









模型
ONNX
ONNX Runtime (ORT) - onnxruntime
[译文]Accelerate your NLP pipelines using Hugging Face Transformers and ONNX Runtime_choose_c的博客-CSDN博客我们将分享ONNX Runtime团队和HuggingFace如何合作,以解决和减少Transformer模型训练和部署中的这些挑战。这是一个简化训练并降低推断成本的解决方案。https://blog.csdn.net/choose_c/article/details/124481697 [译文]Faster and smaller quantized NLP with Hugging Face and ONNX Runtime_choose_c的博客-CSDN博客量化和蒸馏是处理这些尺寸和性能挑战的两种常用技术。这些技术是互补的,可以一起使用。在之前的一篇HuggingFace的博文中讲到了蒸馏。这里我们讨论量化,它可以很容易地应用于您的模型,而无需再训练。这项工作建立在我们之前分享的ONNX Runtime优化推理的基础上,可以为您提供额外的性能提升,以及在客户端设备上解除阻塞推理。
https://blog.csdn.net/choose_c/article/details/124482056
测试
分别测试三个模型:原模型, onnx模型, onnx opt 模型,quantize模型
模型大小:
原模型, onnx模型, onnx opt 模型均为391M。
quantize模型模型大小为100M。模型精度没有进行测试。
CPU
1).单句调用耗时

