







1.概述
许多机器学习和深度学习模型都是在基于 Python 的框架中开发和训练的,例如 PyTorch 和 TensorFlow 等。但是,当需要将这些训练好模型部署到生产环境中时,通常会希望将模型集成到生产流程中,而这些流程大多是用 C++ 编写的,因为 C++ 可以提供更快的实时性能。
目前有许多工具和框架可以帮助我们将预训练模型部署到 C++ 应用程序中。例如,ONNX Runtime 可用于边缘计算和服务器环境,NCNN 和 MNN 适用于移动设备,而 TensorRT 则适用于 Nvidia 的嵌入式平台。这里,通过一个完整的端到端示例来讨论如何利用 ONNX Runtime(GPU 版本)将一个预训练的 PyTorch 模型部署到 C++ 应用程序中。
这种部署方式不仅可以帮助开发者利用 C++ 的高效性能,还可以通过 ONNX Runtime 灵活地使用不同的硬件加速器,如 CPU、CUDA 或 TensorRT 等。通过这种方式,可以在保持应用程序性能的同时,快速集成和部署机器学习和深度学习模型。
2.onnx介绍
ONNX是一个为机器学习设计的开放文件格式,它被用来存储预训练的模型。ONNX 的主要目的是促进不同人工智能框架之间的互操作性,使得模型可以在这些框架之间轻松迁移和部署。这种格式支持统一的模型表示,因此,不同的训练框架,比如 Caffe2、PyTorch、TensorFlow 等,都可以使用相同的格式来存储模型数据,进而实现数据的交互和共享。
ONNX 的规范和代码主要由一些科技巨头公司开发,包括但不限于 Microsoft(微软)、Amazon(亚马逊)、Facebook(脸书)和 IBM。这些公司的贡献确保了 ONNX 作为一个开放标准能够持续发展,并且得到了业界的广泛支持和应用。
通过使用 ONNX,开发者可以更加灵活地选择适合自己项目的 AI 框架,而不必担心框架间的兼容性问题。此外,ONNX 也为模型的优化和加速提供了可能,因为它可以与各种硬件后端(如 CPU、GPU、TPU 等)配合工作,从而提高模型运行的效率。
3. ONNX Runtime介绍
ONNX Runtime 是一个跨平台的机器学习模型加速器,它提供了一个灵活的接口,允许集成针对特定硬件优化的库。这意味着 ONNX Runtime 可以适配多种硬件环境,并且能够充分利用硬件的特性来加速模型的执行。
ONNX Runtime 支持多种执行提供者,包括:
- CPU:作为通用处理器,CPU 是执行机器学习模型的一个常见选择。
- CUDA:NVIDIA 的 CUDA 为使用 NVIDIA GPU 加速提供了接口,可以显著提升模型在支持 CUDA 的 GPU 上运行的性能。
除了能够利用不同的执行提供者外,ONNX Runtime 还能够与多个框架训练的模型一起使用,这些框架包括但不限于:
- PyTorch:一个流行的开源机器学习库,广泛用于计算机视觉和自然语言处理任务。
- TensorFlow/Keras:Google 开发的 TensorFlow 是一个强大的机器学习平台,Keras 是其上的高级神经网络 API。
- TFLite:TensorFlow 的轻量级解决方案,专门用于移动和嵌入式设备。
- scikit-learn:一个简单高效的 Python 编程库,用于数据挖掘和数据分析。
