






http://blog.csdn.net/pipisorry/article/details/52135832
深度学习最优化算法
动量Momentum
如果把要优化的目标函数看成山谷的话,可以把要优化的参数看成滚下山的石头,参数随机化为一个随机数可以看做在山谷的某个位置以0速度开始往下滚。目标函数的梯度可以看做给石头施加的力,由力学定律知: F=m∗a ,所以梯度(施加的力)与石头下滚的加速度成正比。因而,梯度直接影响速度,速度的累加得到石头的位置,对这个物理过程进行建模,可以得到参数更新过程为:
vt=γvt−1+η∇θJ(θ) .
θ=θ−vt .

启发式算法:物体的动能 = 上一个时刻的动能 + 上一时刻的势能差(相对于单位质量),当前的速度取决于上一个时刻的速度和势能的改变量。由于有阻力和转换时的损失,所以两者都乘以一个系数。
这样在更新参数时,除了考虑到梯度以外,还考虑了上一个时刻参数的历史变更幅度。如果参数上一次更新幅度较大,并且梯度还不小,那么再更新时也应该很猛烈。
# Momentum update
v = momentum * v - learning_rate * dx # integrate velocity
x += v # integrate position代码中v指代速度,其计算过程中有一个超参数momentum,称为动量(momentum)。虽然名字为动量,其物理意义更接近于摩擦,其可以降低速度值,降低了系统的动能,防止石头在山谷的最底部不能停止情况的发生(除非momentum为0,不然还是停不下来的,可能通过NAG解决)。
动量的取值范围通常为[0.5, 0.9, 0.95, 0.99],一种常见的做法是在迭代开始时将其设为0.5,在一定的迭代次数(epoch)后,将其值更新为0.99
在实践中,一般采用SGD+momentum的配置,相比普通的SGD方法,这种配置通常能极大地加快收敛速度。faster convergence and reduced oscillation振荡。
Nesterov accelerated gradient(NAG)
还是以上面小球的例子来看,momentum方式下小球完全是一种盲目被动的方式滚下的。这样有个缺点就是在临近最优点附近控制不住速度(梯度为0了,但是moment不为0,还是有速度,还会运动)。我们希望小球很smart,它可以预判后面的"地形",要是后面地形还是很陡,那就继续坚定不移的大胆走下去;不然的话咱就收敛点~当然,小球自己也不知道真正要走到哪里,所以这里以 (θ−γv_{t−1} )作为近似下一位置。
θ=θ−vt .
Hinton的slides是这样给出的:
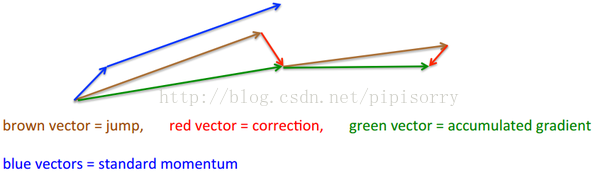
两个blue vectors分别理解为梯度和动能,两个向量和即为momentum方式的作用结果。
而靠左边的brown vector是动能,可以看出它那条blue vector是平行的,但是它预测了下一阶段的梯度是red vector,因此向量和就是green vector,即NAG方式的作用结果。
Adagrad
"It adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters."因此,Adagrad对于稀疏数据上有着良好的表现。
之前所讲的方法中所有参数在更新时均使用同一个learning rate,而在Adagrad的每一个参数的每一次更新中都使用不同的learning rate。
之前第t步更新时对第i个参数的梯度为: gt,i=∇θJ(θi) .
参数的更新的一般形式为: θt+1,i=θt,i−η⋅gt,i .
如上所述,Adagrad的差异之处正是在于learning rate不同于其他,将learning rate改为如下:
θt+1,i=θt,i−ηGt,ii+ϵ‾‾‾‾‾‾‾‾√⋅gt,i .这里的Gt是一个d*d维对角矩阵,对角线上的元素(i,i)表示在第t步更新时,历史上θi梯度平方和的积累。ϵ只是一个值很小的防止分母为0的平滑项。
然而如文中之前说明一般大多数自适应的learning rate都是有根据变化幅度而更改,并且具有逐渐收敛的特性。所以这种启发式方法仅是一种可行性方式,并不是唯一的,也绝不是最好的。把握其本质即可。
[深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)]
启发式优化方法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
这部分的内容会在之后的博文中进行详细总结,敬请期待。这部分内容的介绍已经在博客《[Evolutionary Algorithm] 进化算法简介》进行了概要式的介绍,有兴趣的博友可以进行参考(2015.12.13)。
from: http://blog.csdn.net/pipisorry/article/details/52135832
ref:















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









