







论文title:https://arxiv.org/pdf/2205.12035RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
论文链接:https://arxiv.org/pdf/2205.12035
摘要
1.一种新的MAE工作流,编码器和解器输入进行了不同的掩码。编码器编码的句子向量和解码器的掩码输入通过语言模型进行重构问句。
2.非对称的模型结构,编码器拥有像BERT一样全尺寸的transformer,解码器只有一层的transformer。
3.非对称的掩码比例,编码器:15%-30%,解码器:50%-70%。
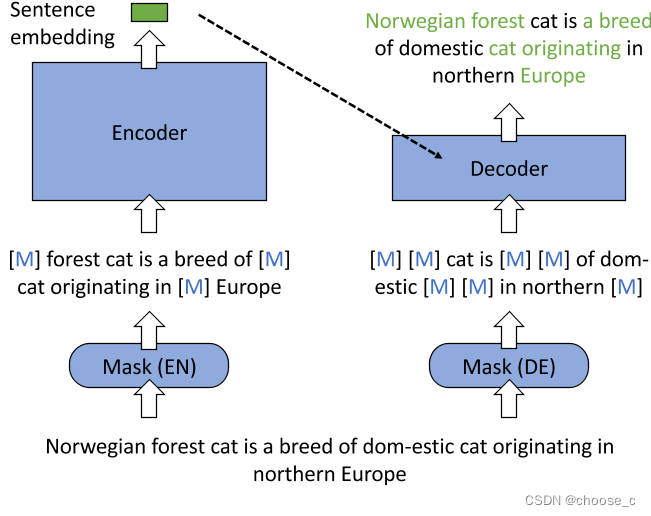
retroMAE这样设计的原因:
1.auto-encoding对于编码质量的要求更高,传统的自回归更关注前缀,传统的MLM只掩盖一小部(15%)的输入。retroMAE掩盖了更多的输入用于解码,因此重构不仅依赖解码器的输入,更加取决于句子嵌入,所以它迫使编码器捕捉更深层次的句子语义。
2.保证了训练信号来自于大多数的句子输入。另外解码器只有一层transformer,所以使用了双流注意力和特定位置注意掩码的增强解码。这样所有token都被用于了重建。
方法
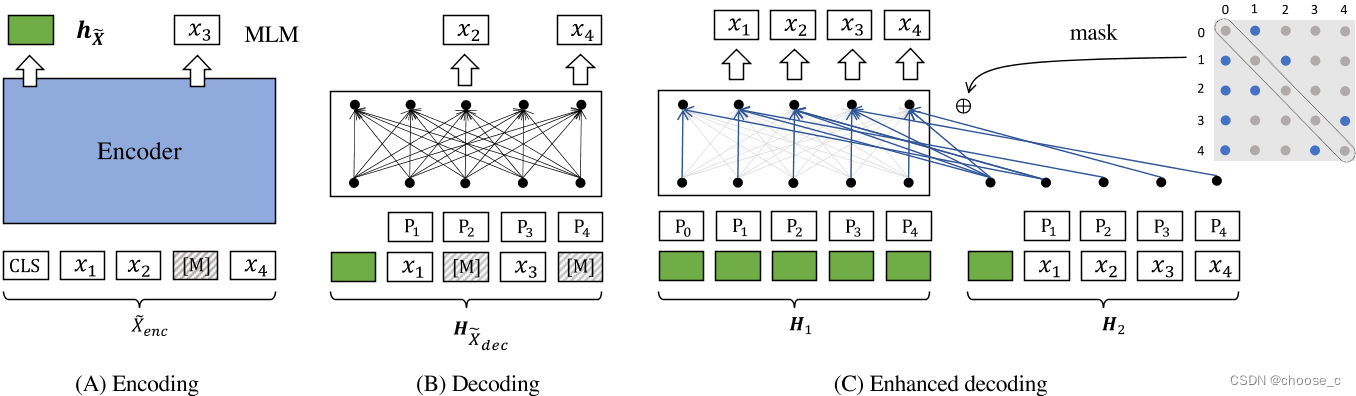
编码器
编码器使用像bert一样12层transformer和768维度的向量输出,能够很好地捕捉句子的深层语义。问句输入中token的掩码比例为15%-30%,最终使用 [CLS]token的向量作为句子的嵌入表示。
解码器
解码器的结构为一层transformer,它的句子输入中token的掩码比例为50%-70%,会将编码器生成的嵌入向量和掩码token(位置编码)连接输入解码器。由于解码器的transformer层数较浅,句子掩码比例又高,所以重构任务更加依赖于编码器生成高质量的嵌入向量。
增强解码
解码过程的一个限制是训练信号,即交叉熵损失,只能从掩码标记导出。此外,每个掩码标记总是基于相同的上下文重构。所以解码增强希望1.从句子中获得更多的训练信号。2.重建任务可以基于更多样的上下文。所以提出了双流注意力和特定位置注意掩码的增强解码。

















 4460
4460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