通过 ONNX Runtime 的推理功能,开发者可以轻松地将预训练的 PyTorch 模型部署到 C++ 应用程序中。这使得在需要高性能和实时处理的生产环境中,利用机器学习模型成为可能。通过这种方式,开发者可以享受到 C++ 的性能优势,同时又能通过 ONNX Runtime 灵活地部署和运行各种机器学习模型。
4. 模型转换与依赖安装
Pytorch模型转onnx并推理的步骤如下:
模型转换:首先,需要将 PyTorch 预训练模型文件(可以是 .pth 或 .pt 格式)转换成 ONNX 格式的文件(.onnx 格式)。这一转换过程在 PyTorch 环境中进行。
使用 ONNX Runtime:转换得到的 .onnx 文件随后作为输入,被用于 C++ 应用程序中。在这个应用程序中,调用 ONNX Runtime 的 C++ API 来执行模型的推理。
这个流程允许开发者利用 PyTorch 强大的训练能力来训练模型,并将训练好的模型通过 ONNX 这一开放格式,部署到 C++ 环境中,从而在多种不同的平台上实现高性能的推理计算。通过这种方式,开发者可以兼顾模型的开发效率和部署时的性能要求。
4.1 PyTorch 模型转换到 ONNX
为了演示方便,这里使用Yolov8的一个人脸检测的模型进行演示,首先安装ultralytics框架:
conda create --name yolov8 python==3.10
conda activate yolov8
pip install ultralytics
然后把模型好的.pt模型转成onnx模型,转换代码如下:
from ultralytics import YOLO
model = YOLO("yolov8n_face.pt")
success = model.export(format="onnx", simplify=True) # export the model to onnx format
assert success
print("转换成功")
运行之后之后成功一个同名的onnx模型。
4.2 安装GPU依赖库
A: 我这里的测试环境是Win10,IDE 是VS2019,显卡是NVIDIA GeForce RTX 2070 SUPER ,8G的显存,cuda 是11.7,cudnn是8.5。
首先要安装cuda 11.7,从官网下载cudu 11.7 win10对应的版本:


B: 安装的时候按指示下一步下一步就可以了:

C: 指示安装,安装完成之后,在所先的安装路径上可以看到:

D: 并且它会自动把需要的路径加到系统环境变量:

E: 下载cudnn:
可以从官方下载到所指定的cudnn版本:

F: 下载完成之后,解压出三个目录,把三个目录复制一份放到上面C图所在的路径,该路径原本就存有相同的目录,直接粘贴就可以:

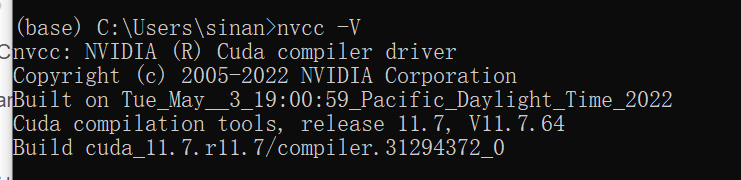
G: 启动命令行,输入nvcc -V,检查是否安装成功,如出现下面的提示表示安装成功,否则请重新检查以上的步骤是否正确:
4.3 安装编程所需的依赖库
4.3.1 ONNX Runtime下载
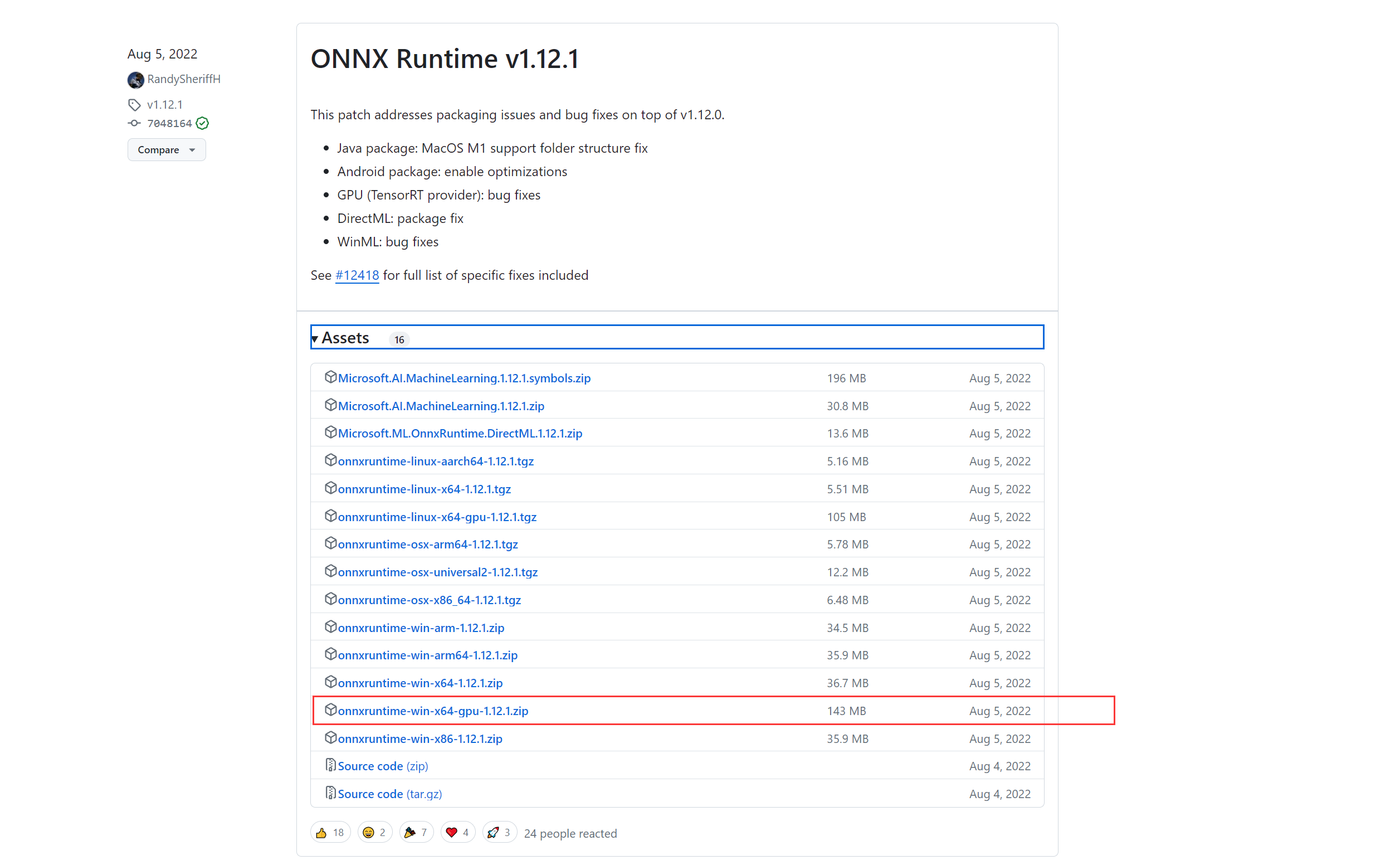
