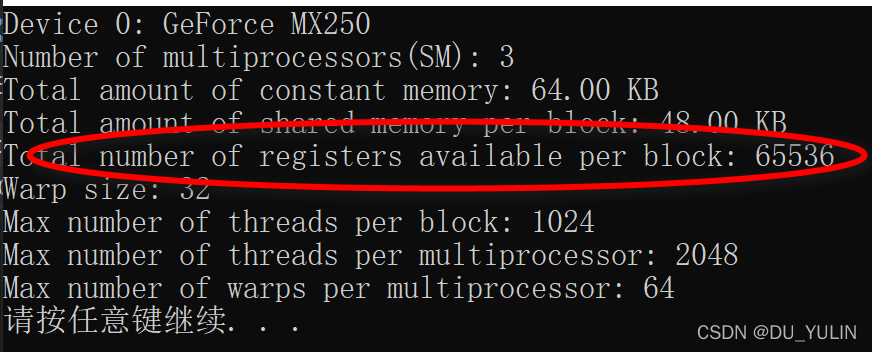
在不同的GPU中,每个线程拥有的寄存器是有限的,本人的超薄本MX250寄存器数量可用如下命令查看:
cudaDeviceProp stDeviceProp;
cudaGetDeviceProperties(&stDeviceProp, nDeviceId);
printf("Total number of registers available per block: %d\n",stDeviceProp.regsPerBlock);
 在核函数使用较少的寄存器,那么在SM上有更多的常驻线程块。每个SM上并发线程块越多,使用率和性能就越高。
在核函数使用较少的寄存器,那么在SM上有更多的常驻线程块。每个SM上并发线程块越多,使用率和性能就越高。
可以使用nvcc编译器选项检查核函数使用的硬件资源,如:寄存器数量,在windows 2017上属性页面设置如下:
 一旦核函数使用超过硬件限制数量的寄存器,则会使用本地内存替代多占用的寄存器。这种寄存器溢出给性能带来不利影响。nvcc编译器使用启发式策略来最小化寄存器使用,以避免寄存器溢出。
一旦核函数使用超过硬件限制数量的寄存器,则会使用本地内存替代多占用的寄存器。这种寄存器溢出给性能带来不利影响。nvcc编译器使用启发式策略来最小化寄存器使用,以避免寄存器溢出。
可以使用maxrregcount编译器选项来控制核函数使用的寄存器最大数量,vs2017配置选项如上图项目属性页面。
2. 本地内存
如上所述,本该进入寄存器但是因空间不足无法进入的变量将溢出到本地内存中。对于计算力在2.0及以上的GPU,本地内存数据存储在每个SM的一级缓存和每个设备的二级缓存中。
3. 共享内存
共享内存存放由修饰符 _ _ s h a r e d _ _ \_\_shared\_\_ __shared__修饰的变量,与本地内存和全局变量相比,它具有更高的带宽和耕地的延迟。类似CPU的一级缓存,它是可编程的。
每个SM有一定数量的由线程块分配的共享内存。同时要注意,必须非常小心并不要过度使用共享内存,否则将不经意间限制活跃线程束的数量。
共享内存在核函数内声明,生命周期与线程块相同。
共享内存是线程块内线程间相互通信的基本方式。访问共享内存需要使用同步方法:
void __syncthreads();
在核函数中调用上面函数,可以避免潜在的数据冲突,但是也会通过频繁强制SM到空闲状态影响性能。
SM中的一级缓存和共享内存可通过如下函数进行动态配置
cudaError_t cudaFuncSetCacheConfig(const void* func, enum cudaFuncCache cacheConfig);
动态配置类型:
enum __device_builtin__ cudaFuncCache
{
cudaFuncCachePreferNone = 0, /**< Default function cache configuration, no preference */
cudaFuncCachePreferShared = 1, /**< Prefer larger shared memory and smaller L1 cache */
cudaFuncCachePreferL1 = 2, /**< Prefer larger L1 cache and smaller shared memory */
cudaFuncCachePreferEqual  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2093
2093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