2).批量调用耗时 batch_size=50
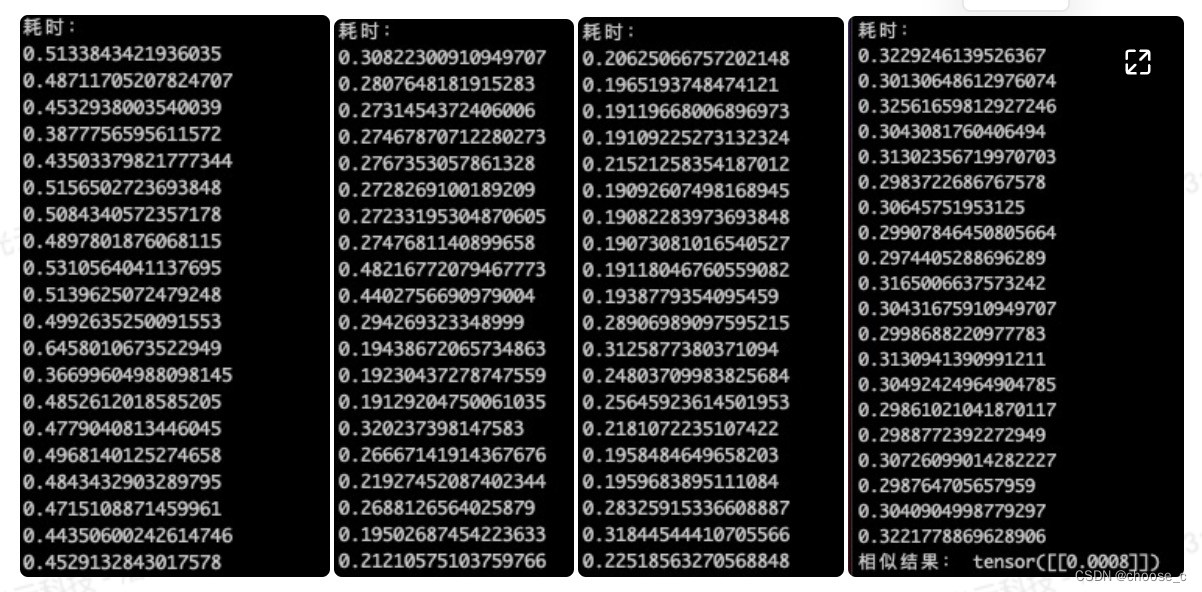 在cpu上进行测试,单句推理时onnx模型调用时间大概为原模型的1/2;进一步优化之后的opt onnx模型时间仅为元模型的1/3。而批量调用时,onnx模型和opt的模型耗时接近,大概为原模型的1/2。量化模型在单句调用上与opt模型效果相近,批量调用耗时略差于onnx和opt模型。
在cpu上进行测试,单句推理时onnx模型调用时间大概为原模型的1/2;进一步优化之后的opt onnx模型时间仅为元模型的1/3。而批量调用时,onnx模型和opt的模型耗时接近,大概为原模型的1/2。量化模型在单句调用上与opt模型效果相近,批量调用耗时略差于onnx和opt模型。
GPU
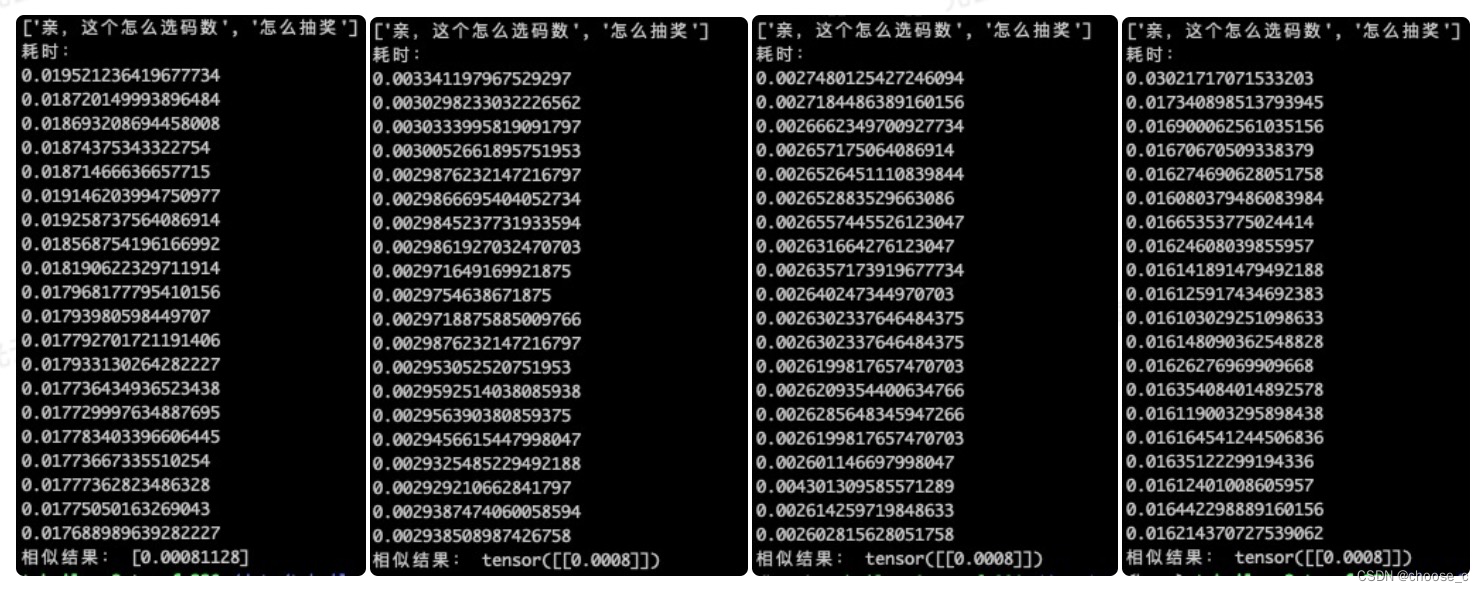
1).单句调用
2).批量调用 batch_size=50
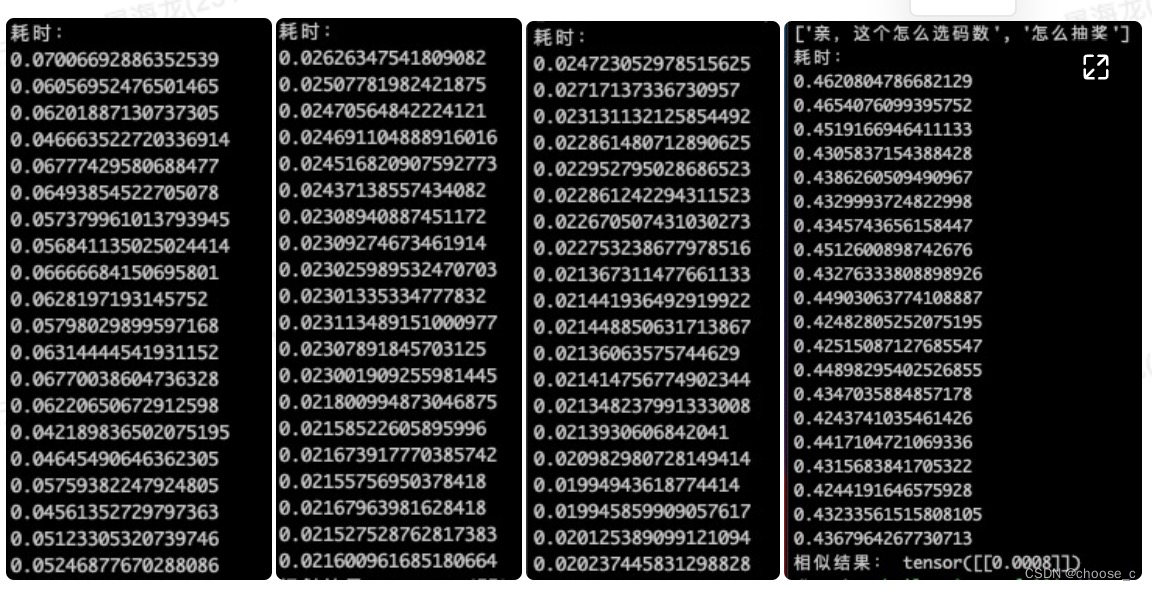
在gpu上测试,单句测试时,onnx模型耗时为元模型的1/6,opt模型比onnx模型耗时更少但差距不大。批量测试中,onnx耗时为元模型的1/2,同样opt模型和onnx模型差距不大。但是量化模型不管在单句还是批量的测试中都远远差于其他模型(原因:量化后的模型想要在NV的GPU上inference,必须要通过TensorRT;原生的pytorch量化后只能在CPU上跑。TensorRT带的Pytorch量化工具包,量化后转成ONNX可以在NV-GPU上跑;原生TF量化后的模型,只能用TF-LITE在移动端跑)。
若有收获,就点个赞吧















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