可以从https://github.com/microsoft/onnxruntime/releases下载到编译好的依赖库,这里的演示环境是Win10, IDE是vs2019,我下载v1.12.1 GPU这个版本。
4.3.2 OpenCV库
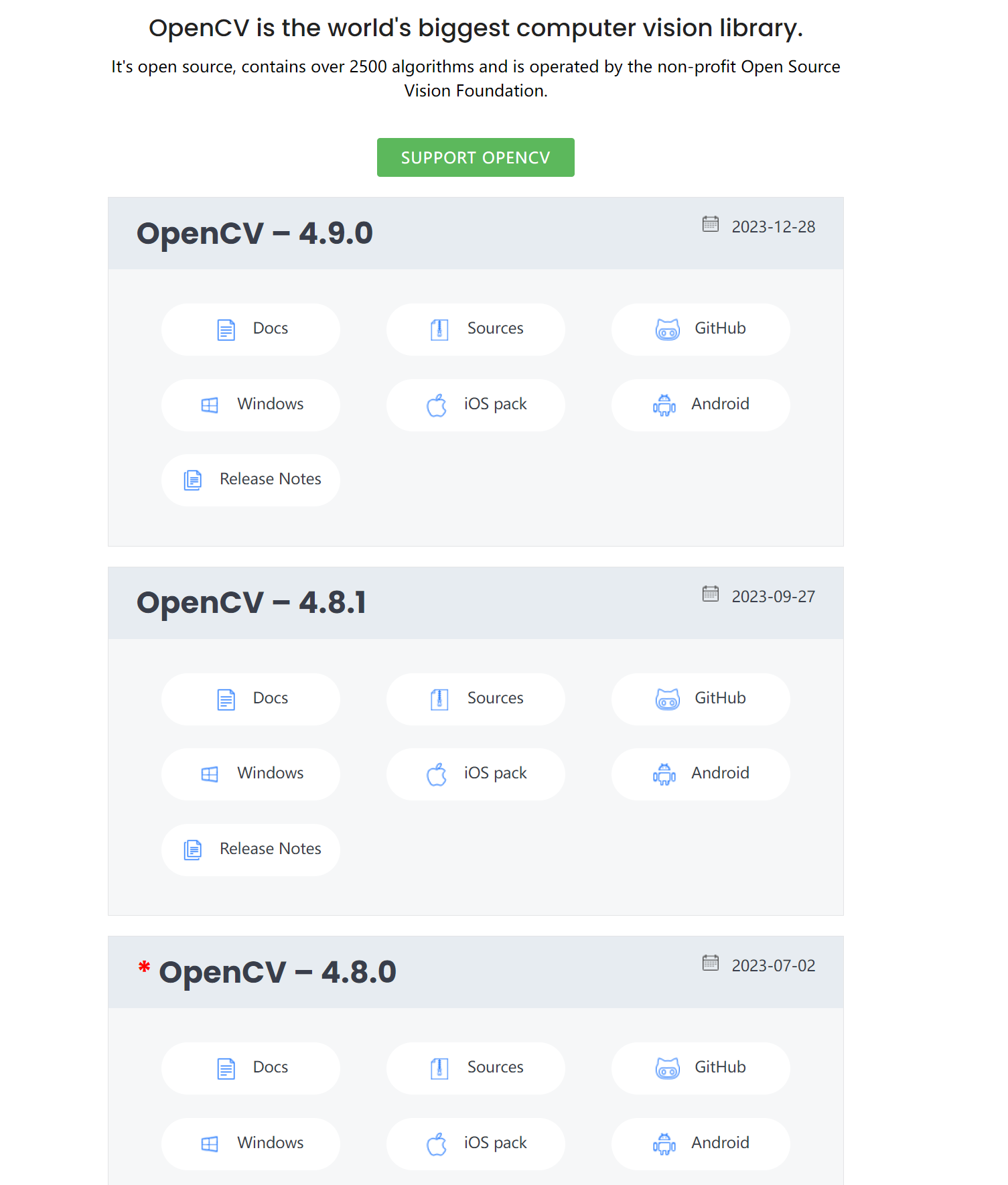
因为使用的模型需要显示出效果图,这里使用OpenCV来做图像预处理相关的操作,可以从OpenCV官网下载到所需的库:
5.使用 ONNX Runtime 进行推理
5.1 创建工程
A: 使用vs2019创建一个C++工程,然后把OnnxRuntime和OpenCV加到工程里面:

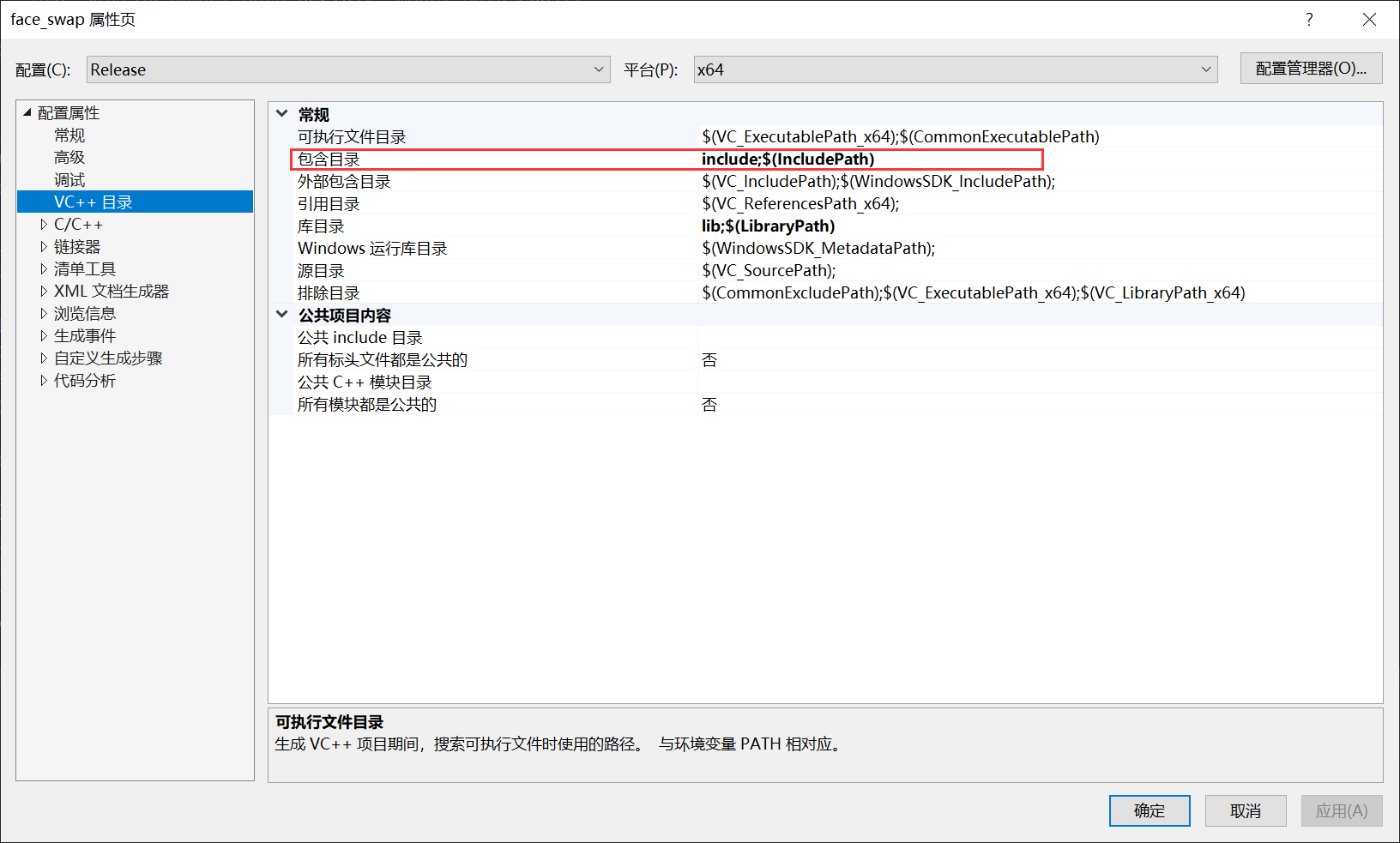
B: 把OnnxRuntime和OpenCV加入到工程包含路径,路径里面包含OnnxRuntime和OpenCV的头文件:

添加到目录:
C: 把lib添加到库目录,lib包含到OnnxRuntime和OpenCV 的lib文件:
把lib路径加到库目录:
把lib文件名添加到链接器:
5.2 ONNX Runtime推理流程
5.2.1 推理流程:
初始化 ONNX Runtime 环境:
- 首先,你需要初始化 ONNX Runtime 的运行时环境。这通常涉及到创建一个
Ort::Env对象,它包含了线程池和其他运行时设置。 - 设置会话选项:
- 接着,设置 ONNX Runtime 会话的选项。这可能包括配置 GPU 使用、优化器级别、执行模式等。
- 加载模型并创建会话:
- 加载预训练的 ONNX 模型文件。
- 使用运行时环境、会话选项和模型创建一个
Ort::Session对象。 - 获取模型输入输出信息:
- 从
Ort::Session对象中获取模型输入和输出的详细信息,包括数量、名称、类型和形状。 - 推理准备:
- 创建输入和输出张量,这些张量是用于存储推理数据的内存块。
- 分配内存给这些张量,以准备数据输入。
- 执行推理:
- 调用
Ort::Session::Run方法,传入输入张量、输出张量和其他必要的参数,执行推理。 - 后处理推理结果:
- 推理完成后,从输出张量中获取结果数据。
- 根据需要对结果进行后处理,比如解码、格式化等,以获得最终的预测结果。
5.2 ONNX Runtime推理代码
类的头文件:
# ifndef YOLOV8FACE
# define YOLOV8FACE
#include <fstream>
#include <sstream>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
#include <provider_options.h>
#include <onnxruntime_cxx_api.h>
#include "utils.h"
class Yolov8Face
{
public:
Yolov8Face(std::string modelpath, const float conf_thres=0.5, const float iou_thresh=0.4);
void detect(cv::Mat srcimg, std::vector<Bbox> &boxes);
private:
void preprocess(cv::Mat img);
std::vector<float> input_image;
int input_height;
int input_width;
float ratio_height;
float ratio_width;
float conf_threshold;
float iou_threshold;
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "Face Detect");
Ort::Session *ort_session = nullptr;
Ort::SessionOptions sessionOptions = Ort::SessionOptions();
std::vector<char*> input_names;
std::vector<char*> output_names;
std::vector<std::vector<int64_t>> input_node_dims; // >=1 outputs
std::vector<std::vector<int64_t>> output_node_dims; // >=1 outputs
Ort::MemoryInfo memory_info_handler = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
};
#endif
类的实现文件:
// 构造函数,用于初始化 YOLOv8Face 类的实例
Yolov8Face::Yolov8Face(string model_path, const float conf_thres, const float iou_thresh)
{
// 设置执行提供者为 CUDA,并添加到会话选项中
OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0);
// 设置图优化级别为最高级别
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
// 将字符串路径转换为宽字符串,用于创建会话
std::wstring widestr = std::wstring(model_path.begin(), model_path.end());
ort_session = new Session(env, widestr.c_str(), sessionOptions);
// 如果是Linux,则用以下的方式
// ort_session = new Session(env, model_path.c_str(), sessionOptions);
// 获取输入和输出节点的数量
size_t numInputNodes = ort_session->GetInputCount();
size_t numOutputNodes = ort_session->GetOutputCount();
// 创建默认分配器
AllocatorWithDefaultOptions allocator;
// 获取输入节点的名称和维度信息
for (int i = 0; i < numInputNodes; i++)
{
input_names.push_back(ort_session->GetInputName(i, allocator));
// 新版本的Onnx Runtime使用的接口
// AllocatedStringPtr input_name_Ptr = ort_session->GetInputNameAllocated(i, allocator);
// input_names.push_back(input_name_Ptr.get());
Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_node_dims.push_back(input_dims);
}
// 获取输出节点的名称和维度信息
for (int i = 0; i < numOutputNodes; i++)
{
output_names.push_back(ort_session->GetOutputName(i, allocator));
// 新版本的Onnx Runtime使用的接口
// AllocatedStringPtr output_name_Ptr= ort_session->GetInputNameAllocated(i, allocator);
// output_names.push_back(output_name_Ptr.get());
Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_node_dims.push_back(output_dims);
}
// 从输入节点维度中获取输入图像的高度和宽度
this->input_height = input_node_dims[0][2];
this->input_width = input_node_dims[0][3];
// 设置置信度阈值和 IOU 阈值
this->conf_threshold = conf_thres;
this->iou_threshold = iou_thresh;
}
// 对输入图像进行预处理
void Yolov8Face::preprocess(Mat srcimg)
{
// 获取原始图像的高度和宽度
const int height = srcimg.rows;
const int width = srcimg.cols;
// 创建临时图像副本
Mat temp_image = srcimg.clone();
// 如果图像的高度或宽度大于输入尺寸,则进行缩放
if (height > this->input_height || width > this->input_width)
{
const float scale = std::min((float)this->input_height / height, (float)this->input_width / width);
Size new_size = Size(int(width * scale), int(height * scale));
resize(srcimg, temp_image, new_size);
}
// 计算比例因子,用于将检测框映射回原始图像尺寸
this->ratio_height = (float)height / temp_image.rows;
this->ratio_width = (float)width / temp_image.cols;
// 创建输入图像,如果必要的话,使用 copyMakeBorder 来填充边缘
Mat input_img;
copyMakeBorder(temp_image, input_img, 0, this->input_height - temp_image.rows, 0, this->input_width - temp_image.cols, BORDER_CONSTANT, 0);
// 分离图像的 BGR 通道
vector<cv::Mat> bgrChannels(3);
split(input_img, bgrChannels);
// 将每个通道的数据类型转换为 float,并进行归一化
for (int c = 0; c < 3; c++)
{
bgrChannels[c].convertTo(bgrChannels[c], CV_32FC1, 1 / 128.0, -127.5 / 128.0);
}
// 将所有通道的数据复制到一个连续的数组中
const int image_area = this->input_height * this->input_width;
this->input_image.resize(3 * image_area);
size_t single_chn_size = image_area * sizeof(float);
memcpy(this->input_image.data(), (float *)bgrChannels[0].data, single_chn_size);
memcpy(this->input_image.data() + image_area, (float *)bgrChannels[1].data, single_chn_size);
memcpy(this->input_image.data() + image_area * 2, (float *)bgrChannels[2].data, single_chn_size);
}
// 执行目标检测
void Yolov8Face::detect(Mat srcimg, std::vector<Bbox> &boxes)
{
// 对输入图像进行预处理
this->preprocess(srcimg);
// 设置输入张量的形状
std::vector<int64_t> input_img_shape = {1, 3, this->input_height, this->input_width};
// 创建输入张量,并分配内存
Value input_tensor_ = Value::CreateTensor<float>(memory_info_handler, this->input_image.data(), this->input_image.size(), input_img_shape.data(), input_img_shape.size());
// 设置运行选项
Ort::RunOptions runOptions;
// 运行推理,获取输出结果
vector<Value> ort_outputs = this->ort_session->Run(runOptions, this->input_names.data(), &input_tensor_, 1, this->output_names.data(), output_names.size());
// 获取第一个输出张量的数据指针
float *pdata = ort_outputs[0].GetTensorMutableData<float>();
// 获取输出张量中的检测框数量
const int num_box = ort_outputs[0].GetTensorTypeAndShapeInfo().GetShape()[2];
// 存储原始检测框和得分
vector<Bbox> bounding_box_raw;
vector<float> score_raw;
for (int i = 0; i < num_box; i++)
{
const float score = pdata[4 * num_box + i];
if (score > this->conf_threshold)
{
// 将检测框的坐标从归一化映射到原始图像尺寸
float xmin = (pdata[i] - 0.5 * pdata[2 * num_box + i]) * this->ratio_width;
float ymin = (pdata[num_box + i] - 0.5 * pdata[3 * num_box + i]) * this->ratio_height;
float xmax = (pdata[i] + 0.5 * pdata[2 * num_box + i]) * this->ratio_width;
float ymax = (pdata[num_box + i] + 0.5 * pdata[3 * num_box + i]) * this->ratio_height;
bounding_box_raw.emplace_back(Bbox{xmin, ymin, xmax, ymax});
score_raw.emplace_back(score);
}
}
// 使用非极大值抑制(NMS)算法去除重叠的检测框
vector<int> keep_inds = nms(bounding_box_raw, score_raw, this->iou_threshold);
// 获取保留的检测框数量
const int keep_num = keep_inds.size();
// 清空输出向量并设置为保留的检测框数量
boxes.clear();
boxes.resize(keep_num);
// 将保留的检测框复制到输出向量中
for (int i = 0; i < keep_num; i++)
{
const int ind = keep_inds[i];
boxes[i] = bounding_box_raw[ind];
}
}
5.3 代码解释
5.3.1 选择GPU推理
// 设置执行提供者为 CUDA,并添加到会话选项中,这里选择第一块GPU
OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0);
// 设置图优化级别为最高级别,这里使用最大优化
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
sessionOptions.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
5.3.2 获取输入层
// 获取输入节点的名称和维度信息
for (int i = 0; i < numInputNodes; i++)
{
input_names.push_back(ort_session->GetInputName(i, allocator));
// 新版本的Onnx Runtime使用的接口
// AllocatedStringPtr input_name_Ptr = ort_session->GetInputNameAllocated(i, allocator);
// input_names.push_back(input_name_Ptr.get());
Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_node_dims.push_back(input_dims);
}
可以使用可视化看到模型输入层:

5.3.3 获取输出层
// 获取输出节点的名称和维度信息
for (int i = 0; i < numOutputNodes; i++)
{
output_names.push_back(ort_session->GetOutputName(i, allocator));
// 新版本的Onnx Runtime使用的接口
// AllocatedStringPtr output_name_Ptr= ort_session->GetInputNameAllocated(i, allocator);
// output_names.push_back(output_name_Ptr.get());
Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_node_dims.push_back(output_dims);
}
可以使用可视化看到模型输出层:

5.4 使用CPU进行推理
注释掉调用GPU部分,运行代码,计算运行时间,可以看到每张图运行速度如下:

5.5 使用GPU进行推理
作用GPU推理设置参数如下:
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
- ORT_DISABLE_ALL:禁用所有图优化。
- ORT_ENABLE_BASIC:启用基本的图优化。
- ORT_ENABLE_EXTENDED:启用扩展的图优化,这通常包括基本优化加上一些更激进的优化策略,可能会提高模型的执行速度,但也可
能需要更多的时间来优化图。
使用GPU推理,运行代码,计算运行时间,可以看到每张图运行速度如下:
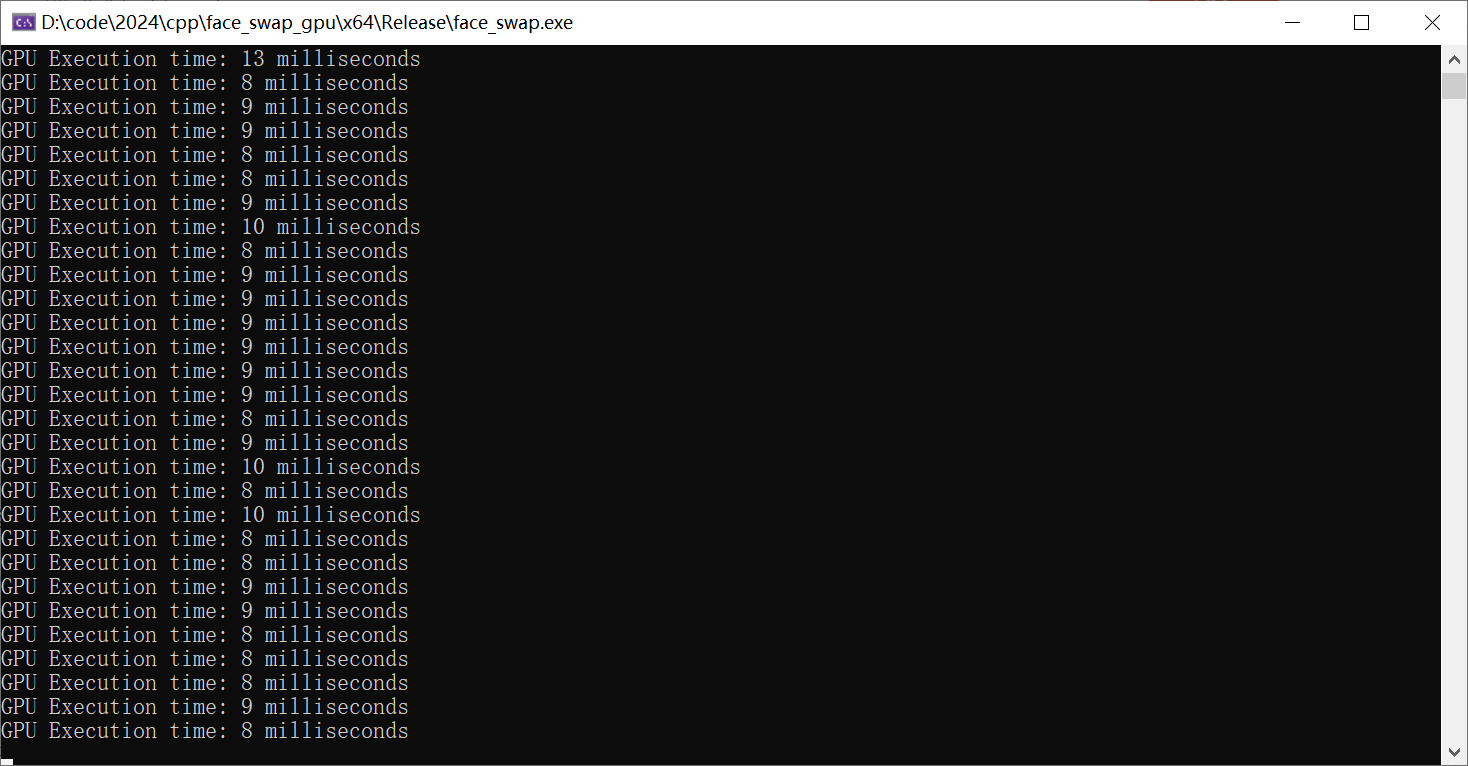
可以打开资源管理器看GPU的使用情况:

6.总结
以上就是在win 10下使用Onnx Runtime用CPU与GPU来对onnx模型进行推理部署的对比,可以明显的看出来,使用GPU之后的推理速度,但在正式的大型项目中,在win下使用GPU部署模型是不建议,一般都会选择Linux,那样对GPU的利用率会高出不少,毕竟蚊腿肉也是肉。



















 2768
2768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











